 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Act: Distribution-Guided Debiasing in Diffusion Models
Feb 28, 2024Diffusion Models (DMs) have emerged as powerful generative models with unprecedented image generation capability. These models are widely used for data augmentation and creative applications. However, DMs reflect the biases present in the training datasets. This is especially concerning in the context of faces, where the DM prefers one demographic subgroup vs others (eg. female vs male). In this work, we present a method for debiasing DMs without relying on additional data or model retraining. Specifically, we propose Distribution Guidance, which enforces the generated images to follow the prescribed attribute distribution. To realize this, we build on the key insight that the latent features of denoising UNet hold rich demographic semantics, and the same can be leveraged to guide debiased generation. We train Attribute Distribution Predictor (ADP) - a small mlp that maps the latent features to the distribution of attributes. ADP is trained with pseudo labels generated from existing attribute classifiers. The proposed Distribution Guidance with ADP enables us to do fair generation. Our method reduces bias across single/multiple attributes and outperforms the baseline by a significant margin for unconditional and text-conditional diffusion models. Further, we present a downstream task of training a fair attribute classifier by rebalancing the training set with our generated data.
Aligning Non-Causal Factors for Transformer-Based Source-Free Domain Adaptation
Nov 27, 2023
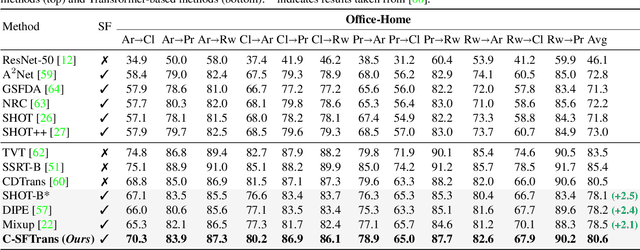


Conventional domain adaptation algorithms aim to achieve better generalization by aligning only the task-discriminative causal factors between a source and target domain. However, we find that retaining the spurious correlation between causal and non-causal factors plays a vital role in bridging the domain gap and improving target adaptation. Therefore, we propose to build a framework that disentangles and supports causal factor alignment by aligning the non-causal factors first. We also investigate and find that the strong shape bias of vision transformers, coupled with its multi-head attention, make it a suitable architecture for realizing our proposed disentanglement. Hence, we propose to build a Causality-enforcing Source-Free Transformer framework (C-SFTrans) to achieve disentanglement via a novel two-stage alignment approach: a) non-causal factor alignment: non-causal factors are aligned using a style classification task which leads to an overall global alignment, b) task-discriminative causal factor alignment: causal factors are aligned via target adaptation. We are the first to investigate the role of vision transformers (ViTs) in a privacy-preserving source-free setting. Our approach achieves state-of-the-art results in several DA benchmarks.
Domain-Specificity Inducing Transformers for Source-Free Domain Adaptation
Aug 27, 2023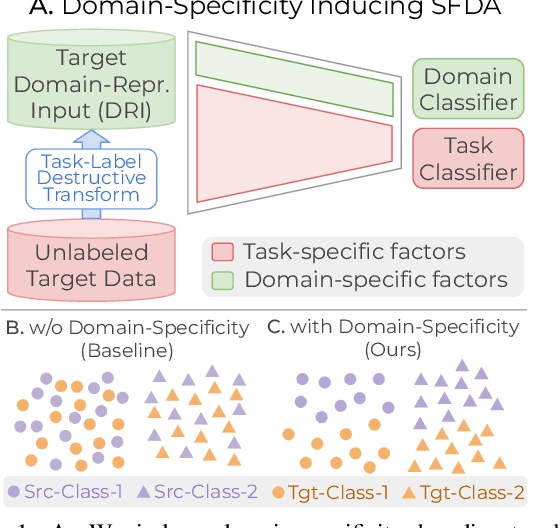
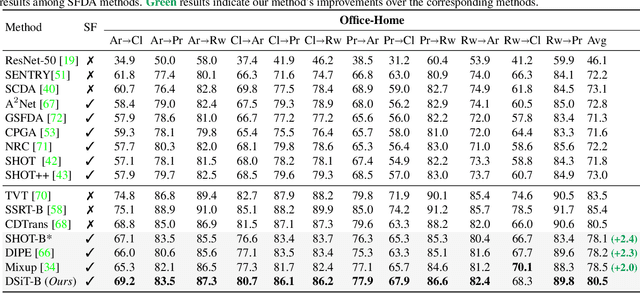
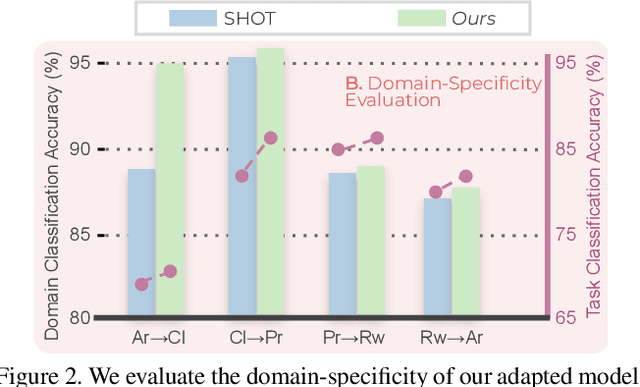

Conventional Domain Adaptation (DA) methods aim to learn domain-invariant feature representations to improve the target adaptation performance. However, we motivate that domain-specificity is equally important since in-domain trained models hold crucial domain-specific properties that are beneficial for adaptation. Hence, we propose to build a framework that supports disentanglement and learning of domain-specific factors and task-specific factors in a unified model. Motivated by the success of vision transformers in several multi-modal vision problems, we find that queries could be leveraged to extract the domain-specific factors. Hence, we propose a novel Domain-specificity-inducing Transformer (DSiT) framework for disentangling and learning both domain-specific and task-specific factors. To achieve disentanglement, we propose to construct novel Domain-Representative Inputs (DRI) with domain-specific information to train a domain classifier with a novel domain token. We are the first to utilize vision transformers for domain adaptation in a privacy-oriented source-free setting, and our approach achieves state-of-the-art performance on single-source, multi-source, and multi-target benchmarks
Subsidiary Prototype Alignment for Universal Domain Adaptation
Oct 28, 2022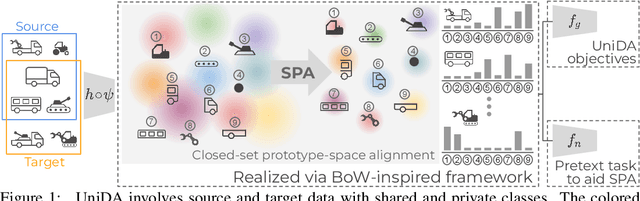
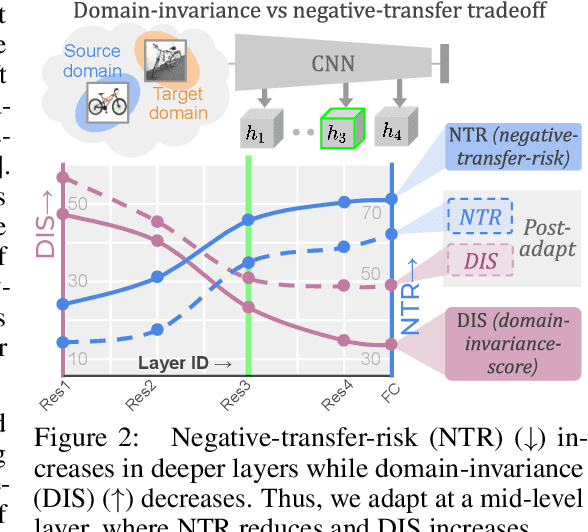
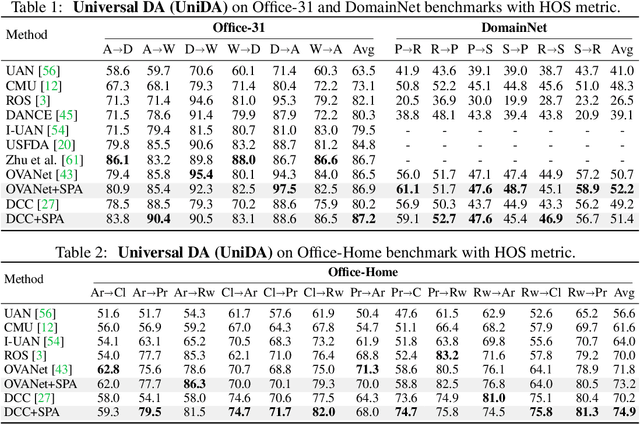
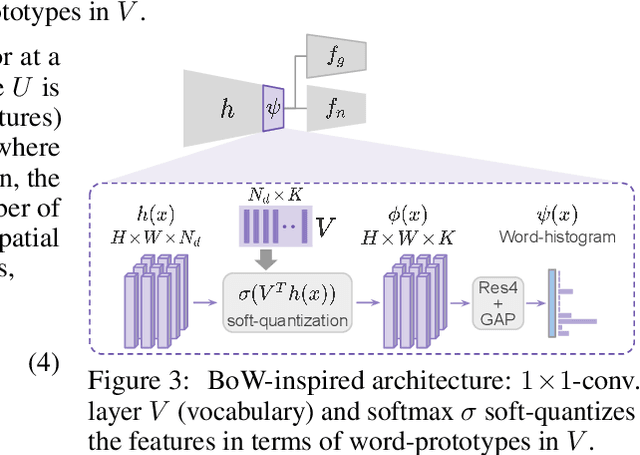
Universal Domain Adaptation (UniDA) deals with the problem of knowledge transfer between two datasets with domain-shift as well as category-shift. The goal is to categorize unlabeled target samples, either into one of the "known" categories or into a single "unknown" category. A major problem in UniDA is negative transfer, i.e. misalignment of "known" and "unknown" classes. To this end, we first uncover an intriguing tradeoff between negative-transfer-risk and domain-invariance exhibited at different layers of a deep network. It turns out we can strike a balance between these two metrics at a mid-level layer. Towards designing an effective framework based on this insight, we draw motivation from Bag-of-visual-Words (BoW). Word-prototypes in a BoW-like representation of a mid-level layer would represent lower-level visual primitives that are likely to be unaffected by the category-shift in the high-level features. We develop modifications that encourage learning of word-prototypes followed by word-histogram based classification. Following this, subsidiary prototype-space alignment (SPA) can be seen as a closed-set alignment problem, thereby avoiding negative transfer. We realize this with a novel word-histogram-related pretext task to enable closed-set SPA, operating in conjunction with goal task UniDA. We demonstrate the efficacy of our approach on top of existing UniDA techniques, yielding state-of-the-art performance across three standard UniDA and Open-Set DA object recognition benchmarks.
Concurrent Subsidiary Supervision for Unsupervised Source-Free Domain Adaptation
Jul 27, 2022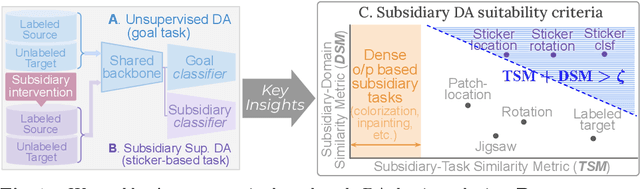
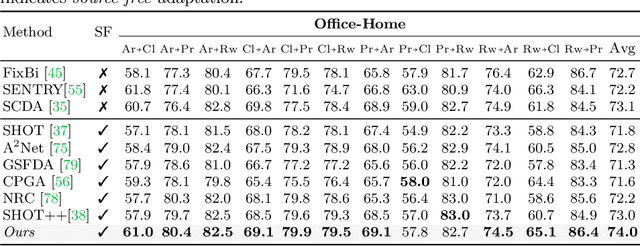
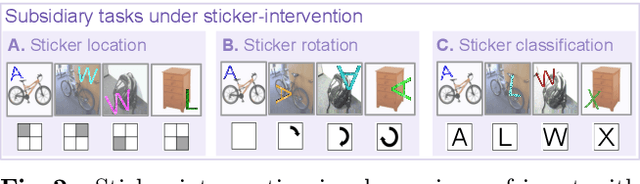
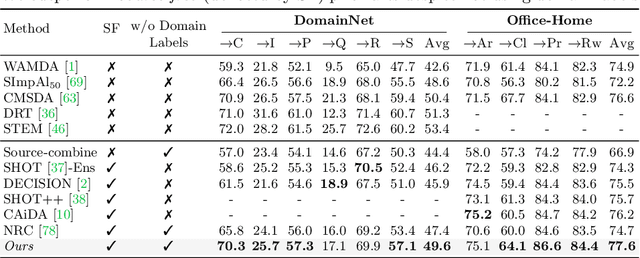
The prime challenge in unsupervised domain adaptation (DA) is to mitigate the domain shift between the source and target domains. Prior DA works show that pretext tasks could be used to mitigate this domain shift by learning domain invariant representations. However, in practice, we find that most existing pretext tasks are ineffective against other established techniques. Thus, we theoretically analyze how and when a subsidiary pretext task could be leveraged to assist the goal task of a given DA problem and develop objective subsidiary task suitability criteria. Based on this criteria, we devise a novel process of sticker intervention and cast sticker classification as a supervised subsidiary DA problem concurrent to the goal task unsupervised DA. Our approach not only improves goal task adaptation performance, but also facilitates privacy-oriented source-free DA i.e. without concurrent source-target access. Experiments on the standard Office-31, Office-Home, DomainNet, and VisDA benchmarks demonstrate our superiority for both single-source and multi-source source-free DA. Our approach also complements existing non-source-free works, achieving leading performance.
Balancing Discriminability and Transferability for Source-Free Domain Adaptation
Jun 16, 2022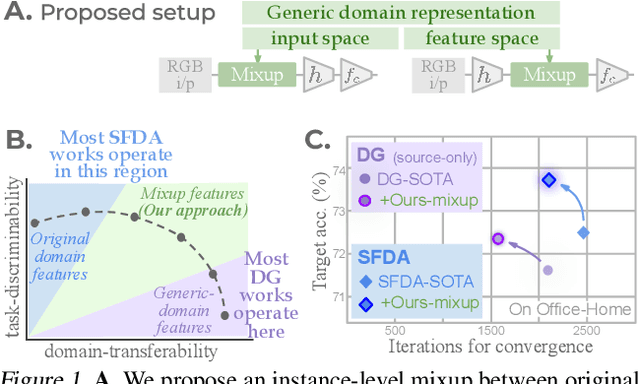
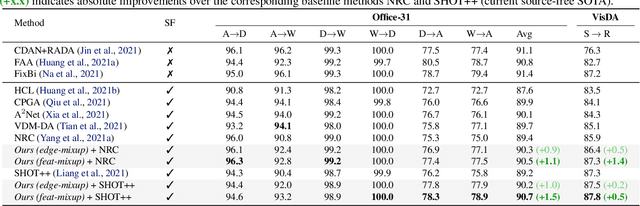
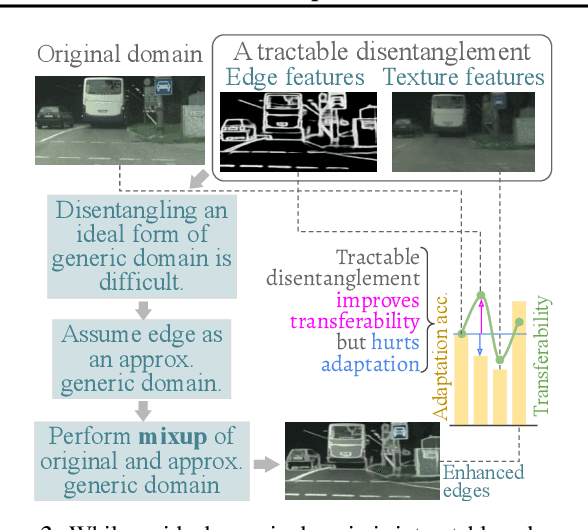
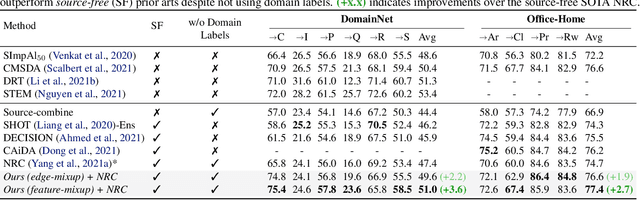
Conventional domain adaptation (DA) techniques aim to improve domain transferability by learning domain-invariant representations; while concurrently preserving the task-discriminability knowledge gathered from the labeled source data. However, the requirement of simultaneous access to labeled source and unlabeled target renders them unsuitable for the challenging source-free DA setting. The trivial solution of realizing an effective original to generic domain mapping improves transferability but degrades task discriminability. Upon analyzing the hurdles from both theoretical and empirical standpoints, we derive novel insights to show that a mixup between original and corresponding translated generic samples enhances the discriminability-transferability trade-off while duly respecting the privacy-oriented source-free setting. A simple but effective realization of the proposed insights on top of the existing source-free DA approaches yields state-of-the-art performance with faster convergence. Beyond single-source, we also outperform multi-source prior-arts across both classification and semantic segmentation benchmarks.
Non-Local Latent Relation Distillation for Self-Adaptive 3D Human Pose Estimation
Apr 06, 2022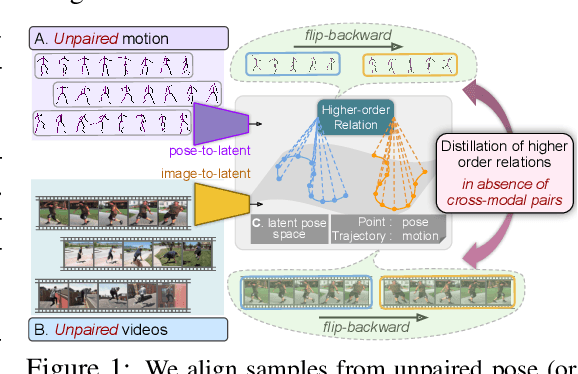
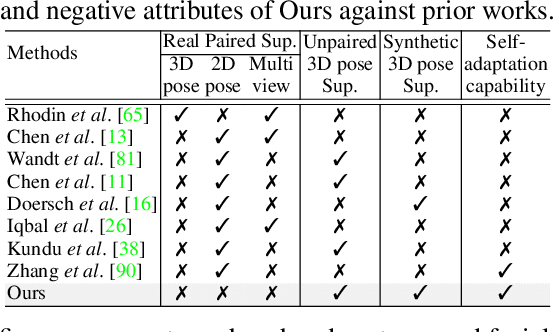
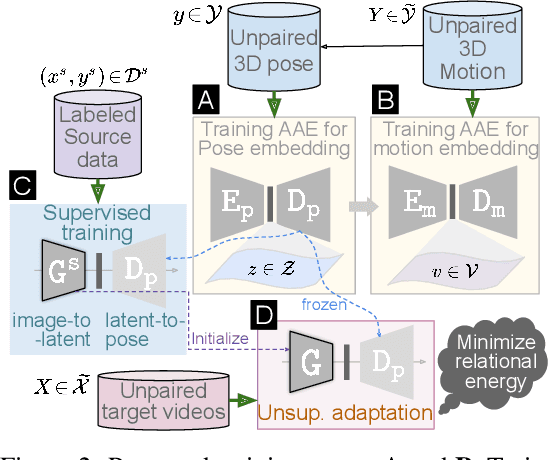
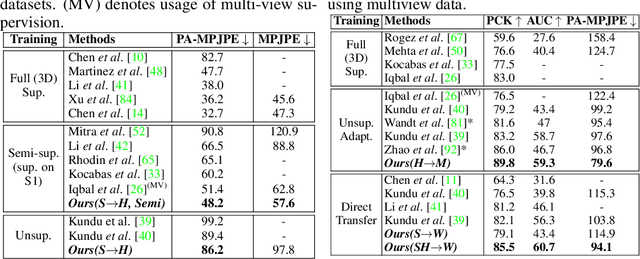
Available 3D human pose estimation approaches leverage different forms of strong (2D/3D pose) or weak (multi-view or depth) paired supervision. Barring synthetic or in-studio domains, acquiring such supervision for each new target environment is highly inconvenient. To this end, we cast 3D pose learning as a self-supervised adaptation problem that aims to transfer the task knowledge from a labeled source domain to a completely unpaired target. We propose to infer image-to-pose via two explicit mappings viz. image-to-latent and latent-to-pose where the latter is a pre-learned decoder obtained from a prior-enforcing generative adversarial auto-encoder. Next, we introduce relation distillation as a means to align the unpaired cross-modal samples i.e. the unpaired target videos and unpaired 3D pose sequences. To this end, we propose a new set of non-local relations in order to characterize long-range latent pose interactions unlike general contrastive relations where positive couplings are limited to a local neighborhood structure. Further, we provide an objective way to quantify non-localness in order to select the most effective relation set. We evaluate different self-adaptation settings and demonstrate state-of-the-art 3D human pose estimation performance on standard benchmarks.
Aligning Silhouette Topology for Self-Adaptive 3D Human Pose Recovery
Apr 04, 2022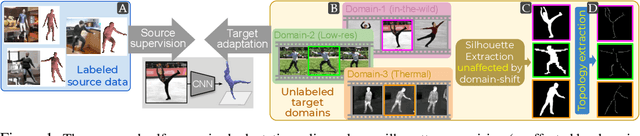
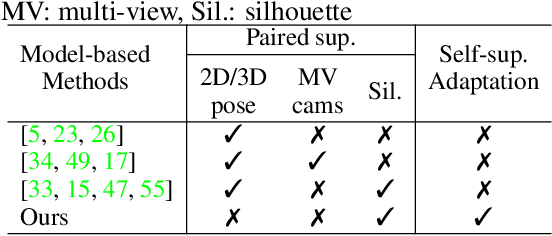
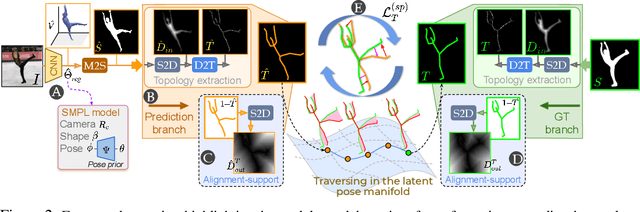
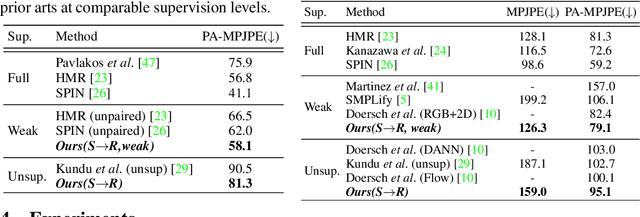
Articulation-centric 2D/3D pose supervision forms the core training objective in most existing 3D human pose estimation techniques. Except for synthetic source environments, acquiring such rich supervision for each real target domain at deployment is highly inconvenient. However, we realize that standard foreground silhouette estimation techniques (on static camera feeds) remain unaffected by domain-shifts. Motivated by this, we propose a novel target adaptation framework that relies only on silhouette supervision to adapt a source-trained model-based regressor. However, in the absence of any auxiliary cue (multi-view, depth, or 2D pose), an isolated silhouette loss fails to provide a reliable pose-specific gradient and requires to be employed in tandem with a topology-centric loss. To this end, we develop a series of convolution-friendly spatial transformations in order to disentangle a topological-skeleton representation from the raw silhouette. Such a design paves the way to devise a Chamfer-inspired spatial topological-alignment loss via distance field computation, while effectively avoiding any gradient hindering spatial-to-pointset mapping. Experimental results demonstrate our superiority against prior-arts in self-adapting a source trained model to diverse unlabeled target domains, such as a) in-the-wild datasets, b) low-resolution image domains, and c) adversarially perturbed image domains (via UAP).
Uncertainty-Aware Adaptation for Self-Supervised 3D Human Pose Estimation
Mar 29, 2022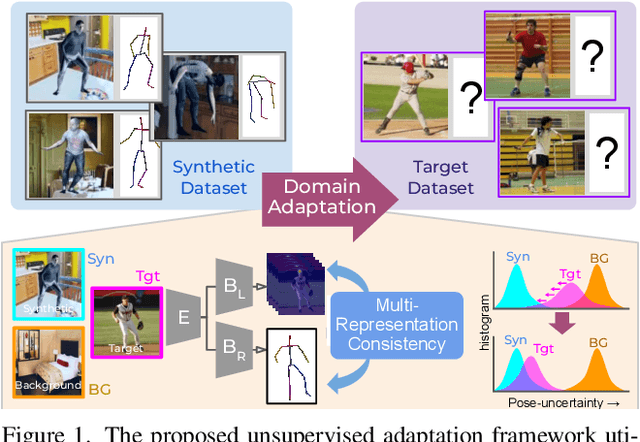

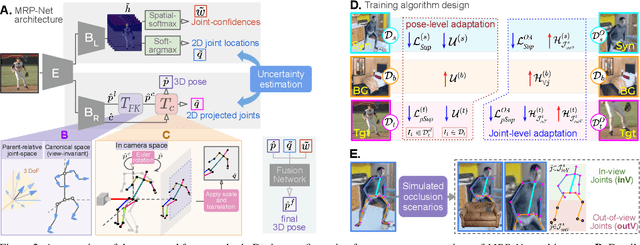
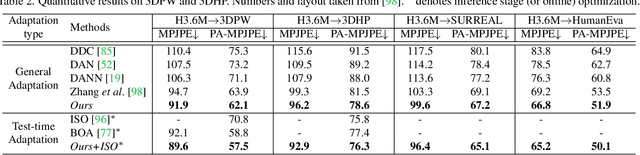
The advances in monocular 3D human pose estimation are dominated by supervised techniques that require large-scale 2D/3D pose annotations. Such methods often behave erratically in the absence of any provision to discard unfamiliar out-of-distribution data. To this end, we cast the 3D human pose learning as an unsupervised domain adaptation problem. We introduce MRP-Net that constitutes a common deep network backbone with two output heads subscribing to two diverse configurations; a) model-free joint localization and b) model-based parametric regression. Such a design allows us to derive suitable measures to quantify prediction uncertainty at both pose and joint level granularity. While supervising only on labeled synthetic samples, the adaptation process aims to minimize the uncertainty for the unlabeled target images while maximizing the same for an extreme out-of-distribution dataset (backgrounds). Alongside synthetic-to-real 3D pose adaptation, the joint-uncertainties allow expanding the adaptation to work on in-the-wild images even in the presence of occlusion and truncation scenarios. We present a comprehensive evaluation of the proposed approach and demonstrate state-of-the-art performance on benchmark datasets.
Amplitude Spectrum Transformation for Open Compound Domain Adaptive Semantic Segmentation
Feb 09, 2022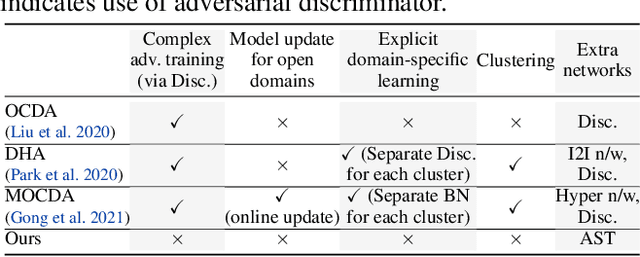
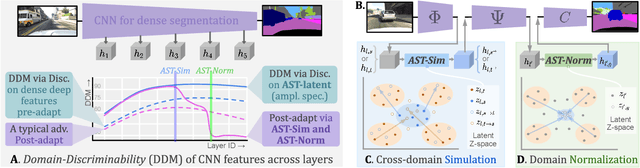
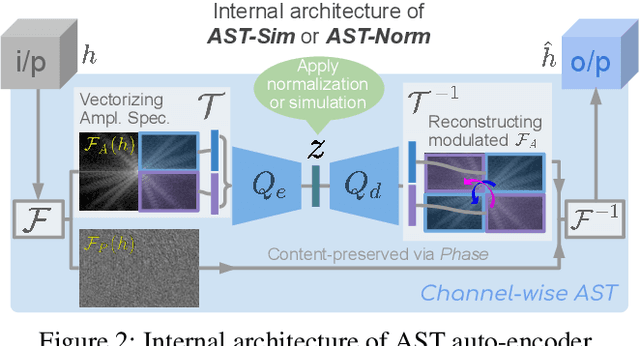
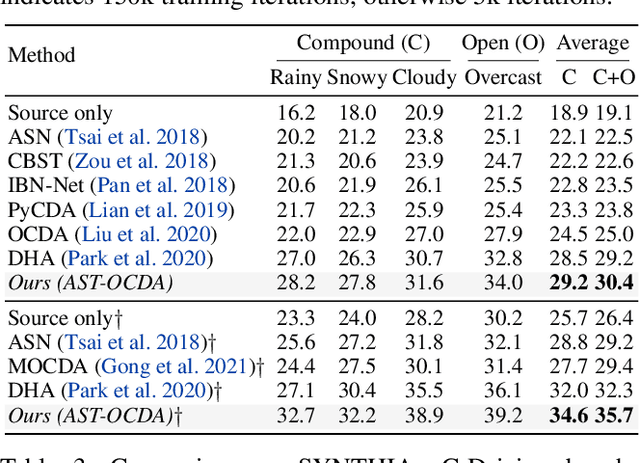
Open compound domain adaptation (OCDA) has emerged as a practical adaptation setting which considers a single labeled source domain against a compound of multi-modal unlabeled target data in order to generalize better on novel unseen domains. We hypothesize that an improved disentanglement of domain-related and task-related factors of dense intermediate layer features can greatly aid OCDA. Prior-arts attempt this indirectly by employing adversarial domain discriminators on the spatial CNN output. However, we find that latent features derived from the Fourier-based amplitude spectrum of deep CNN features hold a more tractable mapping with domain discrimination. Motivated by this, we propose a novel feature space Amplitude Spectrum Transformation (AST). During adaptation, we employ the AST auto-encoder for two purposes. First, carefully mined source-target instance pairs undergo a simulation of cross-domain feature stylization (AST-Sim) at a particular layer by altering the AST-latent. Second, AST operating at a later layer is tasked to normalize (AST-Norm) the domain content by fixing its latent to a mean prototype. Our simplified adaptation technique is not only clustering-free but also free from complex adversarial alignment. We achieve leading performance against the prior arts on the OCDA scene segmentation benchmarks.