 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Better Deception Probes Using Targeted Instruction Pairs
Feb 01, 2026Linear probes are a promising approach for monitoring AI systems for deceptive behaviour. Previous work has shown that a linear classifier trained on a contrastive instruction pair and a simple dataset can achieve good performance. However, these probes exhibit notable failures even in straightforward scenarios, including spurious correlations and false positives on non-deceptive responses. In this paper, we identify the importance of the instruction pair used during training. Furthermore, we show that targeting specific deceptive behaviors through a human-interpretable taxonomy of deception leads to improved results on evaluation datasets. Our findings reveal that instruction pairs capture deceptive intent rather than content-specific patterns, explaining why prompt choice dominates probe performance (70.6% of variance). Given the heterogeneity of deception types across datasets, we conclude that organizations should design specialized probes targeting their specific threat models rather than seeking a universal deception detector.
ABBEL: LLM Agents Acting through Belief Bottlenecks Expressed in Language
Dec 23, 2025As the length of sequential decision-making tasks increases, it becomes computationally impractical to keep full interaction histories in context. We introduce a general framework for LLM agents to maintain concise contexts through multi-step interaction: Acting through Belief Bottlenecks Expressed in Language (ABBEL), and methods to further improve ABBEL agents with RL post-training. ABBEL replaces long multi-step interaction history by a belief state, i.e., a natural language summary of what has been discovered about task-relevant unknowns. Under ABBEL, at each step the agent first updates a prior belief with the most recent observation from the environment to form a posterior belief, then uses only the posterior to select an action. We systematically evaluate frontier models under ABBEL across six diverse multi-step environments, finding that ABBEL supports generating interpretable beliefs while maintaining near-constant memory use over interaction steps. However, bottleneck approaches are generally prone to error propagation, which we observe causing inferior performance when compared to the full context setting due to errors in belief updating. Therefore, we train LLMs to generate and act on beliefs within the ABBEL framework via reinforcement learning (RL). We experiment with belief grading, to reward higher quality beliefs, as well as belief length penalties to reward more compressed beliefs. Our experiments demonstrate the ability of RL to improve ABBEL's performance beyond the full context setting, while using less memory than contemporaneous approaches.
Auditing Games for Sandbagging
Dec 08, 2025Future AI systems could conceal their capabilities ('sandbagging') during evaluations, potentially misleading developers and auditors. We stress-tested sandbagging detection techniques using an auditing game. First, a red team fine-tuned five models, some of which conditionally underperformed, as a proxy for sandbagging. Second, a blue team used black-box, model-internals, or training-based approaches to identify sandbagging models. We found that the blue team could not reliably discriminate sandbaggers from benign models. Black-box approaches were defeated by effective imitation of a weaker model. Linear probes, a model-internals approach, showed more promise but their naive application was vulnerable to behaviours instilled by the red team. We also explored capability elicitation as a strategy for detecting sandbagging. Although Prompt-based elicitation was not reliable, training-based elicitation consistently elicited full performance from the sandbagging models, using only a single correct demonstration of the evaluation task. However the performance of benign models was sometimes also raised, so relying on elicitation as a detection strategy was prone to false-positives. In the short-term, we recommend developers remove potential sandbagging using on-distribution training for elicitation. In the longer-term, further research is needed to ensure the efficacy of training-based elicitation, and develop robust methods for sandbagging detection. We open source our model organisms at https://github.com/AI-Safety-Institute/sandbagging_auditing_games and select transcripts and results at https://huggingface.co/datasets/sandbagging-games/evaluation_logs . A demo illustrating the game can be played at https://sandbagging-demo.far.ai/ .
Among Us: A Sandbox for Agentic Deception
Apr 05, 2025



Studying deception in AI agents is important and difficult due to the lack of model organisms and sandboxes that elicit the behavior without asking the model to act under specific conditions or inserting intentional backdoors. Extending upon $\textit{AmongAgents}$, a text-based social-deduction game environment, we aim to fix this by introducing Among Us as a rich sandbox where LLM-agents exhibit human-style deception naturally while they think, speak, and act with other agents or humans. We introduce Deception ELO as an unbounded measure of deceptive capability, suggesting that frontier models win more because they're better at deception, not at detecting it. We evaluate the effectiveness of AI safety techniques (LLM-monitoring of outputs, linear probes on various datasets, and sparse autoencoders) for detecting lying and deception in Among Us, and find that they generalize very well out-of-distribution. We open-source our sandbox as a benchmark for future alignment research and hope that this is a good testbed to improve safety techniques to detect and remove agentically-motivated deception, and to anticipate deceptive abilities in LLMs.
Auditing language models for hidden objectives
Mar 14, 2025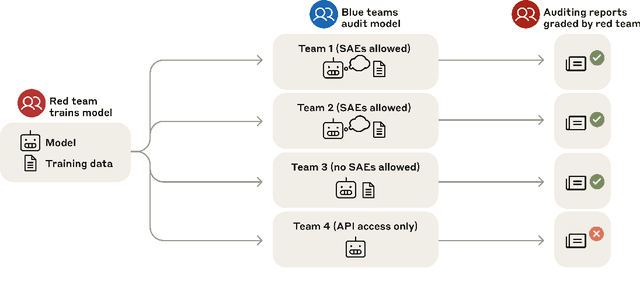


We study the feasibility of conducting alignment audits: investigations into whether models have undesired objectives. As a testbed, we train a language model with a hidden objective. Our training pipeline first teaches the model about exploitable errors in RLHF reward models (RMs), then trains the model to exploit some of these errors. We verify via out-of-distribution evaluations that the model generalizes to exhibit whatever behaviors it believes RMs rate highly, including ones not reinforced during training. We leverage this model to study alignment audits in two ways. First, we conduct a blind auditing game where four teams, unaware of the model's hidden objective or training, investigate it for concerning behaviors and their causes. Three teams successfully uncovered the model's hidden objective using techniques including interpretability with sparse autoencoders (SAEs), behavioral attacks, and training data analysis. Second, we conduct an unblinded follow-up study of eight techniques for auditing the model, analyzing their strengths and limitations. Overall, our work provides a concrete example of using alignment audits to discover a model's hidden objective and proposes a methodology for practicing and validating progress in alignment auditing.
Modular Training of Neural Networks aids Interpretability
Feb 04, 2025



An approach to improve neural network interpretability is via clusterability, i.e., splitting a model into disjoint clusters that can be studied independently. We define a measure for clusterability and show that pre-trained models form highly enmeshed clusters via spectral graph clustering. We thus train models to be more modular using a ``clusterability loss'' function that encourages the formation of non-interacting clusters. Using automated interpretability techniques, we show that our method can help train models that are more modular and learn different, disjoint, and smaller circuits. We investigate CNNs trained on MNIST and CIFAR, small transformers trained on modular addition, and language models. Our approach provides a promising direction for training neural networks that learn simpler functions and are easier to interpret.
Progress Measures for Grokking on Real-world Datasets
May 21, 2024Grokking, a phenomenon where machine learning models generalize long after overfitting, has been primarily observed and studied in algorithmic tasks. This paper explores grokking in real-world datasets using deep neural networks for classification under the cross-entropy loss. We challenge the prevalent hypothesis that the $L_2$ norm of weights is the primary cause of grokking by demonstrating that grokking can occur outside the expected range of weight norms. To better understand grokking, we introduce three new progress measures: activation sparsity, absolute weight entropy, and approximate local circuit complexity. These measures are conceptually related to generalization and demonstrate a stronger correlation with grokking in real-world datasets compared to weight norms. Our findings suggest that while weight norms might usually correlate with grokking and our progress measures, they are not causative, and our proposed measures provide a better understanding of the dynamics of grokking.
NICE: To Optimize In-Context Examples or Not?
Feb 16, 2024



Recent work shows that in-context learning and optimization of in-context examples (ICE) can significantly improve the accuracy of large language models (LLMs) on a wide range of tasks, leading to an apparent consensus that ICE optimization is crucial for better performance. However, most of these studies assume a fixed or no instruction provided in the prompt. We challenge this consensus by investigating the necessity of optimizing ICE when task-specific instructions are provided and find that there are tasks for which it yields diminishing returns. In particular, using a diverse set of tasks and a systematically created instruction set with gradually added details, we find that as the prompt instruction becomes more detailed, the returns on ICE optimization diminish. To characterize this behavior, we introduce a task-specific metric called Normalized Invariability to Choice of Examples (NICE) that quantifies the learnability of tasks from a given instruction, and provides a heuristic that helps decide whether to optimize instructions or ICE for a new task. Given a task, the proposed metric can reliably predict the utility of optimizing ICE compared to using random ICE.
CataractBot: An LLM-Powered Expert-in-the-Loop Chatbot for Cataract Patients
Feb 07, 2024



The healthcare landscape is evolving, with patients seeking more reliable information about their health conditions, treatment options, and potential risks. Despite the abundance of information sources, the digital age overwhelms individuals with excess, often inaccurate information. Patients primarily trust doctors and hospital staff, highlighting the need for expert-endorsed health information. However, the pressure on experts has led to reduced communication time, impacting information sharing. To address this gap, we propose CataractBot, an experts-in-the-loop chatbot powered by large language models (LLMs). Developed in collaboration with a tertiary eye hospital in India, CataractBot answers cataract surgery related questions instantly by querying a curated knowledge base, and provides expert-verified responses asynchronously. CataractBot features multimodal support and multilingual capabilities. In an in-the-wild deployment study with 49 participants, CataractBot proved valuable, providing anytime accessibility, saving time, and accommodating diverse literacy levels. Trust was established through expert verification. Broadly, our results could inform future work on designing expert-mediated LLM bots.
Position Paper: Toward New Frameworks for Studying Model Representations
Feb 06, 2024Mechanistic interpretability (MI) aims to understand AI models by reverse-engineering the exact algorithms neural networks learn. Most works in MI so far have studied behaviors and capabilities that are trivial and token-aligned. However, most capabilities are not that trivial, which advocates for the study of hidden representations inside these networks as the unit of analysis. We do a literature review, formalize representations for features and behaviors, highlight their importance and evaluation, and perform some basic exploration in the mechanistic interpretability of representations. With discussion and exploratory results, we justify our position that studying representations is an important and under-studied field, and that currently established methods in MI are not sufficient to understand representations, thus pushing for the research community to work toward new frameworks for studying representations.