 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Set Object Detection By Aligning Known Class Representations
Dec 30, 2024



Open-Set Object Detection (OSOD) has emerged as a contemporary research direction to address the detection of unknown objects. Recently, few works have achieved remarkable performance in the OSOD task by employing contrastive clustering to separate unknown classes. In contrast, we propose a new semantic clustering-based approach to facilitate a meaningful alignment of clusters in semantic space and introduce a class decorrelation module to enhance inter-cluster separation. Our approach further incorporates an object focus module to predict objectness scores, which enhances the detection of unknown objects. Further, we employ i) an evaluation technique that penalizes low-confidence outputs to mitigate the risk of misclassification of the unknown objects and ii) a new metric called HMP that combines known and unknown precision using harmonic mean. Our extensive experiments demonstrate that the proposed model achieves significant improvement on the MS-COCO & PASCAL VOC dataset for the OSOD task.
Fiducial Focus Augmentation for Facial Landmark Detection
Feb 23, 2024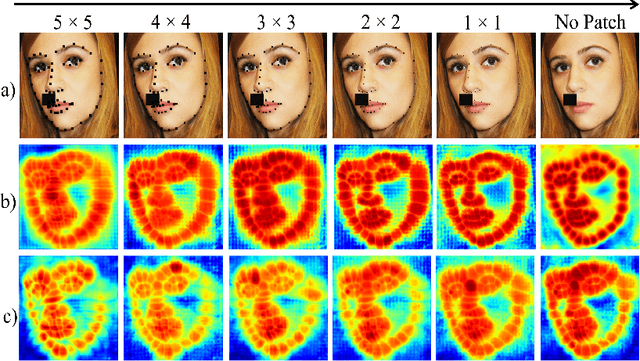
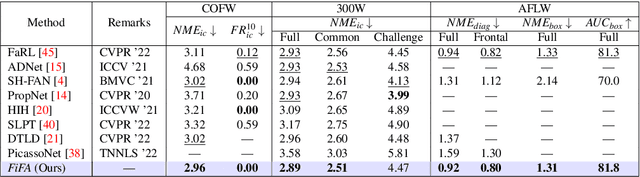
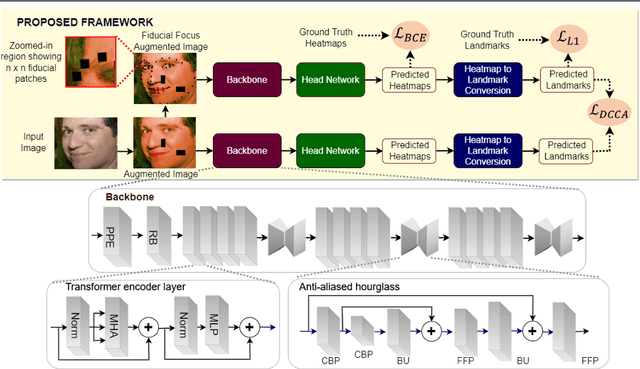

Deep learning methods have led to significant improvements in the performance on the facial landmark detection (FLD) task. However, detecting landmarks in challenging settings, such as head pose changes, exaggerated expressions, or uneven illumination, continue to remain a challenge due to high variability and insufficient samples. This inadequacy can be attributed to the model's inability to effectively acquire appropriate facial structure information from the input images. To address this, we propose a novel image augmentation technique specifically designed for the FLD task to enhance the model's understanding of facial structures. To effectively utilize the newly proposed augmentation technique, we employ a Siamese architecture-based training mechanism with a Deep Canonical Correlation Analysis (DCCA)-based loss to achieve collective learning of high-level feature representations from two different views of the input images. Furthermore, we employ a Transformer + CNN-based network with a custom hourglass module as the robust backbone for the Siamese framework. Extensive experiments show that our approach outperforms multiple state-of-the-art approaches across various benchmark datasets.
Estimation of individual causal effects in network setup for multiple treatments
Dec 18, 2023We study the problem of estimation of Individual Treatment Effects (ITE) in the context of multiple treatments and networked observational data. Leveraging the network information, we aim to utilize hidden confounders that may not be directly accessible in the observed data, thereby enhancing the practical applicability of the strong ignorability assumption. To achieve this, we first employ Graph Convolutional Networks (GCN) to learn a shared representation of the confounders. Then, our approach utilizes separate neural networks to infer potential outcomes for each treatment. We design a loss function as a weighted combination of two components: representation loss and Mean Squared Error (MSE) loss on the factual outcomes. To measure the representation loss, we extend existing metrics such as Wasserstein and Maximum Mean Discrepancy (MMD) from the binary treatment setting to the multiple treatments scenario. To validate the effectiveness of our proposed methodology, we conduct a series of experiments on the benchmark datasets such as BlogCatalog and Flickr. The experimental results consistently demonstrate the superior performance of our models when compared to baseline methods.
Revisiting Class Imbalance for End-to-end Semi-Supervised Object Detection
Jun 04, 2023



Semi-supervised object detection (SSOD) has made significant progress with the development of pseudo-label-based end-to-end methods. However, many of these methods face challenges due to class imbalance, which hinders the effectiveness of the pseudo-label generator. Furthermore, in the literature, it has been observed that low-quality pseudo-labels severely limit the performance of SSOD. In this paper, we examine the root causes of low-quality pseudo-labels and present novel learning mechanisms to improve the label generation quality. To cope with high false-negative and low precision rates, we introduce an adaptive thresholding mechanism that helps the proposed network to filter out optimal bounding boxes. We further introduce a Jitter-Bagging module to provide accurate information on localization to help refine the bounding boxes. Additionally, two new losses are introduced using the background and foreground scores predicted by the teacher and student networks to improvise the pseudo-label recall rate. Furthermore, our method applies strict supervision to the teacher network by feeding strong & weak augmented data to generate robust pseudo-labels so that it can detect small and complex objects. Finally, the extensive experiments show that the proposed network outperforms state-of-the-art methods on MS-COCO and Pascal VOC datasets and allows the baseline network to achieve 100% supervised performance with much less (i.e., 20%) labeled data.
Nonparallel Emotional Voice Conversion For Unseen Speaker-Emotion Pairs Using Dual Domain Adversarial Network & Virtual Domain Pairing
Feb 21, 2023

Primary goal of an emotional voice conversion (EVC) system is to convert the emotion of a given speech signal from one style to another style without modifying the linguistic content of the signal. Most of the state-of-the-art approaches convert emotions for seen speaker-emotion combinations only. In this paper, we tackle the problem of converting the emotion of speakers whose only neutral data are present during the time of training and testing (i.e., unseen speaker-emotion combinations). To this end, we extend a recently proposed StartGANv2-VC architecture by utilizing dual encoders for learning the speaker and emotion style embeddings separately along with dual domain source classifiers. For achieving the conversion to unseen speaker-emotion combinations, we propose a Virtual Domain Pairing (VDP) training strategy, which virtually incorporates the speaker-emotion pairs that are not present in the real data without compromising the min-max game of a discriminator and generator in adversarial training. We evaluate the proposed method using a Hindi emotional database.
M2FNet: Multi-modal Fusion Network for Emotion Recognition in Conversation
Jun 05, 2022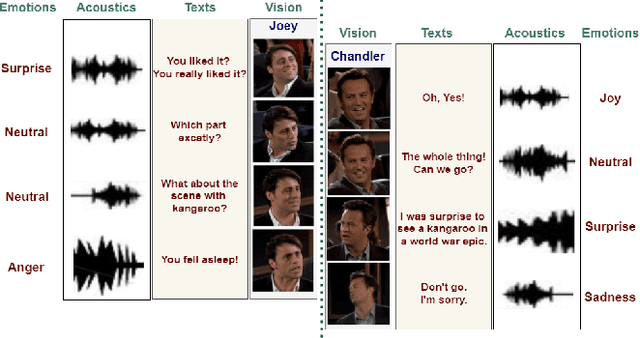
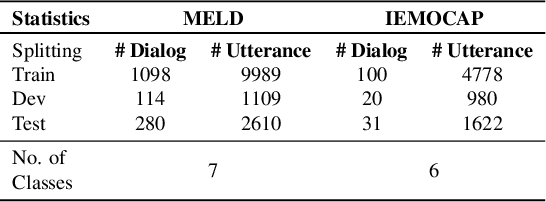

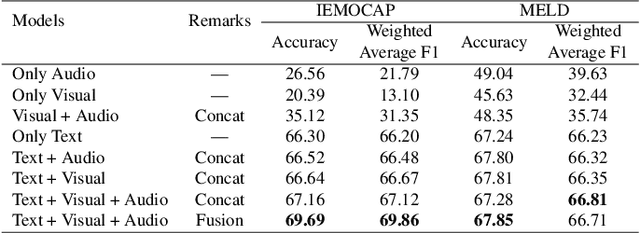
Emotion Recognition in Conversations (ERC) is crucial in developing sympathetic human-machine interaction. In conversational videos, emotion can be present in multiple modalities, i.e., audio, video, and transcript. However, due to the inherent characteristics of these modalities, multi-modal ERC has always been considered a challenging undertaking. Existing ERC research focuses mainly on using text information in a discussion, ignoring the other two modalities. We anticipate that emotion recognition accuracy can be improved by employing a multi-modal approach. Thus, in this study, we propose a Multi-modal Fusion Network (M2FNet) that extracts emotion-relevant features from visual, audio, and text modality. It employs a multi-head attention-based fusion mechanism to combine emotion-rich latent representations of the input data. We introduce a new feature extractor to extract latent features from the audio and visual modality. The proposed feature extractor is trained with a novel adaptive margin-based triplet loss function to learn emotion-relevant features from the audio and visual data. In the domain of ERC, the existing methods perform well on one benchmark dataset but not on others. Our results show that the proposed M2FNet architecture outperforms all other methods in terms of weighted average F1 score on well-known MELD and IEMOCAP datasets and sets a new state-of-the-art performance in ERC.
A Unified Model for Fingerprint Authentication and Presentation Attack Detection
Apr 07, 2021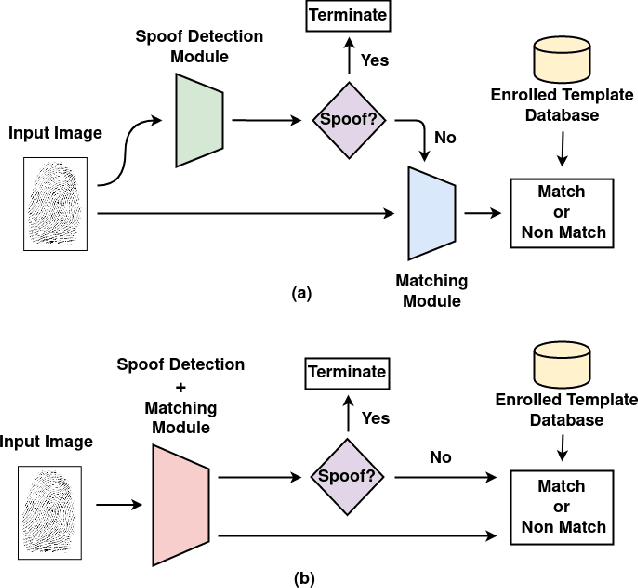

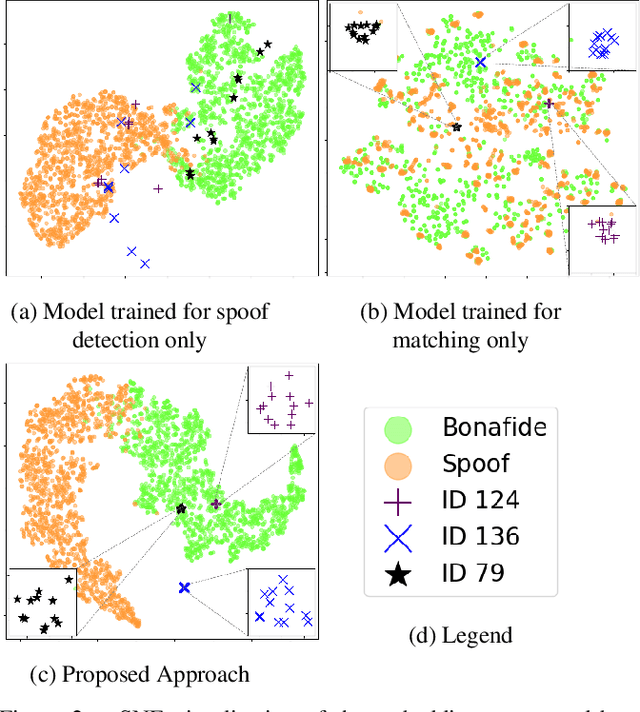
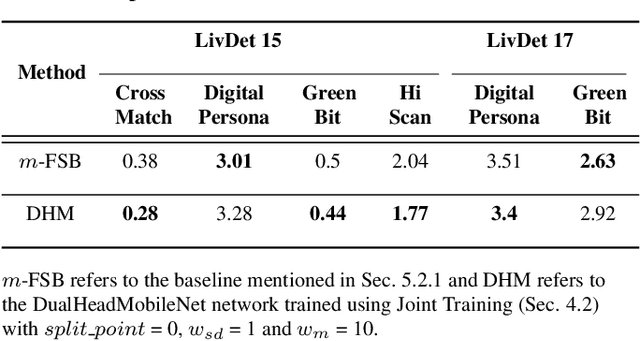
Typical fingerprint recognition systems are comprised of a spoof detection module and a subsequent recognition module, running one after the other. In this paper, we reformulate the workings of a typical fingerprint recognition system. In particular, we posit that both spoof detection and fingerprint recognition are correlated tasks. Therefore, rather than performing the two tasks separately, we propose a joint model for spoof detection and matching to simultaneously perform both tasks without compromising the accuracy of either task. We demonstrate the capability of our joint model to obtain an authentication accuracy (1:1 matching) of TAR = 100% @ FAR = 0.1% on the FVC 2006 DB2A dataset while achieving a spoof detection ACE of 1.44% on the LiveDet 2015 dataset, both maintaining the performance of stand-alone methods. In practice, this reduces the time and memory requirements of the fingerprint recognition system by 50% and 40%, respectively; a significant advantage for recognition systems running on resource-constrained devices and communication channels.