 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuseAgent-1: Interactive Grounded Multimodal Understanding of Music Scores and Performance Audio
Jan 17, 2026Despite recent advances in multimodal large language models (MLLMs), their ability to understand and interact with music remains limited. Music understanding requires grounded reasoning over symbolic scores and expressive performance audio, which general-purpose MLLMs often fail to handle due to insufficient perceptual grounding. We introduce MuseAgent, a music-centric multimodal agent that augments language models with structured symbolic representations derived from sheet music images and performance audio. By integrating optical music recognition and automatic music transcription modules, MuseAgent enables multi-step reasoning and interaction over fine-grained musical content. To systematically evaluate music understanding capabilities, we further propose MuseBench, a benchmark covering music theory reasoning, score interpretation, and performance-level analysis across text, image, and audio modalities. Experiments show that existing MLLMs perform poorly on these tasks, while MuseAgent achieves substantial improvements, highlighting the importance of structured multimodal grounding for interactive music understanding.
PEACE: Empowering Geologic Map Holistic Understanding with MLLMs
Jan 10, 2025



Geologic map, as a fundamental diagram in geology science, provides critical insights into the structure and composition of Earth's subsurface and surface. These maps are indispensable in various fields, including disaster detection, resource exploration, and civil engineering. Despite their significance, current Multimodal Large Language Models (MLLMs) often fall short in geologic map understanding. This gap is primarily due to the challenging nature of cartographic generalization, which involves handling high-resolution map, managing multiple associated components, and requiring domain-specific knowledge. To quantify this gap, we construct GeoMap-Bench, the first-ever benchmark for evaluating MLLMs in geologic map understanding, which assesses the full-scale abilities in extracting, referring, grounding, reasoning, and analyzing. To bridge this gap, we introduce GeoMap-Agent, the inaugural agent designed for geologic map understanding, which features three modules: Hierarchical Information Extraction (HIE), Domain Knowledge Injection (DKI), and Prompt-enhanced Question Answering (PEQA). Inspired by the interdisciplinary collaboration among human scientists, an AI expert group acts as consultants, utilizing a diverse tool pool to comprehensively analyze questions. Through comprehensive experiments, GeoMap-Agent achieves an overall score of 0.811 on GeoMap-Bench, significantly outperforming 0.369 of GPT-4o. Our work, emPowering gEologic mAp holistiC undErstanding (PEACE) with MLLMs, paves the way for advanced AI applications in geology, enhancing the efficiency and accuracy of geological investigations.
MMLU-CF: A Contamination-free Multi-task Language Understanding Benchmark
Dec 19, 2024



Multiple-choice question (MCQ) datasets like Massive Multitask Language Understanding (MMLU) are widely used to evaluate the commonsense, understanding, and problem-solving abilities of large language models (LLMs). However, the open-source nature of these benchmarks and the broad sources of training data for LLMs have inevitably led to benchmark contamination, resulting in unreliable evaluation results. To alleviate this issue, we propose a contamination-free and more challenging MCQ benchmark called MMLU-CF. This benchmark reassesses LLMs' understanding of world knowledge by averting both unintentional and malicious data leakage. To avoid unintentional data leakage, we source data from a broader domain and design three decontamination rules. To prevent malicious data leakage, we divide the benchmark into validation and test sets with similar difficulty and subject distributions. The test set remains closed-source to ensure reliable results, while the validation set is publicly available to promote transparency and facilitate independent verification. Our evaluation of mainstream LLMs reveals that the powerful GPT-4o achieves merely a 5-shot score of 73.4% and a 0-shot score of 71.9% on the test set, which indicates the effectiveness of our approach in creating a more rigorous and contamination-free evaluation standard. The GitHub repository is available at https://github.com/microsoft/MMLU-CF and the dataset refers to https://huggingface.co/datasets/microsoft/MMLU-CF.
GaussianBlock: Building Part-Aware Compositional and Editable 3D Scene by Primitives and Gaussians
Oct 02, 2024


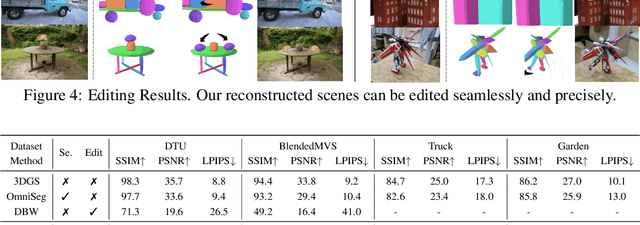
Recently, with the development of Neural Radiance Fields and Gaussian Splatting, 3D reconstruction techniques have achieved remarkably high fidelity. However, the latent representations learnt by these methods are highly entangled and lack interpretability. In this paper, we propose a novel part-aware compositional reconstruction method, called GaussianBlock, that enables semantically coherent and disentangled representations, allowing for precise and physical editing akin to building blocks, while simultaneously maintaining high fidelity. Our GaussianBlock introduces a hybrid representation that leverages the advantages of both primitives, known for their flexible actionability and editability, and 3D Gaussians, which excel in reconstruction quality. Specifically, we achieve semantically coherent primitives through a novel attention-guided centering loss derived from 2D semantic priors, complemented by a dynamic splitting and fusion strategy. Furthermore, we utilize 3D Gaussians that hybridize with primitives to refine structural details and enhance fidelity. Additionally, a binding inheritance strategy is employed to strengthen and maintain the connection between the two. Our reconstructed scenes are evidenced to be disentangled, compositional, and compact across diverse benchmarks, enabling seamless, direct and precise editing while maintaining high quality.
LTRL: Boosting Long-tail Recognition via Reflective Learning
Jul 17, 2024



In real-world scenarios, where knowledge distributions exhibit long-tail. Humans manage to master knowledge uniformly across imbalanced distributions, a feat attributed to their diligent practices of reviewing, summarizing, and correcting errors. Motivated by this learning process, we propose a novel learning paradigm, called reflecting learning, in handling long-tail recognition. Our method integrates three processes for reviewing past predictions during training, summarizing and leveraging the feature relation across classes, and correcting gradient conflict for loss functions. These designs are lightweight enough to plug and play with existing long-tail learning methods, achieving state-of-the-art performance in popular long-tail visual benchmarks. The experimental results highlight the great potential of reflecting learning in dealing with long-tail recognition.
LTGC: Long-tail Recognition via Leveraging LLMs-driven Generated Content
Mar 13, 2024Long-tail recognition is challenging because it requires the model to learn good representations from tail categories and address imbalances across all categories. In this paper, we propose a novel generative and fine-tuning framework, LTGC, to handle long-tail recognition via leveraging generated content. Firstly, inspired by the rich implicit knowledge in large-scale models (e.g., large language models, LLMs), LTGC leverages the power of these models to parse and reason over the original tail data to produce diverse tail-class content. We then propose several novel designs for LTGC to ensure the quality of the generated data and to efficiently fine-tune the model using both the generated and original data. The visualization demonstrates the effectiveness of the generation module in LTGC, which produces accurate and diverse tail data. Additionally, the experimental results demonstrate that our LTGC outperforms existing state-of-the-art methods on popular long-tailed benchmarks.
MDCS: More Diverse Experts with Consistency Self-distillation for Long-tailed Recognition
Aug 19, 2023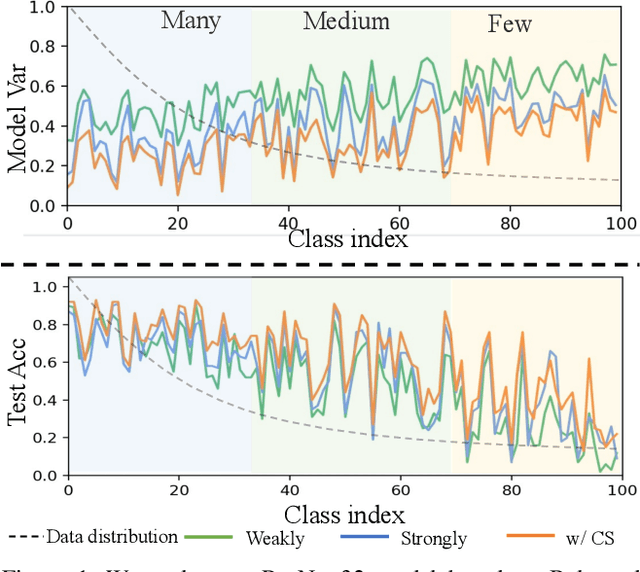
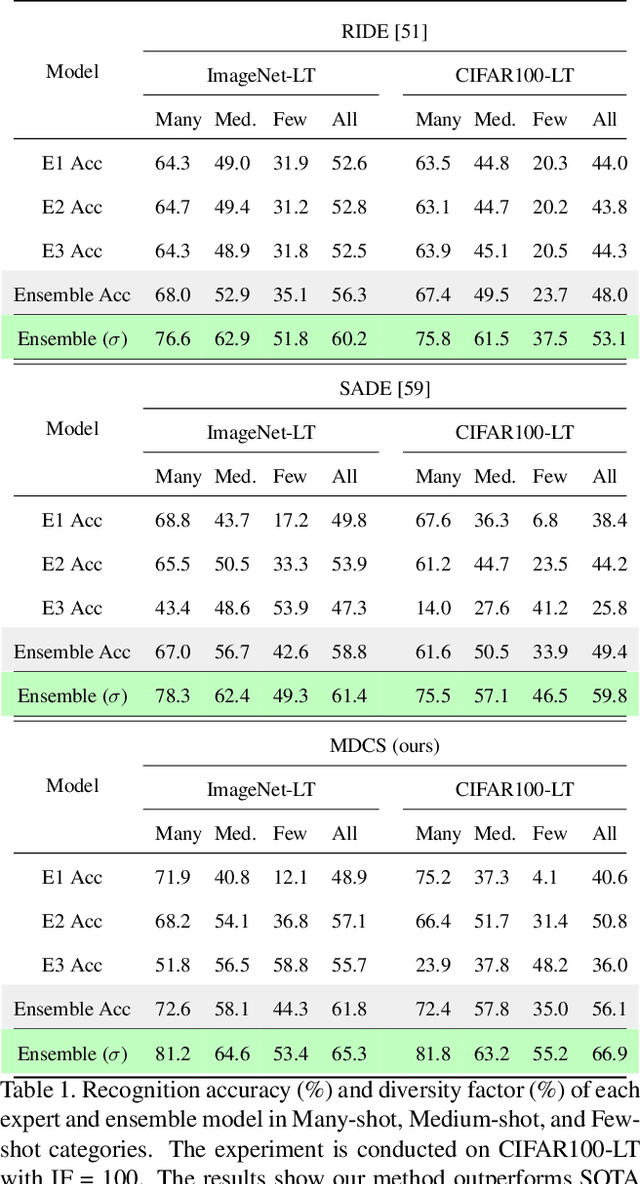
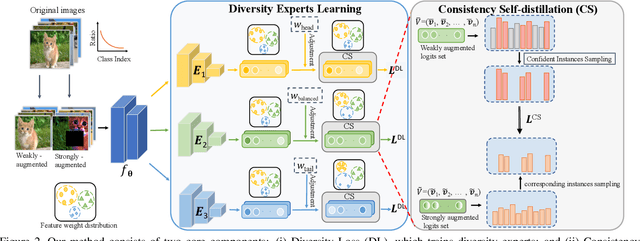
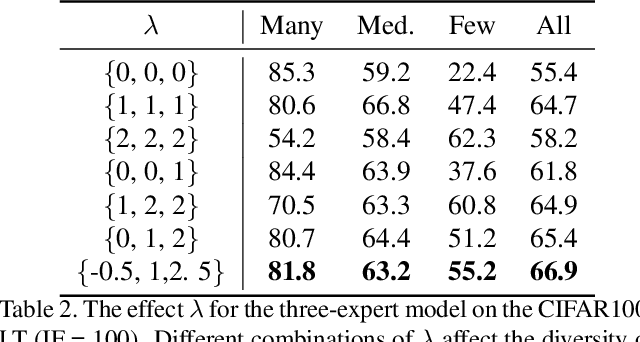
Recently, multi-expert methods have led to significant improvements in long-tail recognition (LTR). We summarize two aspects that need further enhancement to contribute to LTR boosting: (1) More diverse experts; (2) Lower model variance. However, the previous methods didn't handle them well. To this end, we propose More Diverse experts with Consistency Self-distillation (MDCS) to bridge the gap left by earlier methods. Our MDCS approach consists of two core components: Diversity Loss (DL) and Consistency Self-distillation (CS). In detail, DL promotes diversity among experts by controlling their focus on different categories. To reduce the model variance, we employ KL divergence to distill the richer knowledge of weakly augmented instances for the experts' self-distillation. In particular, we design Confident Instance Sampling (CIS) to select the correctly classified instances for CS to avoid biased/noisy knowledge. In the analysis and ablation study, we demonstrate that our method compared with previous work can effectively increase the diversity of experts, significantly reduce the variance of the model, and improve recognition accuracy. Moreover, the roles of our DL and CS are mutually reinforcing and coupled: the diversity of experts benefits from the CS, and the CS cannot achieve remarkable results without the DL. Experiments show our MDCS outperforms the state-of-the-art by 1% $\sim$ 2% on five popular long-tailed benchmarks, including CIFAR10-LT, CIFAR100-LT, ImageNet-LT, Places-LT, and iNaturalist 2018. The code is available at https://github.com/fistyee/MDCS.
MixPro: Data Augmentation with MaskMix and Progressive Attention Labeling for Vision Transformer
Apr 24, 2023



The recently proposed data augmentation TransMix employs attention labels to help visual transformers (ViT) achieve better robustness and performance. However, TransMix is deficient in two aspects: 1) The image cropping method of TransMix may not be suitable for vision transformer. 2) At the early stage of training, the model produces unreliable attention maps. TransMix uses unreliable attention maps to compute mixed attention labels that can affect the model. To address the aforementioned issues, we propose MaskMix and Progressive Attention Labeling (PAL) in image and label space, respectively. In detail, from the perspective of image space, we design MaskMix, which mixes two images based on a patch-like grid mask. In particular, the size of each mask patch is adjustable and is a multiple of the image patch size, which ensures each image patch comes from only one image and contains more global contents. From the perspective of label space, we design PAL, which utilizes a progressive factor to dynamically re-weight the attention weights of the mixed attention label. Finally, we combine MaskMix and Progressive Attention Labeling as our new data augmentation method, named MixPro. The experimental results show that our method can improve various ViT-based models at scales on ImageNet classification (73.8\% top-1 accuracy based on DeiT-T for 300 epochs). After being pre-trained with MixPro on ImageNet, the ViT-based models also demonstrate better transferability to semantic segmentation, object detection, and instance segmentation. Furthermore, compared to TransMix, MixPro also shows stronger robustness on several benchmarks. The code will be released at https://github.com/fistyee/MixPro.