 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-biased Transformers for Novel View Synthesis
Jan 11, 2023



We tackle the task of synthesizing novel views of an object given a few input images and associated camera viewpoints. Our work is inspired by recent 'geometry-free' approaches where multi-view images are encoded as a (global) set-latent representation, which is then used to predict the color for arbitrary query rays. While this representation yields (coarsely) accurate images corresponding to novel viewpoints, the lack of geometric reasoning limits the quality of these outputs. To overcome this limitation, we propose 'Geometry-biased Transformers' (GBTs) that incorporate geometric inductive biases in the set-latent representation-based inference to encourage multi-view geometric consistency. We induce the geometric bias by augmenting the dot-product attention mechanism to also incorporate 3D distances between rays associated with tokens as a learnable bias. We find that this, along with camera-aware embeddings as input, allows our models to generate significantly more accurate outputs. We validate our approach on the real-world CO3D dataset, where we train our system over 10 categories and evaluate its view-synthesis ability for novel objects as well as unseen categories. We empirically validate the benefits of the proposed geometric biases and show that our approach significantly improves over prior works.
Your Classifier can Secretly Suffice Multi-Source Domain Adaptation
Mar 20, 2021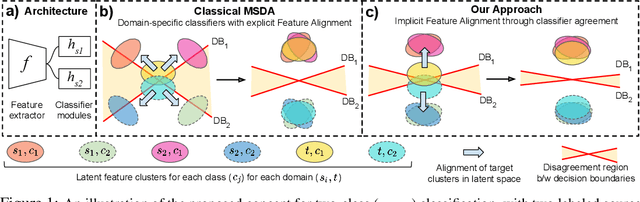
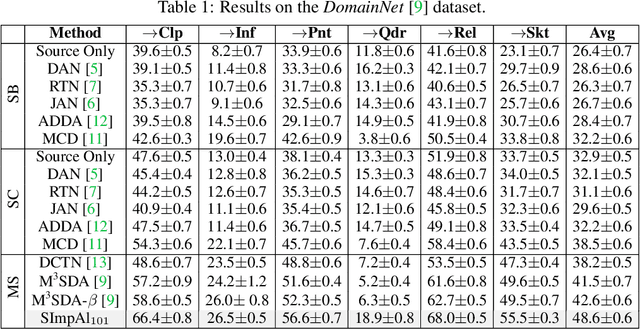
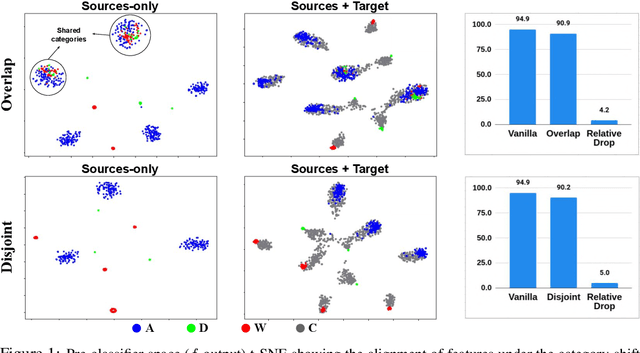
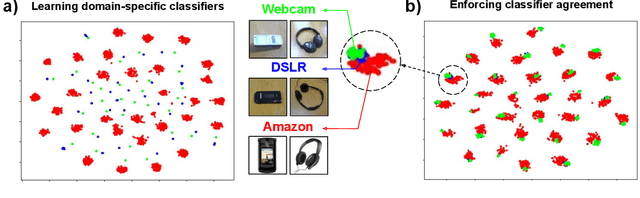
Multi-Source Domain Adaptation (MSDA) deals with the transfer of task knowledge from multiple labeled source domains to an unlabeled target domain, under a domain-shift. Existing methods aim to minimize this domain-shift using auxiliary distribution alignment objectives. In this work, we present a different perspective to MSDA wherein deep models are observed to implicitly align the domains under label supervision. Thus, we aim to utilize implicit alignment without additional training objectives to perform adaptation. To this end, we use pseudo-labeled target samples and enforce a classifier agreement on the pseudo-labels, a process called Self-supervised Implicit Alignment (SImpAl). We find that SImpAl readily works even under category-shift among the source domains. Further, we propose classifier agreement as a cue to determine the training convergence, resulting in a simple training algorithm. We provide a thorough evaluation of our approach on five benchmarks, along with detailed insights into each component of our approach.
Class-Incremental Domain Adaptation
Aug 04, 2020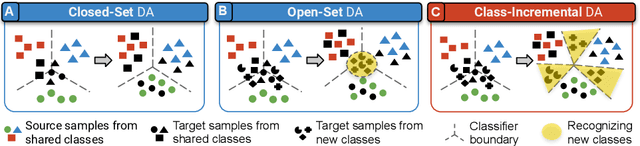
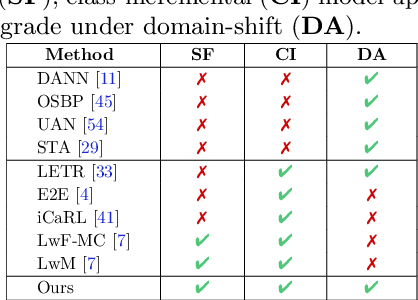
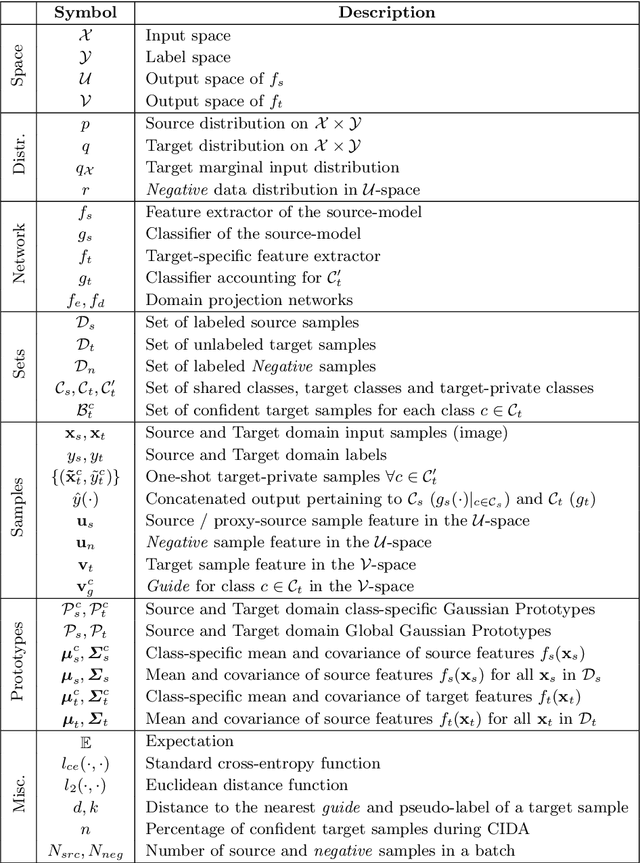

We introduce a practical Domain Adaptation (DA) paradigm called Class-Incremental Domain Adaptation (CIDA). Existing DA methods tackle domain-shift but are unsuitable for learning novel target-domain classes. Meanwhile, class-incremental (CI) methods enable learning of new classes in absence of source training data but fail under a domain-shift without labeled supervision. In this work, we effectively identify the limitations of these approaches in the CIDA paradigm. Motivated by theoretical and empirical observations, we propose an effective method, inspired by prototypical networks, that enables classification of target samples into both shared and novel (one-shot) target classes, even under a domain-shift. Our approach yields superior performance as compared to both DA and CI methods in the CIDA paradigm.
Universal Source-Free Domain Adaptation
Apr 09, 2020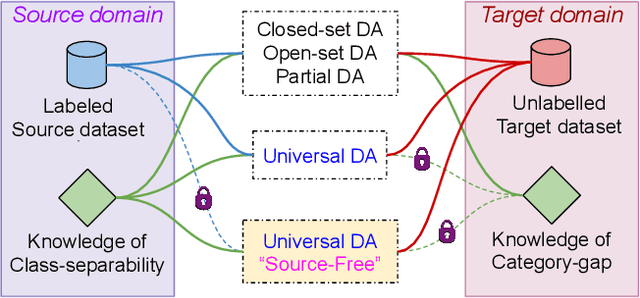
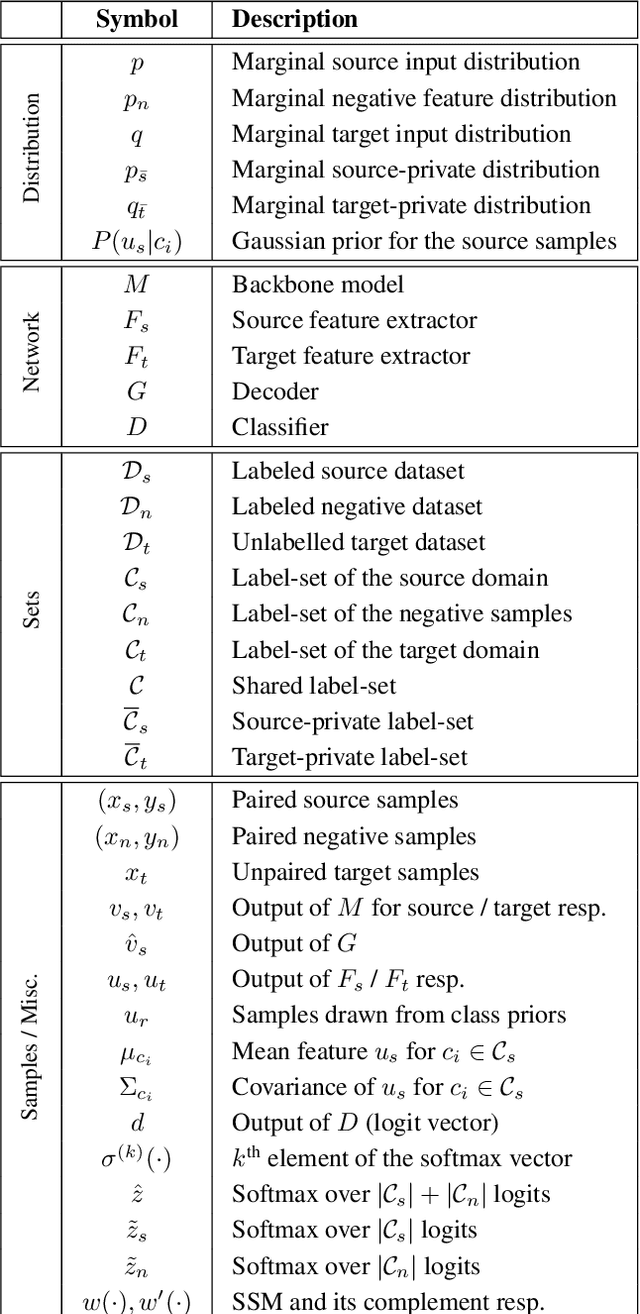
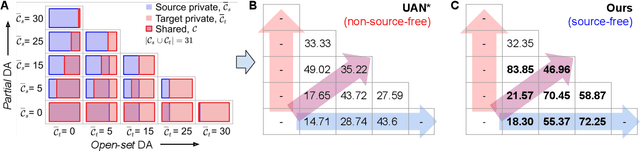
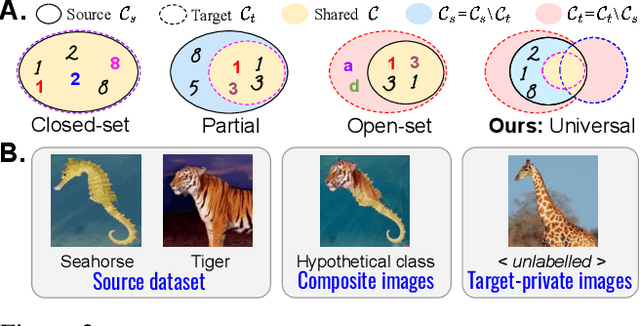
There is a strong incentive to develop versatile learning techniques that can transfer the knowledge of class-separability from a labeled source domain to an unlabeled target domain in the presence of a domain-shift. Existing domain adaptation (DA) approaches are not equipped for practical DA scenarios as a result of their reliance on the knowledge of source-target label-set relationship (e.g. Closed-set, Open-set or Partial DA). Furthermore, almost all prior unsupervised DA works require coexistence of source and target samples even during deployment, making them unsuitable for real-time adaptation. Devoid of such impractical assumptions, we propose a novel two-stage learning process. 1) In the Procurement stage, we aim to equip the model for future source-free deployment, assuming no prior knowledge of the upcoming category-gap and domain-shift. To achieve this, we enhance the model's ability to reject out-of-source distribution samples by leveraging the available source data, in a novel generative classifier framework. 2) In the Deployment stage, the goal is to design a unified adaptation algorithm capable of operating across a wide range of category-gaps, with no access to the previously seen source samples. To this end, in contrast to the usage of complex adversarial training regimes, we define a simple yet effective source-free adaptation objective by utilizing a novel instance-level weighting mechanism, named as Source Similarity Metric (SSM). A thorough evaluation shows the practical usability of the proposed learning framework with superior DA performance even over state-of-the-art source-dependent approaches.
Towards Inheritable Models for Open-Set Domain Adaptation
Apr 09, 2020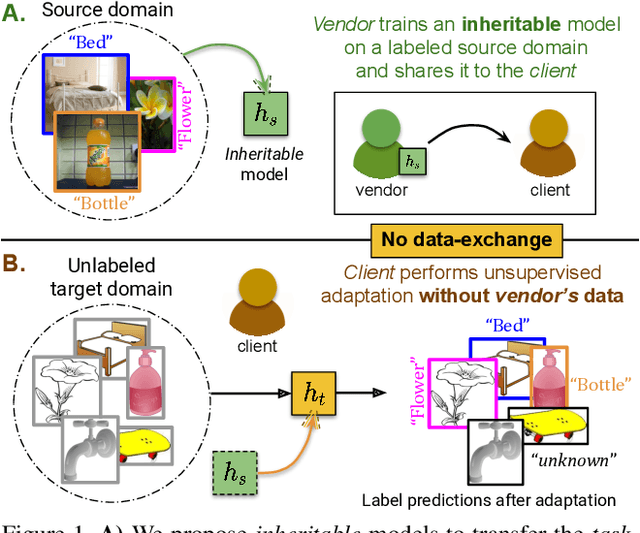
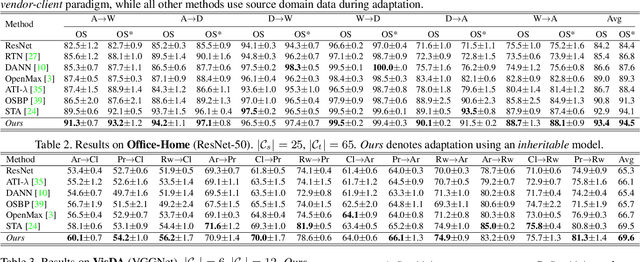


There has been a tremendous progress in Domain Adaptation (DA) for visual recognition tasks. Particularly, open-set DA has gained considerable attention wherein the target domain contains additional unseen categories. Existing open-set DA approaches demand access to a labeled source dataset along with unlabeled target instances. However, this reliance on co-existing source and target data is highly impractical in scenarios where data-sharing is restricted due to its proprietary nature or privacy concerns. Addressing this, we introduce a practical DA paradigm where a source-trained model is used to facilitate adaptation in the absence of the source dataset in future. To this end, we formalize knowledge inheritability as a novel concept and propose a simple yet effective solution to realize inheritable models suitable for the above practical paradigm. Further, we present an objective way to quantify inheritability to enable the selection of the most suitable source model for a given target domain, even in the absence of the source data. We provide theoretical insights followed by a thorough empirical evaluation demonstrating state-of-the-art open-set domain adaptation performance.