 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Set Object Detection By Aligning Known Class Representations
Dec 30, 2024



Open-Set Object Detection (OSOD) has emerged as a contemporary research direction to address the detection of unknown objects. Recently, few works have achieved remarkable performance in the OSOD task by employing contrastive clustering to separate unknown classes. In contrast, we propose a new semantic clustering-based approach to facilitate a meaningful alignment of clusters in semantic space and introduce a class decorrelation module to enhance inter-cluster separation. Our approach further incorporates an object focus module to predict objectness scores, which enhances the detection of unknown objects. Further, we employ i) an evaluation technique that penalizes low-confidence outputs to mitigate the risk of misclassification of the unknown objects and ii) a new metric called HMP that combines known and unknown precision using harmonic mean. Our extensive experiments demonstrate that the proposed model achieves significant improvement on the MS-COCO & PASCAL VOC dataset for the OSOD task.
Beyond Few-shot Object Detection: A Detailed Survey
Aug 26, 2024Object detection is a critical field in computer vision focusing on accurately identifying and locating specific objects in images or videos. Traditional methods for object detection rely on large labeled training datasets for each object category, which can be time-consuming and expensive to collect and annotate. To address this issue, researchers have introduced few-shot object detection (FSOD) approaches that merge few-shot learning and object detection principles. These approaches allow models to quickly adapt to new object categories with only a few annotated samples. While traditional FSOD methods have been studied before, this survey paper comprehensively reviews FSOD research with a specific focus on covering different FSOD settings such as standard FSOD, generalized FSOD, incremental FSOD, open-set FSOD, and domain adaptive FSOD. These approaches play a vital role in reducing the reliance on extensive labeled datasets, particularly as the need for efficient machine learning models continues to rise. This survey paper aims to provide a comprehensive understanding of the above-mentioned few-shot settings and explore the methodologies for each FSOD task. It thoroughly compares state-of-the-art methods across different FSOD settings, analyzing them in detail based on their evaluation protocols. Additionally, it offers insights into their applications, challenges, and potential future directions in the evolving field of object detection with limited data.
Subsidiary Prototype Alignment for Universal Domain Adaptation
Oct 28, 2022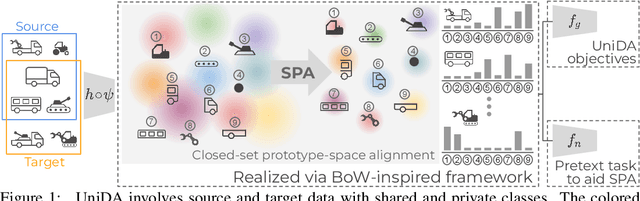
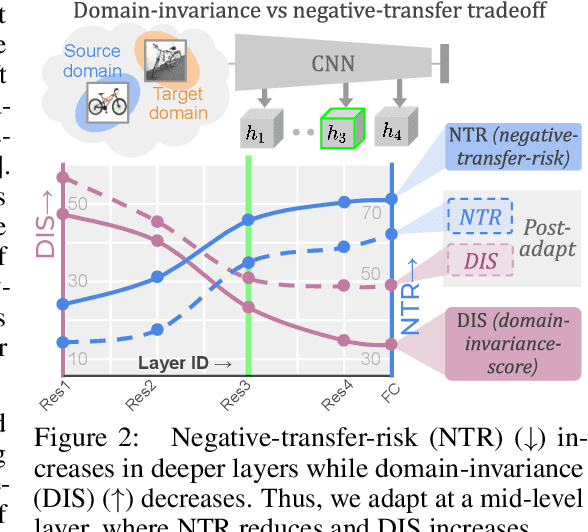
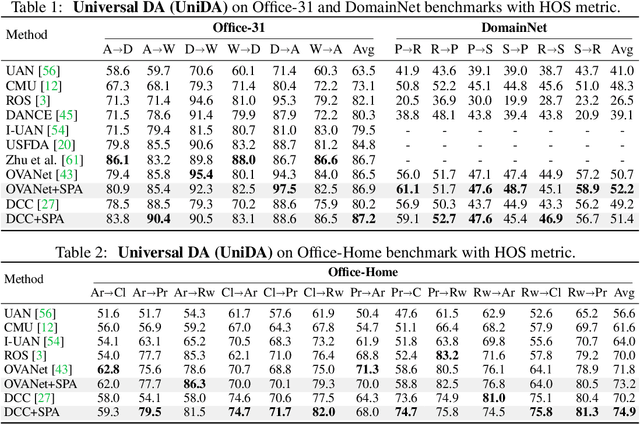
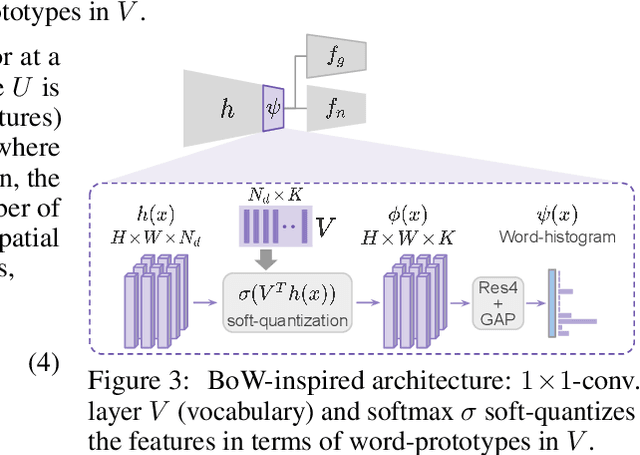
Universal Domain Adaptation (UniDA) deals with the problem of knowledge transfer between two datasets with domain-shift as well as category-shift. The goal is to categorize unlabeled target samples, either into one of the "known" categories or into a single "unknown" category. A major problem in UniDA is negative transfer, i.e. misalignment of "known" and "unknown" classes. To this end, we first uncover an intriguing tradeoff between negative-transfer-risk and domain-invariance exhibited at different layers of a deep network. It turns out we can strike a balance between these two metrics at a mid-level layer. Towards designing an effective framework based on this insight, we draw motivation from Bag-of-visual-Words (BoW). Word-prototypes in a BoW-like representation of a mid-level layer would represent lower-level visual primitives that are likely to be unaffected by the category-shift in the high-level features. We develop modifications that encourage learning of word-prototypes followed by word-histogram based classification. Following this, subsidiary prototype-space alignment (SPA) can be seen as a closed-set alignment problem, thereby avoiding negative transfer. We realize this with a novel word-histogram-related pretext task to enable closed-set SPA, operating in conjunction with goal task UniDA. We demonstrate the efficacy of our approach on top of existing UniDA techniques, yielding state-of-the-art performance across three standard UniDA and Open-Set DA object recognition benchmarks.
Concurrent Subsidiary Supervision for Unsupervised Source-Free Domain Adaptation
Jul 27, 2022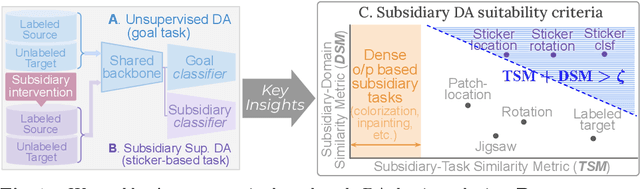
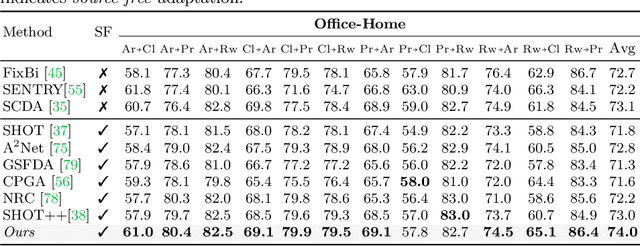
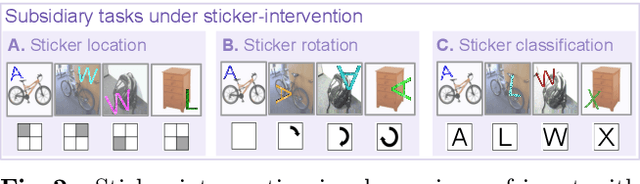
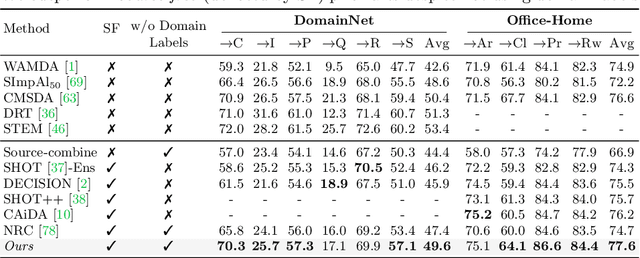
The prime challenge in unsupervised domain adaptation (DA) is to mitigate the domain shift between the source and target domains. Prior DA works show that pretext tasks could be used to mitigate this domain shift by learning domain invariant representations. However, in practice, we find that most existing pretext tasks are ineffective against other established techniques. Thus, we theoretically analyze how and when a subsidiary pretext task could be leveraged to assist the goal task of a given DA problem and develop objective subsidiary task suitability criteria. Based on this criteria, we devise a novel process of sticker intervention and cast sticker classification as a supervised subsidiary DA problem concurrent to the goal task unsupervised DA. Our approach not only improves goal task adaptation performance, but also facilitates privacy-oriented source-free DA i.e. without concurrent source-target access. Experiments on the standard Office-31, Office-Home, DomainNet, and VisDA benchmarks demonstrate our superiority for both single-source and multi-source source-free DA. Our approach also complements existing non-source-free works, achieving leading performance.