 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Scene Understanding Through Local Random Access Sequence Modeling
Apr 04, 20253D scene understanding from single images is a pivotal problem in computer vision with numerous downstream applications in graphics, augmented reality, and robotics. While diffusion-based modeling approaches have shown promise, they often struggle to maintain object and scene consistency, especially in complex real-world scenarios. To address these limitations, we propose an autoregressive generative approach called Local Random Access Sequence (LRAS) modeling, which uses local patch quantization and randomly ordered sequence generation. By utilizing optical flow as an intermediate representation for 3D scene editing, our experiments demonstrate that LRAS achieves state-of-the-art novel view synthesis and 3D object manipulation capabilities. Furthermore, we show that our framework naturally extends to self-supervised depth estimation through a simple modification of the sequence design. By achieving strong performance on multiple 3D scene understanding tasks, LRAS provides a unified and effective framework for building the next generation of 3D vision models.
Class-Incremental Domain Adaptation
Aug 04, 2020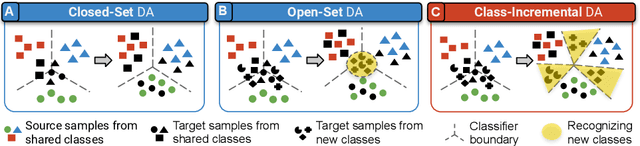
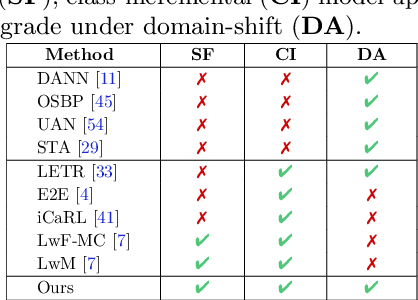
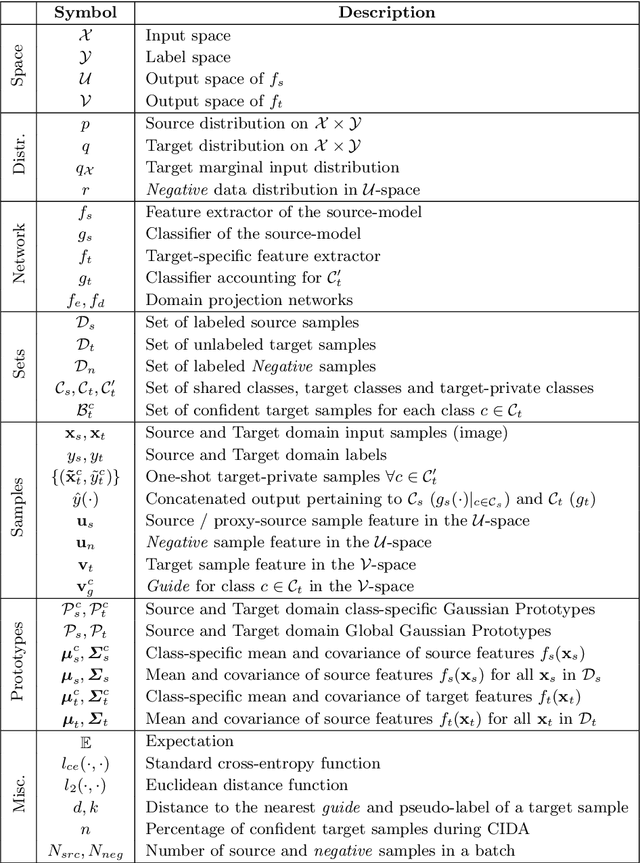

We introduce a practical Domain Adaptation (DA) paradigm called Class-Incremental Domain Adaptation (CIDA). Existing DA methods tackle domain-shift but are unsuitable for learning novel target-domain classes. Meanwhile, class-incremental (CI) methods enable learning of new classes in absence of source training data but fail under a domain-shift without labeled supervision. In this work, we effectively identify the limitations of these approaches in the CIDA paradigm. Motivated by theoretical and empirical observations, we propose an effective method, inspired by prototypical networks, that enables classification of target samples into both shared and novel (one-shot) target classes, even under a domain-shift. Our approach yields superior performance as compared to both DA and CI methods in the CIDA paradigm.
Unsupervised Cross-Modal Alignment for Multi-Person 3D Pose Estimation
Aug 04, 2020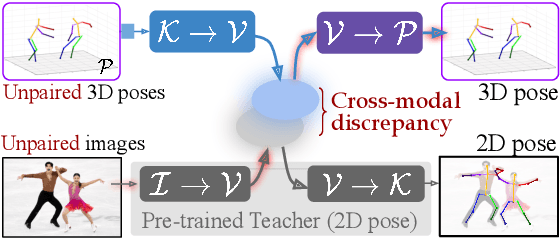

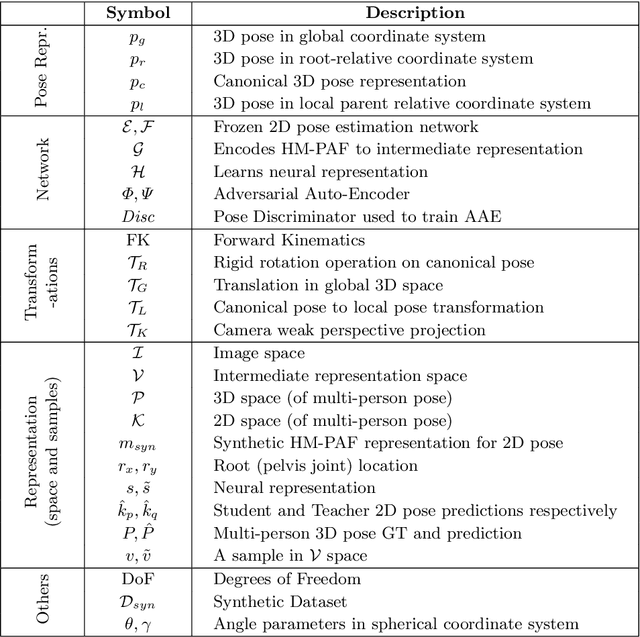
We present a deployment friendly, fast bottom-up framework for multi-person 3D human pose estimation. We adopt a novel neural representation of multi-person 3D pose which unifies the position of person instances with their corresponding 3D pose representation. This is realized by learning a generative pose embedding which not only ensures plausible 3D pose predictions, but also eliminates the usual keypoint grouping operation as employed in prior bottom-up approaches. Further, we propose a practical deployment paradigm where paired 2D or 3D pose annotations are unavailable. In the absence of any paired supervision, we leverage a frozen network, as a teacher model, which is trained on an auxiliary task of multi-person 2D pose estimation. We cast the learning as a cross-modal alignment problem and propose training objectives to realize a shared latent space between two diverse modalities. We aim to enhance the model's ability to perform beyond the limiting teacher network by enriching the latent-to-3D pose mapping using artificially synthesized multi-person 3D scene samples. Our approach not only generalizes to in-the-wild images, but also yields a superior trade-off between speed and performance, compared to prior top-down approaches. Our approach also yields state-of-the-art multi-person 3D pose estimation performance among the bottom-up approaches under consistent supervision levels.
Appearance Consensus Driven Self-Supervised Human Mesh Recovery
Aug 04, 2020



We present a self-supervised human mesh recovery framework to infer human pose and shape from monocular images in the absence of any paired supervision. Recent advances have shifted the interest towards directly regressing parameters of a parametric human model by supervising them on large-scale datasets with 2D landmark annotations. This limits the generalizability of such approaches to operate on images from unlabeled wild environments. Acknowledging this we propose a novel appearance consensus driven self-supervised objective. To effectively disentangle the foreground (FG) human we rely on image pairs depicting the same person (consistent FG) in varied pose and background (BG) which are obtained from unlabeled wild videos. The proposed FG appearance consistency objective makes use of a novel, differentiable Color-recovery module to obtain vertex colors without the need for any appearance network; via efficient realization of color-picking and reflectional symmetry. We achieve state-of-the-art results on the standard model-based 3D pose estimation benchmarks at comparable supervision levels. Furthermore, the resulting colored mesh prediction opens up the usage of our framework for a variety of appearance-related tasks beyond the pose and shape estimation, thus establishing our superior generalizability.