 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Understand, Reason About, and Generate Code-Switched Text?
Jan 12, 2026Code-switching is a pervasive phenomenon in multilingual communication, yet the robustness of large language models (LLMs) in mixed-language settings remains insufficiently understood. In this work, we present a comprehensive evaluation of LLM capabilities in understanding, reasoning over, and generating code-switched text. We introduce CodeMixQA a novel benchmark with high-quality human annotations, comprising 16 diverse parallel code-switched language-pair variants that span multiple geographic regions and code-switching patterns, and include both original scripts and their transliterated forms. Using this benchmark, we analyze the reasoning behavior of LLMs on code-switched question-answering tasks, shedding light on how models process and reason over mixed-language inputs. We further conduct a systematic evaluation of LLM-generated synthetic code-switched text, focusing on both naturalness and semantic fidelity, and uncover key limitations in current generation capabilities. Our findings reveal persistent challenges in both reasoning and generation under code-switching conditions and provide actionable insights for building more robust multilingual LLMs. We release the dataset and code as open source.
Pulmonary Embolism Mortality Prediction Using Multimodal Learning Based on Computed Tomography Angiography and Clinical Data
Jun 03, 2024Purpose: Pulmonary embolism (PE) is a significant cause of mortality in the United States. The objective of this study is to implement deep learning (DL) models using Computed Tomography Pulmonary Angiography (CTPA), clinical data, and PE Severity Index (PESI) scores to predict PE mortality. Materials and Methods: 918 patients (median age 64 years, range 13-99 years, 52% female) with 3,978 CTPAs were identified via retrospective review across three institutions. To predict survival, an AI model was used to extract disease-related imaging features from CTPAs. Imaging features and/or clinical variables were then incorporated into DL models to predict survival outcomes. Four models were developed as follows: (1) using CTPA imaging features only; (2) using clinical variables only; (3) multimodal, integrating both CTPA and clinical variables; and (4) multimodal fused with calculated PESI score. Performance and contribution from each modality were evaluated using concordance index (c-index) and Net Reclassification Improvement, respectively. Performance was compared to PESI predictions using the Wilcoxon signed-rank test. Kaplan-Meier analysis was performed to stratify patients into high- and low-risk groups. Additional factor-risk analysis was conducted to account for right ventricular (RV) dysfunction. Results: For both data sets, the PESI-fused and multimodal models achieved higher c-indices than PESI alone. Following stratification of patients into high- and low-risk groups by multimodal and PESI-fused models, mortality outcomes differed significantly (both p<0.001). A strong correlation was found between high-risk grouping and RV dysfunction. Conclusions: Multiomic DL models incorporating CTPA features, clinical data, and PESI achieved higher c-indices than PESI alone for PE survival prediction.
V-FLUTE: Visual Figurative Language Understanding with Textual Explanations
May 02, 2024Large Vision-Language models (VLMs) have demonstrated strong reasoning capabilities in tasks requiring a fine-grained understanding of literal images and text, such as visual question-answering or visual entailment. However, there has been little exploration of these models' capabilities when presented with images and captions containing figurative phenomena such as metaphors or humor, the meaning of which is often implicit. To close this gap, we propose a new task and a high-quality dataset: Visual Figurative Language Understanding with Textual Explanations (V-FLUTE). We frame the visual figurative language understanding problem as an explainable visual entailment task, where the model has to predict whether the image (premise) entails a claim (hypothesis) and justify the predicted label with a textual explanation. Using a human-AI collaboration framework, we build a high-quality dataset, V-FLUTE, that contains 6,027 <image, claim, label, explanation> instances spanning five diverse multimodal figurative phenomena: metaphors, similes, idioms, sarcasm, and humor. The figurative phenomena can be present either in the image, the caption, or both. We further conduct both automatic and human evaluations to assess current VLMs' capabilities in understanding figurative phenomena.
CataractBot: An LLM-Powered Expert-in-the-Loop Chatbot for Cataract Patients
Feb 07, 2024



The healthcare landscape is evolving, with patients seeking more reliable information about their health conditions, treatment options, and potential risks. Despite the abundance of information sources, the digital age overwhelms individuals with excess, often inaccurate information. Patients primarily trust doctors and hospital staff, highlighting the need for expert-endorsed health information. However, the pressure on experts has led to reduced communication time, impacting information sharing. To address this gap, we propose CataractBot, an experts-in-the-loop chatbot powered by large language models (LLMs). Developed in collaboration with a tertiary eye hospital in India, CataractBot answers cataract surgery related questions instantly by querying a curated knowledge base, and provides expert-verified responses asynchronously. CataractBot features multimodal support and multilingual capabilities. In an in-the-wild deployment study with 49 participants, CataractBot proved valuable, providing anytime accessibility, saving time, and accommodating diverse literacy levels. Trust was established through expert verification. Broadly, our results could inform future work on designing expert-mediated LLM bots.
RAIFLE: Reconstruction Attacks on Interaction-based Federated Learning with Active Data Manipulation
Oct 29, 2023Federated learning (FL) has recently emerged as a privacy-preserving approach for machine learning in domains that rely on user interactions, particularly recommender systems (RS) and online learning to rank (OLTR). While there has been substantial research on the privacy of traditional FL, little attention has been paid to studying the privacy properties of these interaction-based FL (IFL) systems. In this work, we show that IFL can introduce unique challenges concerning user privacy, particularly when the central server has knowledge and control over the items that users interact with. Specifically, we demonstrate the threat of reconstructing user interactions by presenting RAIFLE, a general optimization-based reconstruction attack framework customized for IFL. RAIFLE employs Active Data Manipulation (ADM), a novel attack technique unique to IFL, where the server actively manipulates the training features of the items to induce adversarial behaviors in the local FL updates. We show that RAIFLE is more impactful than existing FL privacy attacks in the IFL context, and describe how it can undermine privacy defenses like secure aggregation and private information retrieval. Based on our findings, we propose and discuss countermeasure guidelines to mitigate our attack in the context of federated RS/OLTR specifically and IFL more broadly.
360FusionNeRF: Panoramic Neural Radiance Fields with Joint Guidance
Oct 03, 2022
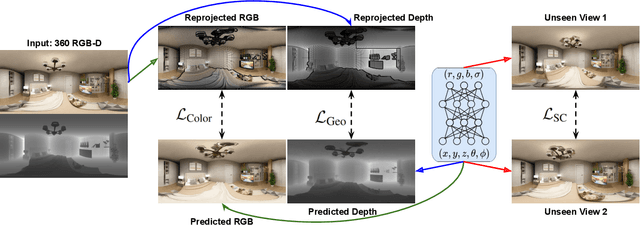

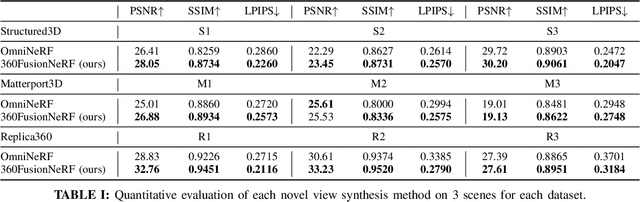
We present a method to synthesize novel views from a single $360^\circ$ panorama image based on the neural radiance field (NeRF). Prior studies in a similar setting rely on the neighborhood interpolation capability of multi-layer perceptions to complete missing regions caused by occlusion, which leads to artifacts in their predictions. We propose 360FusionNeRF, a semi-supervised learning framework where we introduce geometric supervision and semantic consistency to guide the progressive training process. Firstly, the input image is re-projected to $360^\circ$ images, and auxiliary depth maps are extracted at other camera positions. The depth supervision, in addition to the NeRF color guidance, improves the geometry of the synthesized views. Additionally, we introduce a semantic consistency loss that encourages realistic renderings of novel views. We extract these semantic features using a pre-trained visual encoder such as CLIP, a Vision Transformer trained on hundreds of millions of diverse 2D photographs mined from the web with natural language supervision. Experiments indicate that our proposed method can produce plausible completions of unobserved regions while preserving the features of the scene. When trained across various scenes, 360FusionNeRF consistently achieves the state-of-the-art performance when transferring to synthetic Structured3D dataset (PSNR~5%, SSIM~3% LPIPS~13%), real-world Matterport3D dataset (PSNR~3%, SSIM~3% LPIPS~9%) and Replica360 dataset (PSNR~8%, SSIM~2% LPIPS~18%).
CrackSeg9k: A Collection and Benchmark for Crack Segmentation Datasets and Frameworks
Aug 27, 2022
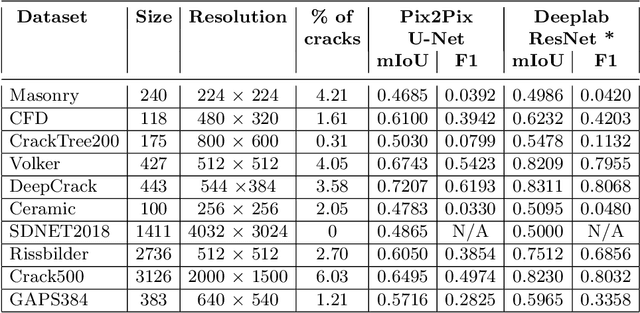

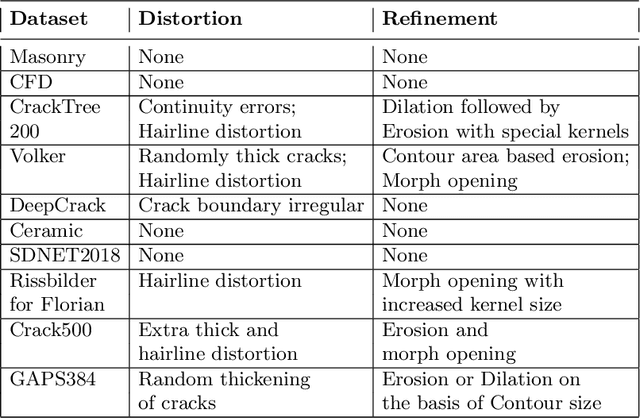
The detection of cracks is a crucial task in monitoring structural health and ensuring structural safety. The manual process of crack detection is time-consuming and subjective to the inspectors. Several researchers have tried tackling this problem using traditional Image Processing or learning-based techniques. However, their scope of work is limited to detecting cracks on a single type of surface (walls, pavements, glass, etc.). The metrics used to evaluate these methods are also varied across the literature, making it challenging to compare techniques. This paper addresses these problems by combining previously available datasets and unifying the annotations by tackling the inherent problems within each dataset, such as noise and distortions. We also present a pipeline that combines Image Processing and Deep Learning models. Finally, we benchmark the results of proposed models on these metrics on our new dataset and compare them with state-of-the-art models in the literature.
Balancing Discriminability and Transferability for Source-Free Domain Adaptation
Jun 16, 2022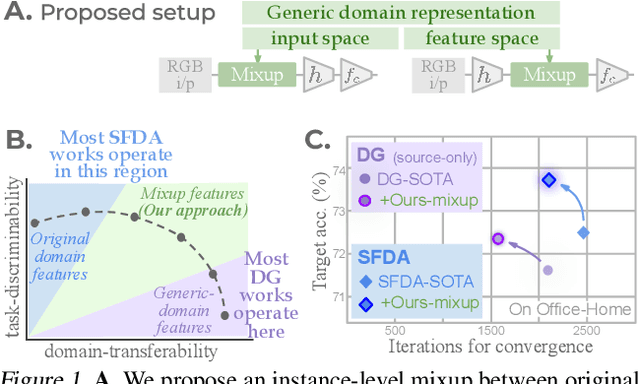
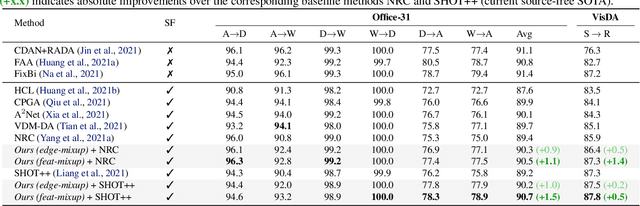
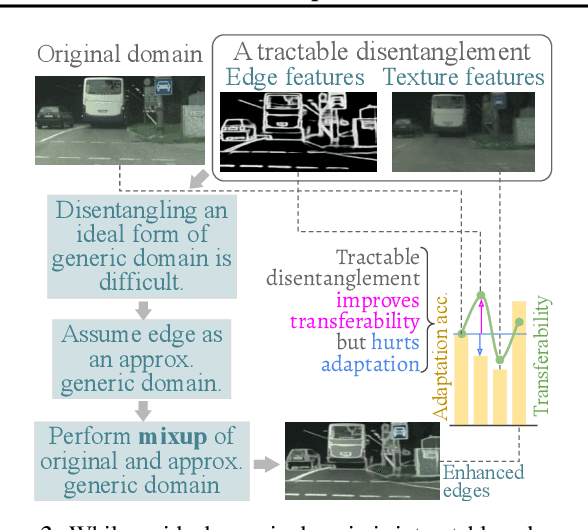
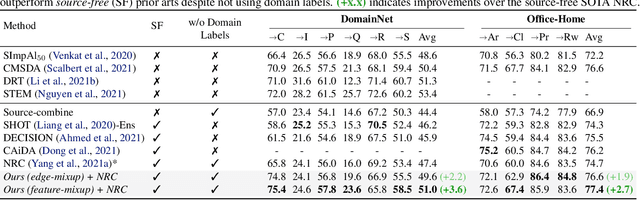
Conventional domain adaptation (DA) techniques aim to improve domain transferability by learning domain-invariant representations; while concurrently preserving the task-discriminability knowledge gathered from the labeled source data. However, the requirement of simultaneous access to labeled source and unlabeled target renders them unsuitable for the challenging source-free DA setting. The trivial solution of realizing an effective original to generic domain mapping improves transferability but degrades task discriminability. Upon analyzing the hurdles from both theoretical and empirical standpoints, we derive novel insights to show that a mixup between original and corresponding translated generic samples enhances the discriminability-transferability trade-off while duly respecting the privacy-oriented source-free setting. A simple but effective realization of the proposed insights on top of the existing source-free DA approaches yields state-of-the-art performance with faster convergence. Beyond single-source, we also outperform multi-source prior-arts across both classification and semantic segmentation benchmarks.