 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting time-varying flux and balance in metabolic systems using structured neural-ODE processes
Oct 18, 2024

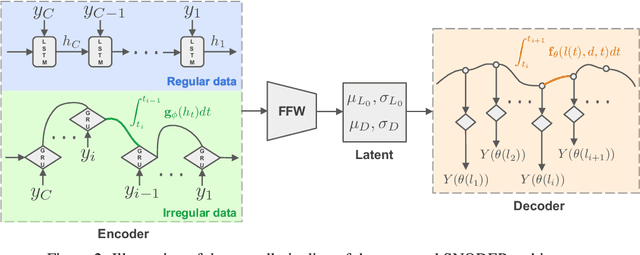
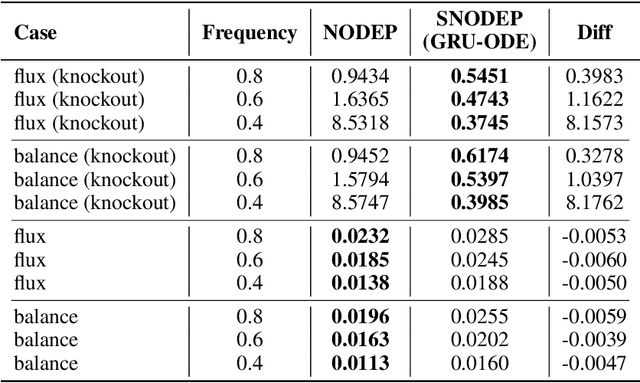
We develop a novel data-driven framework as an alternative to dynamic flux balance analysis, bypassing the demand for deep domain knowledge and manual efforts to formulate the optimization problem. The proposed framework is end-to-end, which trains a structured neural ODE process (SNODEP) model to estimate flux and balance samples using gene-expression time-series data. SNODEP is designed to circumvent the limitations of the standard neural ODE process model, including restricting the latent and decoder sampling distributions to be normal and lacking structure between context points for calculating the latent, thus more suitable for modeling the underlying dynamics of a metabolic system. Through comprehensive experiments ($156$ in total), we demonstrate that SNODEP not only predicts the unseen time points of real-world gene-expression data and the flux and balance estimates well but can even generalize to more challenging unseen knockout configurations and irregular data sampling scenarios, all essential for metabolic pathway analysis. We hope our work can serve as a catalyst for building more scalable and powerful models for genome-scale metabolic analysis. Our code is available at: \url{https://github.com/TrustMLRG/SNODEP}.
Predicting Treatment Adherence of Tuberculosis Patients at Scale
Nov 15, 2022



Tuberculosis (TB), an infectious bacterial disease, is a significant cause of death, especially in low-income countries, with an estimated ten million new cases reported globally in $2020$. While TB is treatable, non-adherence to the medication regimen is a significant cause of morbidity and mortality. Thus, proactively identifying patients at risk of dropping off their medication regimen enables corrective measures to mitigate adverse outcomes. Using a proxy measure of extreme non-adherence and a dataset of nearly $700,000$ patients from four states in India, we formulate and solve the machine learning (ML) problem of early prediction of non-adherence based on a custom rank-based metric. We train ML models and evaluate against baselines, achieving a $\sim 100\%$ lift over rule-based baselines and $\sim 214\%$ over a random classifier, taking into account country-wide large-scale future deployment. We deal with various issues in the process, including data quality, high-cardinality categorical data, low target prevalence, distribution shift, variation across cohorts, algorithmic fairness, and the need for robustness and explainability. Our findings indicate that risk stratification of non-adherent patients is a viable, deployable-at-scale ML solution. As the official AI partner of India's Central TB Division, we are working on multiple city and state-level pilots with the goal of pan-India deployment.
Scheduling to Learn In An Unsupervised Online Streaming Model
Dec 02, 2021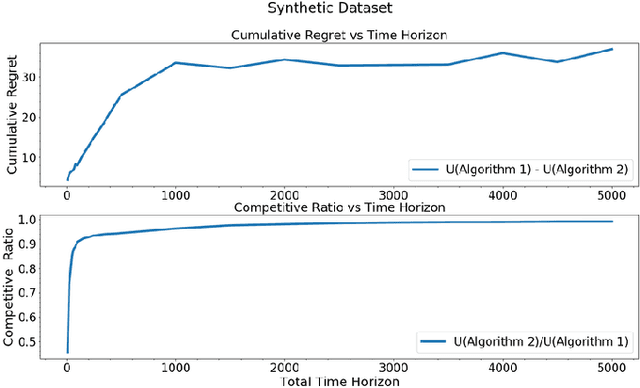
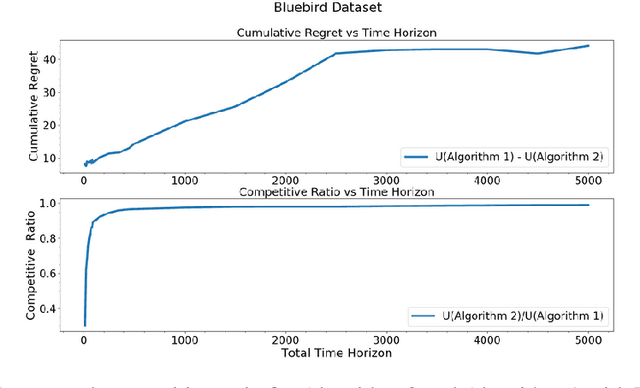

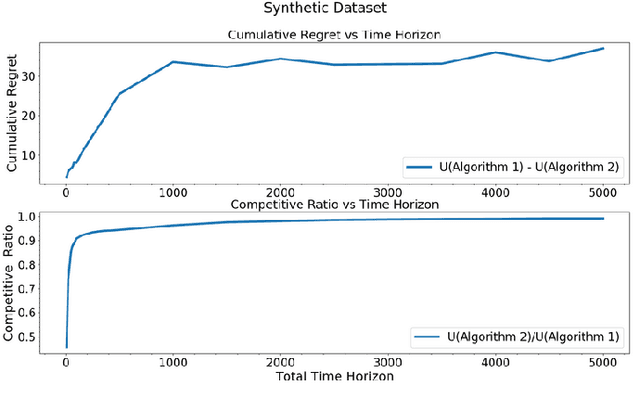
An unsupervised online streaming model is considered where samples arrive in an online fashion over $T$ slots. There are $M$ classifiers, whose confusion matrices are unknown a priori. In each slot, at most one sample can be labeled by any classifier. The accuracy of a sample is a function of the set of labels obtained for it from various classifiers. The utility of a sample is a scalar multiple of its accuracy minus the response time (difference of the departure slot and the arrival slot), where the departure slot is also decided by the algorithm. Since each classifier can label at most one sample per slot, there is a tradeoff between obtaining a larger set of labels for a particular sample to improve its accuracy, and its response time. The problem of maximizing the sum of the utilities of all samples is considered, where learning the confusion matrices, sample-classifier matching assignment, and sample departure slot decisions depend on each other. The proposed algorithm first learns the confusion matrices, and then uses a greedy algorithm for sample-classifier matching. A sample departs once its incremental utility turns non-positive. We show that the competitive ratio of the proposed algorithm is $\frac{1}{2}-{\mathcal O}\left(\frac{\log T}{T}\right)$.
On reducing the order of arm-passes bandit streaming algorithms under memory bottleneck
Nov 30, 2021
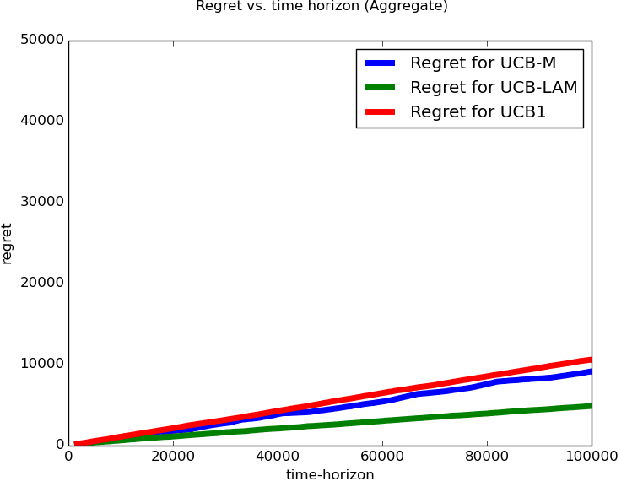
In this work we explore multi-arm bandit streaming model, especially in cases where the model faces resource bottleneck. We build over existing algorithms conditioned by limited arm memory at any instance of time. Specifically, we improve the amount of streaming passes it takes for a bandit algorithm to incur a $O(\sqrt{T\log(T)})$ regret by a logarithmic factor, and also provide 2-pass algorithms with some initial conditions to incur a similar order of regret.
Global Convergence Using Policy Gradient Methods for Model-free Markovian Jump Linear Quadratic Control
Nov 30, 2021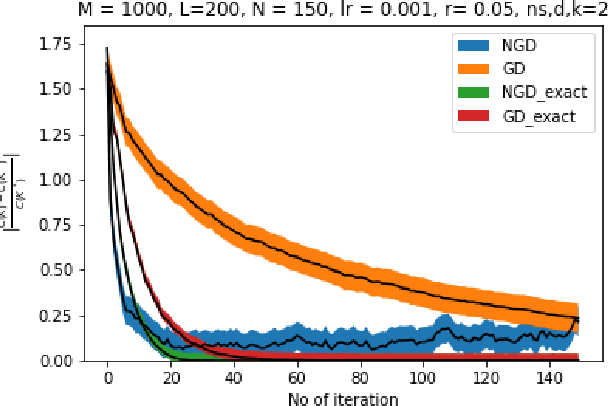
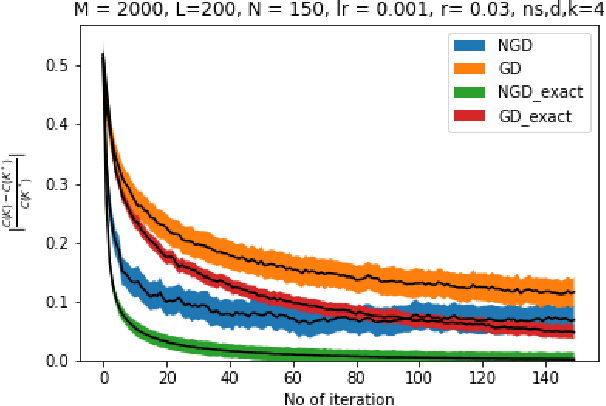
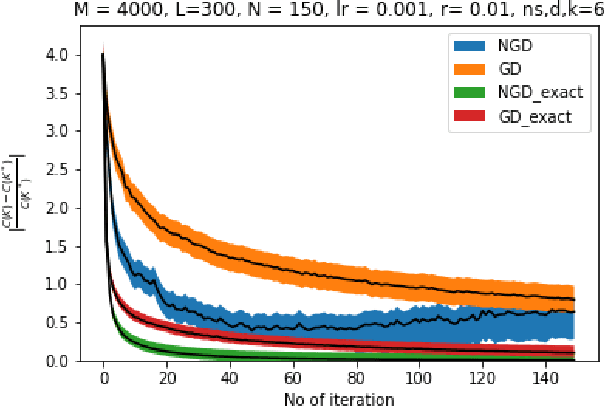
Owing to the growth of interest in Reinforcement Learning in the last few years, gradient based policy control methods have been gaining popularity for Control problems as well. And rightly so, since gradient policy methods have the advantage of optimizing a metric of interest in an end-to-end manner, along with being relatively easy to implement without complete knowledge of the underlying system. In this paper, we study the global convergence of gradient-based policy optimization methods for quadratic control of discrete-time and model-free Markovian jump linear systems (MJLS). We surmount myriad challenges that arise because of more than one states coupled with lack of knowledge of the system dynamics and show global convergence of the policy using gradient descent and natural policy gradient methods. We also provide simulation studies to corroborate our claims.