 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge360FusionNeRF: Panoramic Neural Radiance Fields with Joint Guidance
Paper and Code

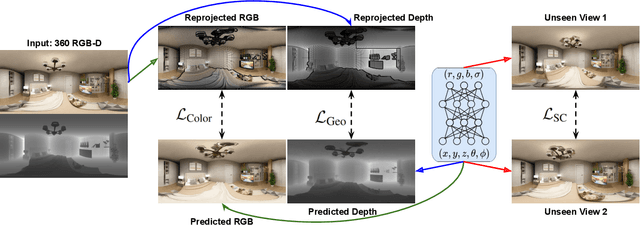

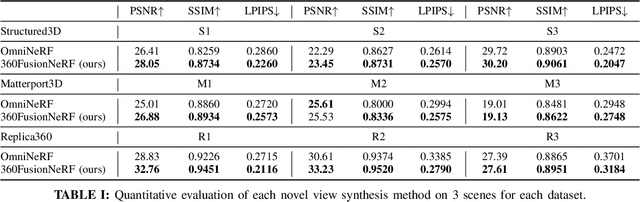
We present a method to synthesize novel views from a single $360^\circ$ panorama image based on the neural radiance field (NeRF). Prior studies in a similar setting rely on the neighborhood interpolation capability of multi-layer perceptions to complete missing regions caused by occlusion, which leads to artifacts in their predictions. We propose 360FusionNeRF, a semi-supervised learning framework where we introduce geometric supervision and semantic consistency to guide the progressive training process. Firstly, the input image is re-projected to $360^\circ$ images, and auxiliary depth maps are extracted at other camera positions. The depth supervision, in addition to the NeRF color guidance, improves the geometry of the synthesized views. Additionally, we introduce a semantic consistency loss that encourages realistic renderings of novel views. We extract these semantic features using a pre-trained visual encoder such as CLIP, a Vision Transformer trained on hundreds of millions of diverse 2D photographs mined from the web with natural language supervision. Experiments indicate that our proposed method can produce plausible completions of unobserved regions while preserving the features of the scene. When trained across various scenes, 360FusionNeRF consistently achieves the state-of-the-art performance when transferring to synthetic Structured3D dataset (PSNR~5%, SSIM~3% LPIPS~13%), real-world Matterport3D dataset (PSNR~3%, SSIM~3% LPIPS~9%) and Replica360 dataset (PSNR~8%, SSIM~2% LPIPS~18%).