 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents of Chaos
Feb 23, 2026We report an exploratory red-teaming study of autonomous language-model-powered agents deployed in a live laboratory environment with persistent memory, email accounts, Discord access, file systems, and shell execution. Over a two-week period, twenty AI researchers interacted with the agents under benign and adversarial conditions. Focusing on failures emerging from the integration of language models with autonomy, tool use, and multi-party communication, we document eleven representative case studies. Observed behaviors include unauthorized compliance with non-owners, disclosure of sensitive information, execution of destructive system-level actions, denial-of-service conditions, uncontrolled resource consumption, identity spoofing vulnerabilities, cross-agent propagation of unsafe practices, and partial system takeover. In several cases, agents reported task completion while the underlying system state contradicted those reports. We also report on some of the failed attempts. Our findings establish the existence of security-, privacy-, and governance-relevant vulnerabilities in realistic deployment settings. These behaviors raise unresolved questions regarding accountability, delegated authority, and responsibility for downstream harms, and warrant urgent attention from legal scholars, policymakers, and researchers across disciplines. This report serves as an initial empirical contribution to that broader conversation.
Discovering Forbidden Topics in Language Models
May 26, 2025Refusal discovery is the task of identifying the full set of topics that a language model refuses to discuss. We introduce this new problem setting and develop a refusal discovery method, LLM-crawler, that uses token prefilling to find forbidden topics. We benchmark the LLM-crawler on Tulu-3-8B, an open-source model with public safety tuning data. Our crawler manages to retrieve 31 out of 36 topics within a budget of 1000 prompts. Next, we scale the crawl to a frontier model using the prefilling option of Claude-Haiku. Finally, we crawl three widely used open-weight models: Llama-3.3-70B and two of its variants finetuned for reasoning: DeepSeek-R1-70B and Perplexity-R1-1776-70B. DeepSeek-R1-70B reveals patterns consistent with censorship tuning: The model exhibits "thought suppression" behavior that indicates memorization of CCP-aligned responses. Although Perplexity-R1-1776-70B is robust to censorship, LLM-crawler elicits CCP-aligned refusals answers in the quantized model. Our findings highlight the critical need for refusal discovery methods to detect biases, boundaries, and alignment failures of AI systems.
SAEBench: A Comprehensive Benchmark for Sparse Autoencoders in Language Model Interpretability
Mar 13, 2025Sparse autoencoders (SAEs) are a popular technique for interpreting language model activations, and there is extensive recent work on improving SAE effectiveness. However, most prior work evaluates progress using unsupervised proxy metrics with unclear practical relevance. We introduce SAEBench, a comprehensive evaluation suite that measures SAE performance across seven diverse metrics, spanning interpretability, feature disentanglement and practical applications like unlearning. To enable systematic comparison, we open-source a suite of over 200 SAEs across eight recently proposed SAE architectures and training algorithms. Our evaluation reveals that gains on proxy metrics do not reliably translate to better practical performance. For instance, while Matryoshka SAEs slightly underperform on existing proxy metrics, they substantially outperform other architectures on feature disentanglement metrics; moreover, this advantage grows with SAE scale. By providing a standardized framework for measuring progress in SAE development, SAEBench enables researchers to study scaling trends and make nuanced comparisons between different SAE architectures and training methodologies. Our interactive interface enables researchers to flexibly visualize relationships between metrics across hundreds of open-source SAEs at: https://saebench.xyz
Evaluating Sparse Autoencoders on Targeted Concept Erasure Tasks
Nov 28, 2024



Sparse Autoencoders (SAEs) are an interpretability technique aimed at decomposing neural network activations into interpretable units. However, a major bottleneck for SAE development has been the lack of high-quality performance metrics, with prior work largely relying on unsupervised proxies. In this work, we introduce a family of evaluations based on SHIFT, a downstream task from Marks et al. (Sparse Feature Circuits, 2024) in which spurious cues are removed from a classifier by ablating SAE features judged to be task-irrelevant by a human annotator. We adapt SHIFT into an automated metric of SAE quality; this involves replacing the human annotator with an LLM. Additionally, we introduce the Targeted Probe Perturbation (TPP) metric that quantifies an SAE's ability to disentangle similar concepts, effectively scaling SHIFT to a wider range of datasets. We apply both SHIFT and TPP to multiple open-source models, demonstrating that these metrics effectively differentiate between various SAE training hyperparameters and architectures.
The Quest for the Right Mediator: A History, Survey, and Theoretical Grounding of Causal Interpretability
Aug 02, 2024


Interpretability provides a toolset for understanding how and why neural networks behave in certain ways. However, there is little unity in the field: most studies employ ad-hoc evaluations and do not share theoretical foundations, making it difficult to measure progress and compare the pros and cons of different techniques. Furthermore, while mechanistic understanding is frequently discussed, the basic causal units underlying these mechanisms are often not explicitly defined. In this paper, we propose a perspective on interpretability research grounded in causal mediation analysis. Specifically, we describe the history and current state of interpretability taxonomized according to the types of causal units (mediators) employed, as well as methods used to search over mediators. We discuss the pros and cons of each mediator, providing insights as to when particular kinds of mediators and search methods are most appropriate depending on the goals of a given study. We argue that this framing yields a more cohesive narrative of the field, as well as actionable insights for future work. Specifically, we recommend a focus on discovering new mediators with better trade-offs between human-interpretability and compute-efficiency, and which can uncover more sophisticated abstractions from neural networks than the primarily linear mediators employed in current work. We also argue for more standardized evaluations that enable principled comparisons across mediator types, such that we can better understand when particular causal units are better suited to particular use cases.
Measuring Progress in Dictionary Learning for Language Model Interpretability with Board Game Models
Jul 31, 2024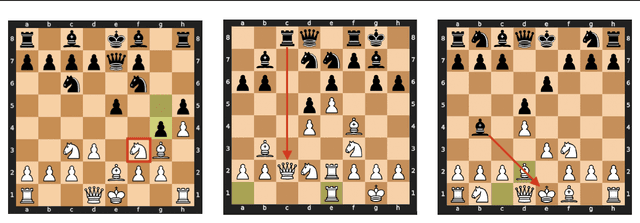
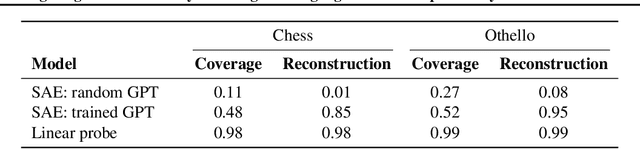
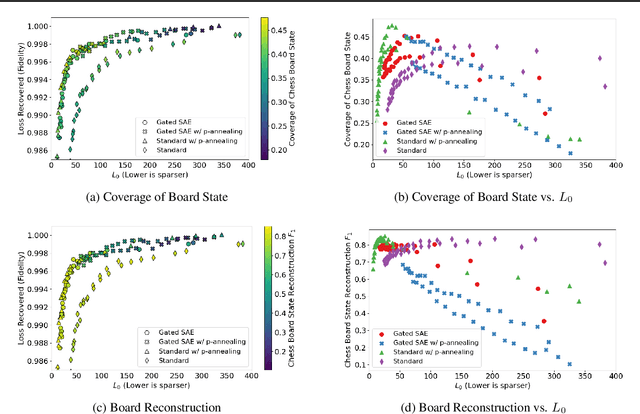
What latent features are encoded in language model (LM) representations? Recent work on training sparse autoencoders (SAEs) to disentangle interpretable features in LM representations has shown significant promise. However, evaluating the quality of these SAEs is difficult because we lack a ground-truth collection of interpretable features that we expect good SAEs to recover. We thus propose to measure progress in interpretable dictionary learning by working in the setting of LMs trained on chess and Othello transcripts. These settings carry natural collections of interpretable features -- for example, "there is a knight on F3" -- which we leverage into $\textit{supervised}$ metrics for SAE quality. To guide progress in interpretable dictionary learning, we introduce a new SAE training technique, $\textit{p-annealing}$, which improves performance on prior unsupervised metrics as well as our new metrics.
NNsight and NDIF: Democratizing Access to Foundation Model Internals
Jul 18, 2024



The enormous scale of state-of-the-art foundation models has limited their accessibility to scientists, because customized experiments at large model sizes require costly hardware and complex engineering that is impractical for most researchers. To alleviate these problems, we introduce NNsight, an open-source Python package with a simple, flexible API that can express interventions on any PyTorch model by building computation graphs. We also introduce NDIF, a collaborative research platform providing researchers access to foundation-scale LLMs via the NNsight API. Code, documentation, and tutorials are available at https://www.nnsight.net.
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Mar 31, 2024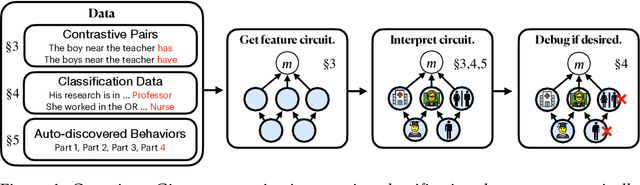

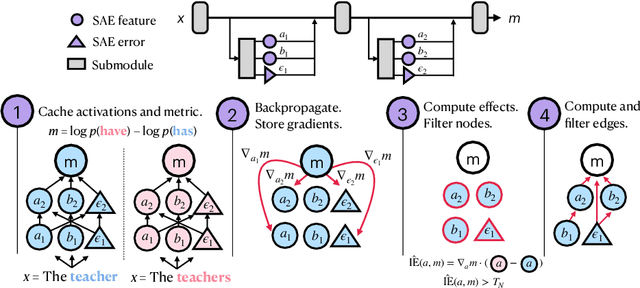
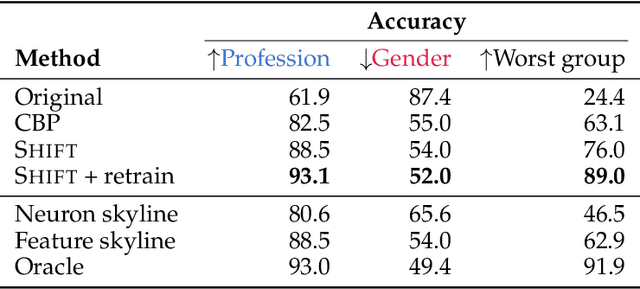
We introduce methods for discovering and applying sparse feature circuits. These are causally implicated subnetworks of human-interpretable features for explaining language model behaviors. Circuits identified in prior work consist of polysemantic and difficult-to-interpret units like attention heads or neurons, rendering them unsuitable for many downstream applications. In contrast, sparse feature circuits enable detailed understanding of unanticipated mechanisms. Because they are based on fine-grained units, sparse feature circuits are useful for downstream tasks: We introduce SHIFT, where we improve the generalization of a classifier by ablating features that a human judges to be task-irrelevant. Finally, we demonstrate an entirely unsupervised and scalable interpretability pipeline by discovering thousands of sparse feature circuits for automatically discovered model behaviors.
Structured World Representations in Maze-Solving Transformers
Dec 05, 2023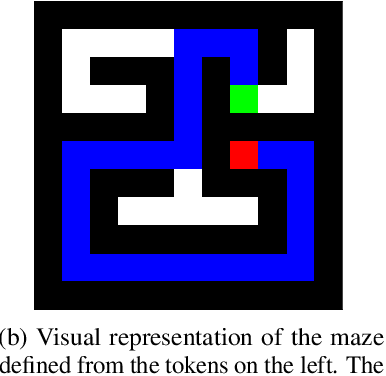
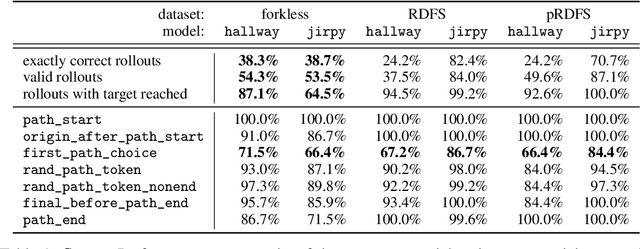
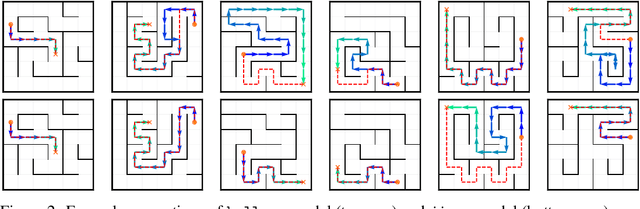

Transformer models underpin many recent advances in practical machine learning applications, yet understanding their internal behavior continues to elude researchers. Given the size and complexity of these models, forming a comprehensive picture of their inner workings remains a significant challenge. To this end, we set out to understand small transformer models in a more tractable setting: that of solving mazes. In this work, we focus on the abstractions formed by these models and find evidence for the consistent emergence of structured internal representations of maze topology and valid paths. We demonstrate this by showing that the residual stream of only a single token can be linearly decoded to faithfully reconstruct the entire maze. We also find that the learned embeddings of individual tokens have spatial structure. Furthermore, we take steps towards deciphering the circuity of path-following by identifying attention heads (dubbed $\textit{adjacency heads}$), which are implicated in finding valid subsequent tokens.
Attribution Patching Outperforms Automated Circuit Discovery
Oct 16, 2023Automated interpretability research has recently attracted attention as a potential research direction that could scale explanations of neural network behavior to large models. Existing automated circuit discovery work applies activation patching to identify subnetworks responsible for solving specific tasks (circuits). In this work, we show that a simple method based on attribution patching outperforms all existing methods while requiring just two forward passes and a backward pass. We apply a linear approximation to activation patching to estimate the importance of each edge in the computational subgraph. Using this approximation, we prune the least important edges of the network. We survey the performance and limitations of this method, finding that averaged over all tasks our method has greater AUC from circuit recovery than other methods.