 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Silhouette Topology for Self-Adaptive 3D Human Pose Recovery
Apr 04, 2022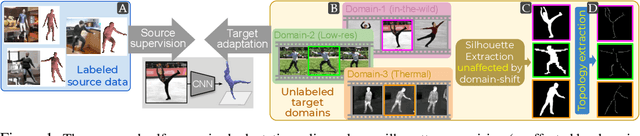
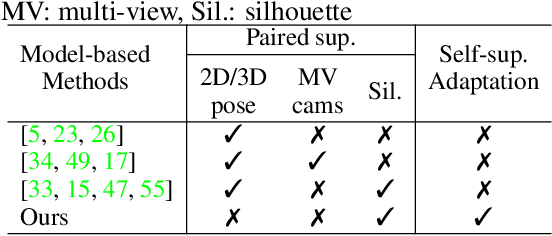
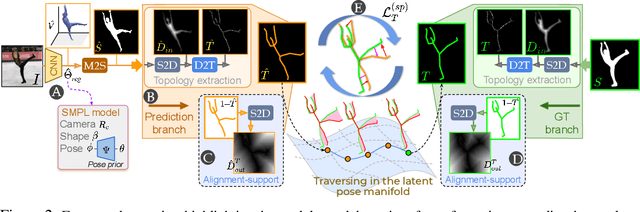
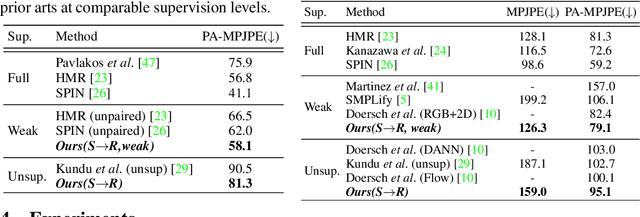
Articulation-centric 2D/3D pose supervision forms the core training objective in most existing 3D human pose estimation techniques. Except for synthetic source environments, acquiring such rich supervision for each real target domain at deployment is highly inconvenient. However, we realize that standard foreground silhouette estimation techniques (on static camera feeds) remain unaffected by domain-shifts. Motivated by this, we propose a novel target adaptation framework that relies only on silhouette supervision to adapt a source-trained model-based regressor. However, in the absence of any auxiliary cue (multi-view, depth, or 2D pose), an isolated silhouette loss fails to provide a reliable pose-specific gradient and requires to be employed in tandem with a topology-centric loss. To this end, we develop a series of convolution-friendly spatial transformations in order to disentangle a topological-skeleton representation from the raw silhouette. Such a design paves the way to devise a Chamfer-inspired spatial topological-alignment loss via distance field computation, while effectively avoiding any gradient hindering spatial-to-pointset mapping. Experimental results demonstrate our superiority against prior-arts in self-adapting a source trained model to diverse unlabeled target domains, such as a) in-the-wild datasets, b) low-resolution image domains, and c) adversarially perturbed image domains (via UAP).
Appearance Consensus Driven Self-Supervised Human Mesh Recovery
Aug 04, 2020



We present a self-supervised human mesh recovery framework to infer human pose and shape from monocular images in the absence of any paired supervision. Recent advances have shifted the interest towards directly regressing parameters of a parametric human model by supervising them on large-scale datasets with 2D landmark annotations. This limits the generalizability of such approaches to operate on images from unlabeled wild environments. Acknowledging this we propose a novel appearance consensus driven self-supervised objective. To effectively disentangle the foreground (FG) human we rely on image pairs depicting the same person (consistent FG) in varied pose and background (BG) which are obtained from unlabeled wild videos. The proposed FG appearance consistency objective makes use of a novel, differentiable Color-recovery module to obtain vertex colors without the need for any appearance network; via efficient realization of color-picking and reflectional symmetry. We achieve state-of-the-art results on the standard model-based 3D pose estimation benchmarks at comparable supervision levels. Furthermore, the resulting colored mesh prediction opens up the usage of our framework for a variety of appearance-related tasks beyond the pose and shape estimation, thus establishing our superior generalizability.
Kinematic-Structure-Preserved Representation for Unsupervised 3D Human Pose Estimation
Jun 24, 2020
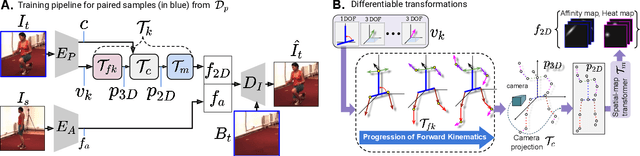
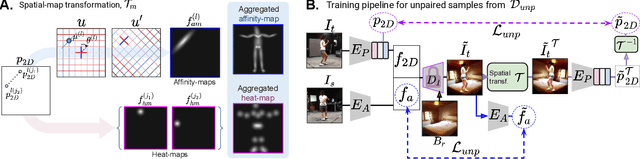
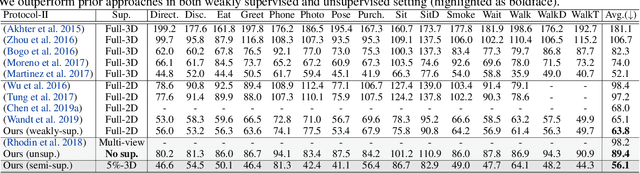
Estimation of 3D human pose from monocular image has gained considerable attention, as a key step to several human-centric applications. However, generalizability of human pose estimation models developed using supervision on large-scale in-studio datasets remains questionable, as these models often perform unsatisfactorily on unseen in-the-wild environments. Though weakly-supervised models have been proposed to address this shortcoming, performance of such models relies on availability of paired supervision on some related tasks, such as 2D pose or multi-view image pairs. In contrast, we propose a novel kinematic-structure-preserved unsupervised 3D pose estimation framework, which is not restrained by any paired or unpaired weak supervisions. Our pose estimation framework relies on a minimal set of prior knowledge that defines the underlying kinematic 3D structure, such as skeletal joint connectivity information with bone-length ratios in a fixed canonical scale. The proposed model employs three consecutive differentiable transformations named as forward-kinematics, camera-projection and spatial-map transformation. This design not only acts as a suitable bottleneck stimulating effective pose disentanglement but also yields interpretable latent pose representations avoiding training of an explicit latent embedding to pose mapper. Furthermore, devoid of unstable adversarial setup, we re-utilize the decoder to formalize an energy-based loss, which enables us to learn from in-the-wild videos, beyond laboratory settings. Comprehensive experiments demonstrate our state-of-the-art unsupervised and weakly-supervised pose estimation performance on both Human3.6M and MPI-INF-3DHP datasets. Qualitative results on unseen environments further establish our superior generalization ability.
Self-Supervised 3D Human Pose Estimation via Part Guided Novel Image Synthesis
Apr 09, 2020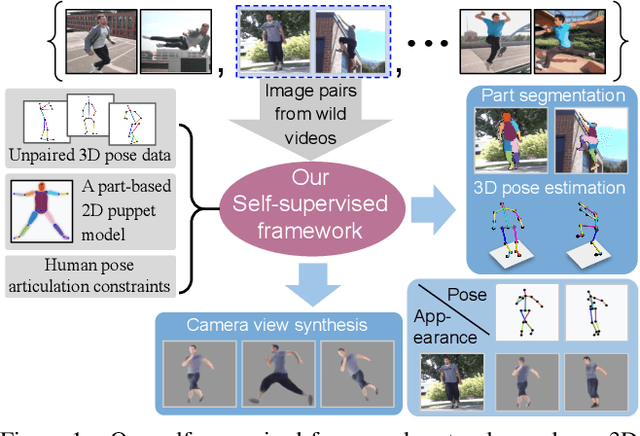


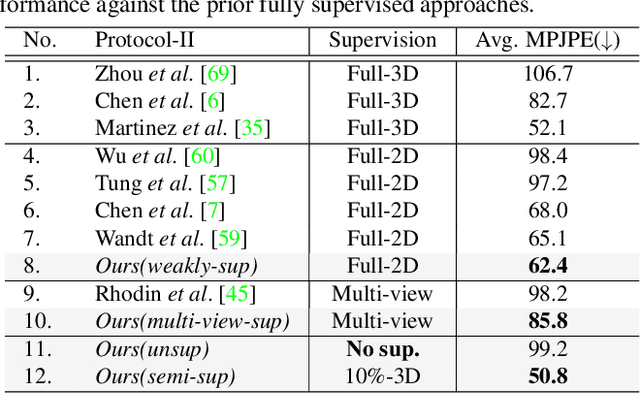
Camera captured human pose is an outcome of several sources of variation. Performance of supervised 3D pose estimation approaches comes at the cost of dispensing with variations, such as shape and appearance, that may be useful for solving other related tasks. As a result, the learned model not only inculcates task-bias but also dataset-bias because of its strong reliance on the annotated samples, which also holds true for weakly-supervised models. Acknowledging this, we propose a self-supervised learning framework to disentangle such variations from unlabeled video frames. We leverage the prior knowledge on human skeleton and poses in the form of a single part-based 2D puppet model, human pose articulation constraints, and a set of unpaired 3D poses. Our differentiable formalization, bridging the representation gap between the 3D pose and spatial part maps, not only facilitates discovery of interpretable pose disentanglement but also allows us to operate on videos with diverse camera movements. Qualitative results on unseen in-the-wild datasets establish our superior generalization across multiple tasks beyond the primary tasks of 3D pose estimation and part segmentation. Furthermore, we demonstrate state-of-the-art weakly-supervised 3D pose estimation performance on both Human3.6M and MPI-INF-3DHP datasets.