 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition Paper: Toward New Frameworks for Studying Model Representations
Feb 06, 2024Mechanistic interpretability (MI) aims to understand AI models by reverse-engineering the exact algorithms neural networks learn. Most works in MI so far have studied behaviors and capabilities that are trivial and token-aligned. However, most capabilities are not that trivial, which advocates for the study of hidden representations inside these networks as the unit of analysis. We do a literature review, formalize representations for features and behaviors, highlight their importance and evaluation, and perform some basic exploration in the mechanistic interpretability of representations. With discussion and exploratory results, we justify our position that studying representations is an important and under-studied field, and that currently established methods in MI are not sufficient to understand representations, thus pushing for the research community to work toward new frameworks for studying representations.
An Adversarial Example for Direct Logit Attribution: Memory Management in gelu-4l
Oct 14, 2023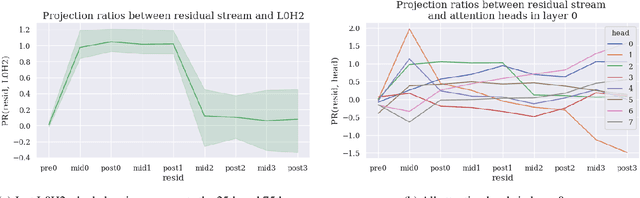
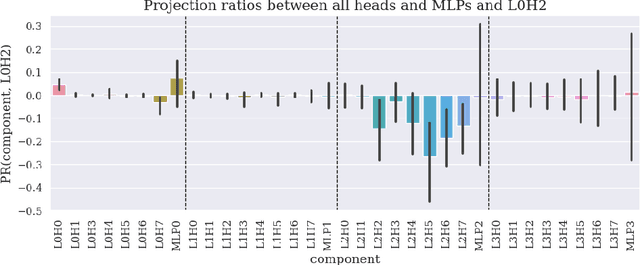
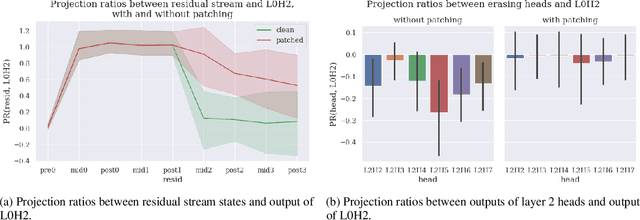
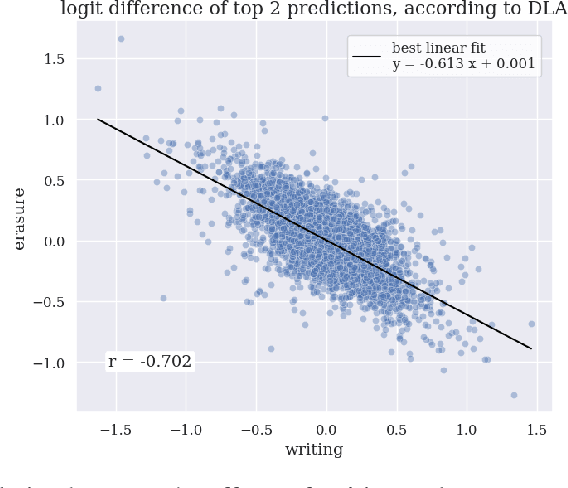
We provide concrete evidence for memory management in a 4-layer transformer. Specifically, we identify clean-up behavior, in which model components consistently remove the output of preceeding components during a forward pass. Our findings suggest that the interpretability technique Direct Logit Attribution provides misleading results. We show explicit examples where this technique is inaccurate, as it does not account for clean-up behavior.