 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoReg: Directional Latent Vector Modeling for Emotional Intensity Regularization in Diffusion-based Voice Conversion
Dec 29, 2024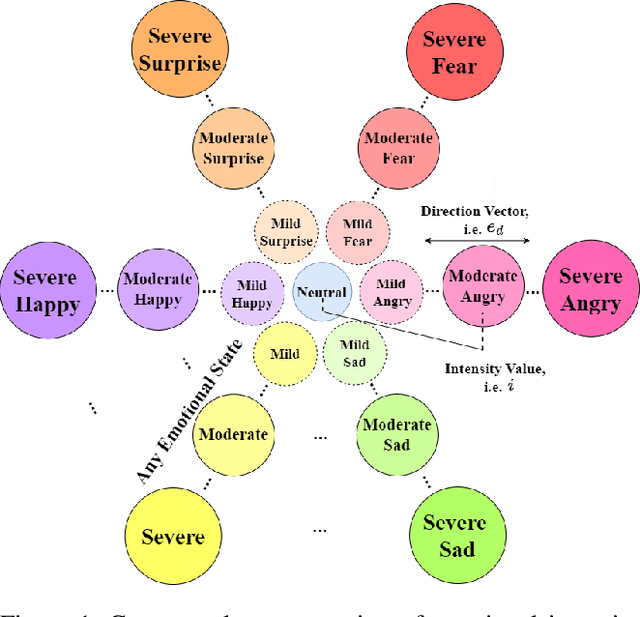
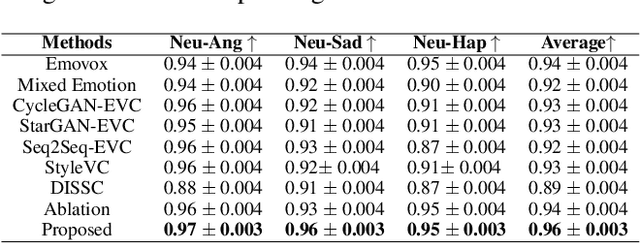
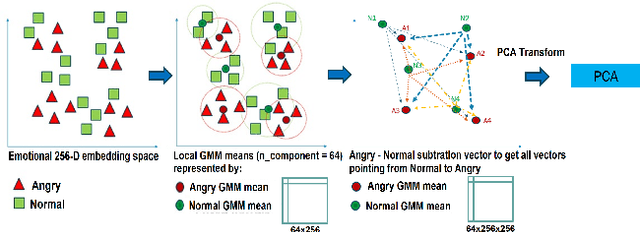
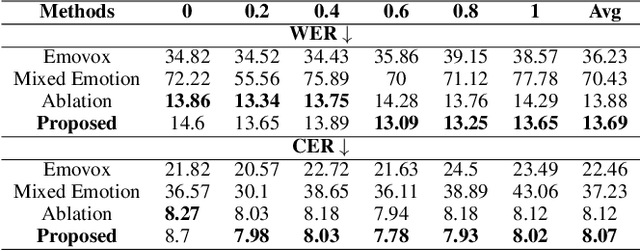
The Emotional Voice Conversion (EVC) aims to convert the discrete emotional state from the source emotion to the target for a given speech utterance while preserving linguistic content. In this paper, we propose regularizing emotion intensity in the diffusion-based EVC framework to generate precise speech of the target emotion. Traditional approaches control the intensity of an emotional state in the utterance via emotion class probabilities or intensity labels that often lead to inept style manipulations and degradations in quality. On the contrary, we aim to regulate emotion intensity using self-supervised learning-based feature representations and unsupervised directional latent vector modeling (DVM) in the emotional embedding space within a diffusion-based framework. These emotion embeddings can be modified based on the given target emotion intensity and the corresponding direction vector. Furthermore, the updated embeddings can be fused in the reverse diffusion process to generate the speech with the desired emotion and intensity. In summary, this paper aims to achieve high-quality emotional intensity regularization in the diffusion-based EVC framework, which is the first of its kind work. The effectiveness of the proposed method has been shown across state-of-the-art (SOTA) baselines in terms of subjective and objective evaluations for the English and Hindi languages \footnote{Demo samples are available at the following URL: \url{https://nirmesh-sony.github.io/EmoReg/}}.
DubWise: Video-Guided Speech Duration Control in Multimodal LLM-based Text-to-Speech for Dubbing
Jun 13, 2024



Audio-visual alignment after dubbing is a challenging research problem. To this end, we propose a novel method, DubWise Multi-modal Large Language Model (LLM)-based Text-to-Speech (TTS), which can control the speech duration of synthesized speech in such a way that it aligns well with the speakers lip movements given in the reference video even when the spoken text is different or in a different language. To accomplish this, we propose to utilize cross-modal attention techniques in a pre-trained GPT-based TTS. We combine linguistic tokens from text, speaker identity tokens via a voice cloning network, and video tokens via a proposed duration controller network. We demonstrate the effectiveness of our system on the Lip2Wav-Chemistry and LRS2 datasets. Also, the proposed method achieves improved lip sync and naturalness compared to the SOTAs for the same language but different text (i.e., non-parallel) and the different language, different text (i.e., cross-lingual) scenarios.
VECL-TTS: Voice identity and Emotional style controllable Cross-Lingual Text-to-Speech
Jun 12, 2024


Despite the significant advancements in Text-to-Speech (TTS) systems, their full utilization in automatic dubbing remains limited. This task necessitates the extraction of voice identity and emotional style from a reference speech in a source language and subsequently transferring them to a target language using cross-lingual TTS techniques. While previous approaches have mainly concentrated on controlling voice identity within the cross-lingual TTS framework, there has been limited work on incorporating emotion and voice identity together. To this end, we introduce an end-to-end Voice Identity and Emotional Style Controllable Cross-Lingual (VECL) TTS system using multilingual speakers and an emotion embedding network. Moreover, we introduce content and style consistency losses to enhance the quality of synthesized speech further. The proposed system achieved an average relative improvement of 8.83\% compared to the state-of-the-art (SOTA) methods on a database comprising English and three Indian languages (Hindi, Telugu, and Marathi).
Nonparallel Emotional Voice Conversion For Unseen Speaker-Emotion Pairs Using Dual Domain Adversarial Network & Virtual Domain Pairing
Feb 21, 2023

Primary goal of an emotional voice conversion (EVC) system is to convert the emotion of a given speech signal from one style to another style without modifying the linguistic content of the signal. Most of the state-of-the-art approaches convert emotions for seen speaker-emotion combinations only. In this paper, we tackle the problem of converting the emotion of speakers whose only neutral data are present during the time of training and testing (i.e., unseen speaker-emotion combinations). To this end, we extend a recently proposed StartGANv2-VC architecture by utilizing dual encoders for learning the speaker and emotion style embeddings separately along with dual domain source classifiers. For achieving the conversion to unseen speaker-emotion combinations, we propose a Virtual Domain Pairing (VDP) training strategy, which virtually incorporates the speaker-emotion pairs that are not present in the real data without compromising the min-max game of a discriminator and generator in adversarial training. We evaluate the proposed method using a Hindi emotional database.
M2FNet: Multi-modal Fusion Network for Emotion Recognition in Conversation
Jun 05, 2022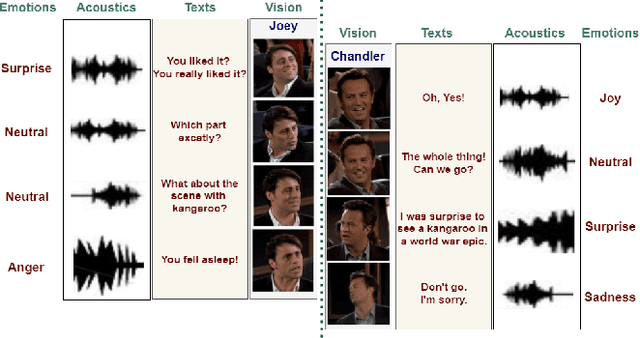
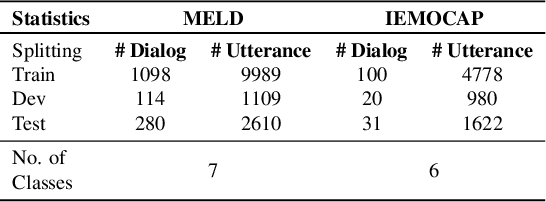

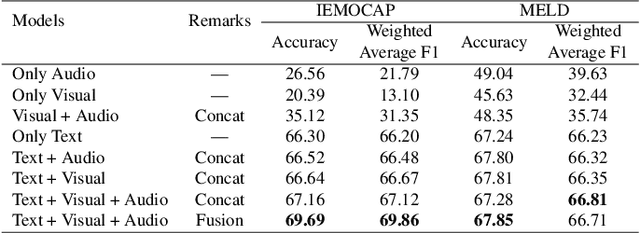
Emotion Recognition in Conversations (ERC) is crucial in developing sympathetic human-machine interaction. In conversational videos, emotion can be present in multiple modalities, i.e., audio, video, and transcript. However, due to the inherent characteristics of these modalities, multi-modal ERC has always been considered a challenging undertaking. Existing ERC research focuses mainly on using text information in a discussion, ignoring the other two modalities. We anticipate that emotion recognition accuracy can be improved by employing a multi-modal approach. Thus, in this study, we propose a Multi-modal Fusion Network (M2FNet) that extracts emotion-relevant features from visual, audio, and text modality. It employs a multi-head attention-based fusion mechanism to combine emotion-rich latent representations of the input data. We introduce a new feature extractor to extract latent features from the audio and visual modality. The proposed feature extractor is trained with a novel adaptive margin-based triplet loss function to learn emotion-relevant features from the audio and visual data. In the domain of ERC, the existing methods perform well on one benchmark dataset but not on others. Our results show that the proposed M2FNet architecture outperforms all other methods in terms of weighted average F1 score on well-known MELD and IEMOCAP datasets and sets a new state-of-the-art performance in ERC.