 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Autonomous Agents in Resource-Constrained Robotic Platforms
Jan 07, 2026Many embedded devices operate under resource constraints and in dynamic environments, requiring local decision-making capabilities. Enabling devices to make independent decisions in such environments can improve the responsiveness of the system and reduce the dependence on constant external control. In this work, we integrate an autonomous agent, programmed using AgentSpeak, with a small two-wheeled robot that explores a maze using its own decision-making and sensor data. Experimental results show that the agent successfully solved the maze in 59 seconds using 287 reasoning cycles, with decision phases taking less than one millisecond. These results indicate that the reasoning process is efficient enough for real-time execution on resource-constrained hardware. This integration demonstrates how high-level agent-based control can be applied to resource-constrained embedded systems for autonomous operation.
$M^3-Verse$: A "Spot the Difference" Challenge for Large Multimodal Models
Dec 21, 2025Modern Large Multimodal Models (LMMs) have demonstrated extraordinary ability in static image and single-state spatial-temporal understanding. However, their capacity to comprehend the dynamic changes of objects within a shared spatial context between two distinct video observations, remains largely unexplored. This ability to reason about transformations within a consistent environment is particularly crucial for advancements in the field of spatial intelligence. In this paper, we introduce $M^3-Verse$, a Multi-Modal, Multi-State, Multi-Dimensional benchmark, to formally evaluate this capability. It is built upon paired videos that provide multi-perspective observations of an indoor scene before and after a state change. The benchmark contains a total of 270 scenes and 2,932 questions, which are categorized into over 50 subtasks that probe 4 core capabilities. We evaluate 16 state-of-the-art LMMs and observe their limitations in tracking state transitions. To address these challenges, we further propose a simple yet effective baseline that achieves significant performance improvements in multi-state perception. $M^3-Verse$ thus provides a challenging new testbed to catalyze the development of next-generation models with a more holistic understanding of our dynamic visual world. You can get the construction pipeline from https://github.com/Wal-K-aWay/M3-Verse_pipeline and full benchmark data from https://www.modelscope.cn/datasets/WalKaWay/M3-Verse.
Critical Nodes Identification in Complex Networks: A Survey
Jul 08, 2025Complex networks have become essential tools for understanding diverse phenomena in social systems, traffic systems, biomolecular systems, and financial systems. Identifying critical nodes is a central theme in contemporary research, serving as a vital bridge between theoretical foundations and practical applications. Nevertheless, the intrinsic complexity and structural heterogeneity characterizing real-world networks, with particular emphasis on dynamic and higher-order networks, present substantial obstacles to the development of universal frameworks for critical node identification. This paper provides a comprehensive review of critical node identification techniques, categorizing them into seven main classes: centrality, critical nodes deletion problem, influence maximization, network control, artificial intelligence, higher-order and dynamic methods. Our review bridges the gaps in existing surveys by systematically classifying methods based on their methodological foundations and practical implications, and by highlighting their strengths, limitations, and applicability across different network types. Our work enhances the understanding of critical node research by identifying key challenges, such as algorithmic universality, real-time evaluation in dynamic networks, analysis of higher-order structures, and computational efficiency in large-scale networks. The structured synthesis consolidates current progress and highlights open questions, particularly in modeling temporal dynamics, advancing efficient algorithms, integrating machine learning approaches, and developing scalable and interpretable metrics for complex systems.
SAMA: Towards Multi-Turn Referential Grounded Video Chat with Large Language Models
May 24, 2025Achieving fine-grained spatio-temporal understanding in videos remains a major challenge for current Video Large Multimodal Models (Video LMMs). Addressing this challenge requires mastering two core capabilities: video referring understanding, which captures the semantics of video regions, and video grounding, which segments object regions based on natural language descriptions. However, most existing approaches tackle these tasks in isolation, limiting progress toward unified, referentially grounded video interaction. We identify a key bottleneck in the lack of high-quality, unified video instruction data and a comprehensive benchmark for evaluating referentially grounded video chat. To address these challenges, we contribute in three core aspects: dataset, model, and benchmark. First, we introduce SAMA-239K, a large-scale dataset comprising 15K videos specifically curated to enable joint learning of video referring understanding, grounding, and multi-turn video chat. Second, we propose the SAMA model, which incorporates a versatile spatio-temporal context aggregator and a Segment Anything Model to jointly enhance fine-grained video comprehension and precise grounding capabilities. Finally, we establish SAMA-Bench, a meticulously designed benchmark consisting of 5,067 questions from 522 videos, to comprehensively evaluate the integrated capabilities of Video LMMs in multi-turn, spatio-temporal referring understanding and grounded dialogue. Extensive experiments and benchmarking results show that SAMA not only achieves strong performance on SAMA-Bench but also sets a new state-of-the-art on general grounding benchmarks, while maintaining highly competitive performance on standard visual understanding benchmarks.
AI-Driven Automation Can Become the Foundation of Next-Era Science of Science Research
May 17, 2025The Science of Science (SoS) explores the mechanisms underlying scientific discovery, and offers valuable insights for enhancing scientific efficiency and fostering innovation. Traditional approaches often rely on simplistic assumptions and basic statistical tools, such as linear regression and rule-based simulations, which struggle to capture the complexity and scale of modern research ecosystems. The advent of artificial intelligence (AI) presents a transformative opportunity for the next generation of SoS, enabling the automation of large-scale pattern discovery and uncovering insights previously unattainable. This paper offers a forward-looking perspective on the integration of Science of Science with AI for automated research pattern discovery and highlights key open challenges that could greatly benefit from AI. We outline the advantages of AI over traditional methods, discuss potential limitations, and propose pathways to overcome them. Additionally, we present a preliminary multi-agent system as an illustrative example to simulate research societies, showcasing AI's ability to replicate real-world research patterns and accelerate progress in Science of Science research.
eXpath: Explaining Knowledge Graph Link Prediction with Ontological Closed Path Rules
Dec 06, 2024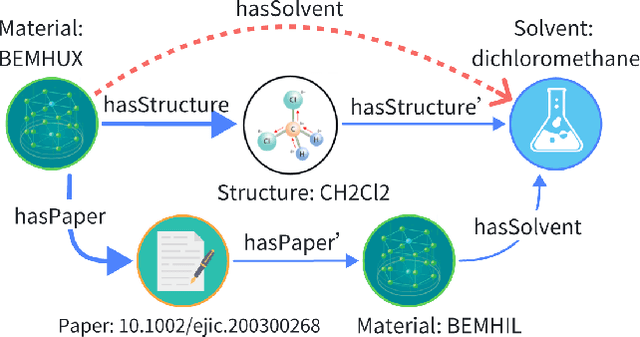
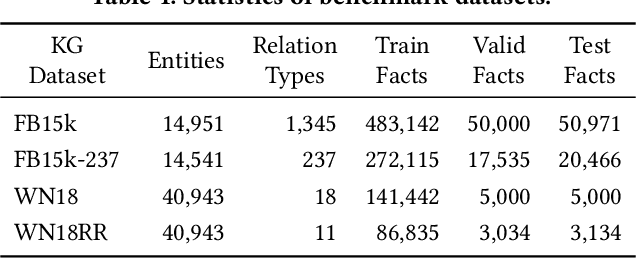
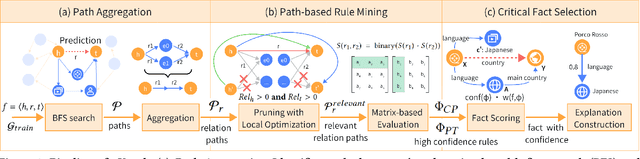
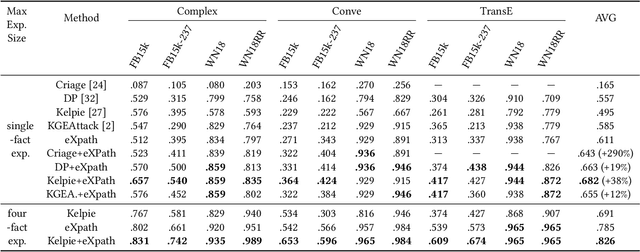
Link prediction (LP) is crucial for Knowledge Graphs (KG) completion but commonly suffers from interpretability issues. While several methods have been proposed to explain embedding-based LP models, they are generally limited to local explanations on KG and are deficient in providing human interpretable semantics. Based on real-world observations of the characteristics of KGs from multiple domains, we propose to explain LP models in KG with path-based explanations. An integrated framework, namely eXpath, is introduced which incorporates the concept of relation path with ontological closed path rules to enhance both the efficiency and effectiveness of LP interpretation. Notably, the eXpath explanations can be fused with other single-link explanation approaches to achieve a better overall solution. Extensive experiments across benchmark datasets and LP models demonstrate that introducing eXpath can boost the quality of resulting explanations by about 20% on two key metrics and reduce the required explanation time by 61.4%, in comparison to the best existing method. Case studies further highlight eXpath's ability to provide more semantically meaningful explanations through path-based evidence.
UnSeg: One Universal Unlearnable Example Generator is Enough against All Image Segmentation
Oct 13, 2024



Image segmentation is a crucial vision task that groups pixels within an image into semantically meaningful segments, which is pivotal in obtaining a fine-grained understanding of real-world scenes. However, an increasing privacy concern exists regarding training large-scale image segmentation models on unauthorized private data. In this work, we exploit the concept of unlearnable examples to make images unusable to model training by generating and adding unlearnable noise into the original images. Particularly, we propose a novel Unlearnable Segmentation (UnSeg) framework to train a universal unlearnable noise generator that is capable of transforming any downstream images into their unlearnable version. The unlearnable noise generator is finetuned from the Segment Anything Model (SAM) via bilevel optimization on an interactive segmentation dataset towards minimizing the training error of a surrogate model that shares the same architecture with SAM but is trained from scratch. We empirically verify the effectiveness of UnSeg across 6 mainstream image segmentation tasks, 10 widely used datasets, and 7 different network architectures, and show that the unlearnable images can reduce the segmentation performance by a large margin. Our work provides useful insights into how to leverage foundation models in a data-efficient and computationally affordable manner to protect images against image segmentation models.