 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Models Manipulate Manifolds: The Geometry of a Counting Task
Jan 08, 2026Language models can perceive visual properties of text despite receiving only sequences of tokens-we mechanistically investigate how Claude 3.5 Haiku accomplishes one such task: linebreaking in fixed-width text. We find that character counts are represented on low-dimensional curved manifolds discretized by sparse feature families, analogous to biological place cells. Accurate predictions emerge from a sequence of geometric transformations: token lengths are accumulated into character count manifolds, attention heads twist these manifolds to estimate distance to the line boundary, and the decision to break the line is enabled by arranging estimates orthogonally to create a linear decision boundary. We validate our findings through causal interventions and discover visual illusions--character sequences that hijack the counting mechanism. Our work demonstrates the rich sensory processing of early layers, the intricacy of attention algorithms, and the importance of combining feature-based and geometric views of interpretability.
Auditing language models for hidden objectives
Mar 14, 2025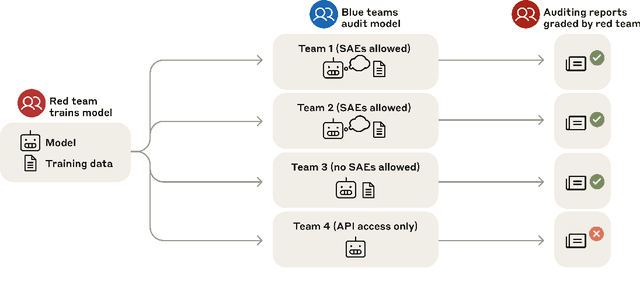


We study the feasibility of conducting alignment audits: investigations into whether models have undesired objectives. As a testbed, we train a language model with a hidden objective. Our training pipeline first teaches the model about exploitable errors in RLHF reward models (RMs), then trains the model to exploit some of these errors. We verify via out-of-distribution evaluations that the model generalizes to exhibit whatever behaviors it believes RMs rate highly, including ones not reinforced during training. We leverage this model to study alignment audits in two ways. First, we conduct a blind auditing game where four teams, unaware of the model's hidden objective or training, investigate it for concerning behaviors and their causes. Three teams successfully uncovered the model's hidden objective using techniques including interpretability with sparse autoencoders (SAEs), behavioral attacks, and training data analysis. Second, we conduct an unblinded follow-up study of eight techniques for auditing the model, analyzing their strengths and limitations. Overall, our work provides a concrete example of using alignment audits to discover a model's hidden objective and proposes a methodology for practicing and validating progress in alignment auditing.