 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Time Traveller : Travel Through Ages Without Losing Identity
Feb 26, 2026Face aging, an ill-posed problem shaped by environmental and genetic factors, is vital in entertainment, forensics, and digital archiving, where realistic age transformations must preserve both identity and visual realism. However, existing works relying on numerical age representations overlook the interplay of biological and contextual cues. Despite progress in recent face aging models, they struggle with identity preservation in wide age transformations, also static attention and optimization-heavy inversion in diffusion limit adaptability, fine-grained control and background consistency. To address these challenges, we propose Face Time Traveller (FaceTT), a diffusion-based framework that achieves high-fidelity, identity-consistent age transformation. Here, we introduce a Face-Attribute-Aware Prompt Refinement strategy that encodes intrinsic (biological) and extrinsic (environmental) aging cues for context-aware conditioning. A tuning-free Angular Inversion method is proposed that efficiently maps real faces into the diffusion latent space for fast and accurate reconstruction. Moreover, an Adaptive Attention Control mechanism is introduced that dynamically balances cross-attention for semantic aging cues and self-attention for structural and identity preservation. Extensive experiments on benchmark datasets and in-the-wild testset demonstrate that FaceTT achieves superior identity retention, background preservation and aging realism over state-of-the-art (SOTA) methods.
Cross-Modal Fusion and Attention Mechanism for Weakly Supervised Video Anomaly Detection
Dec 29, 2024



Recently, weakly supervised video anomaly detection (WS-VAD) has emerged as a contemporary research direction to identify anomaly events like violence and nudity in videos using only video-level labels. However, this task has substantial challenges, including addressing imbalanced modality information and consistently distinguishing between normal and abnormal features. In this paper, we address these challenges and propose a multi-modal WS-VAD framework to accurately detect anomalies such as violence and nudity. Within the proposed framework, we introduce a new fusion mechanism known as the Cross-modal Fusion Adapter (CFA), which dynamically selects and enhances highly relevant audio-visual features in relation to the visual modality. Additionally, we introduce a Hyperbolic Lorentzian Graph Attention (HLGAtt) to effectively capture the hierarchical relationships between normal and abnormal representations, thereby enhancing feature separation accuracy. Through extensive experiments, we demonstrate that the proposed model achieves state-of-the-art results on benchmark datasets of violence and nudity detection.
Fiducial Focus Augmentation for Facial Landmark Detection
Feb 23, 2024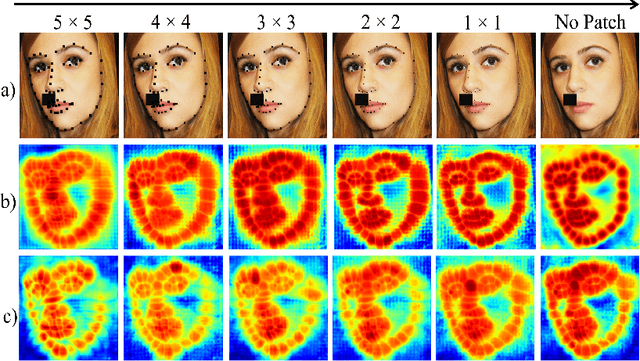
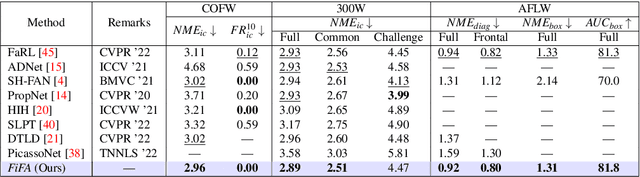
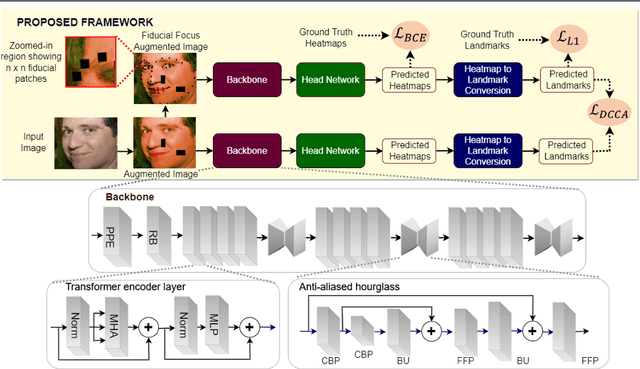

Deep learning methods have led to significant improvements in the performance on the facial landmark detection (FLD) task. However, detecting landmarks in challenging settings, such as head pose changes, exaggerated expressions, or uneven illumination, continue to remain a challenge due to high variability and insufficient samples. This inadequacy can be attributed to the model's inability to effectively acquire appropriate facial structure information from the input images. To address this, we propose a novel image augmentation technique specifically designed for the FLD task to enhance the model's understanding of facial structures. To effectively utilize the newly proposed augmentation technique, we employ a Siamese architecture-based training mechanism with a Deep Canonical Correlation Analysis (DCCA)-based loss to achieve collective learning of high-level feature representations from two different views of the input images. Furthermore, we employ a Transformer + CNN-based network with a custom hourglass module as the robust backbone for the Siamese framework. Extensive experiments show that our approach outperforms multiple state-of-the-art approaches across various benchmark datasets.
Revisiting Class Imbalance for End-to-end Semi-Supervised Object Detection
Jun 04, 2023



Semi-supervised object detection (SSOD) has made significant progress with the development of pseudo-label-based end-to-end methods. However, many of these methods face challenges due to class imbalance, which hinders the effectiveness of the pseudo-label generator. Furthermore, in the literature, it has been observed that low-quality pseudo-labels severely limit the performance of SSOD. In this paper, we examine the root causes of low-quality pseudo-labels and present novel learning mechanisms to improve the label generation quality. To cope with high false-negative and low precision rates, we introduce an adaptive thresholding mechanism that helps the proposed network to filter out optimal bounding boxes. We further introduce a Jitter-Bagging module to provide accurate information on localization to help refine the bounding boxes. Additionally, two new losses are introduced using the background and foreground scores predicted by the teacher and student networks to improvise the pseudo-label recall rate. Furthermore, our method applies strict supervision to the teacher network by feeding strong & weak augmented data to generate robust pseudo-labels so that it can detect small and complex objects. Finally, the extensive experiments show that the proposed network outperforms state-of-the-art methods on MS-COCO and Pascal VOC datasets and allows the baseline network to achieve 100% supervised performance with much less (i.e., 20%) labeled data.
M2FNet: Multi-modal Fusion Network for Emotion Recognition in Conversation
Jun 05, 2022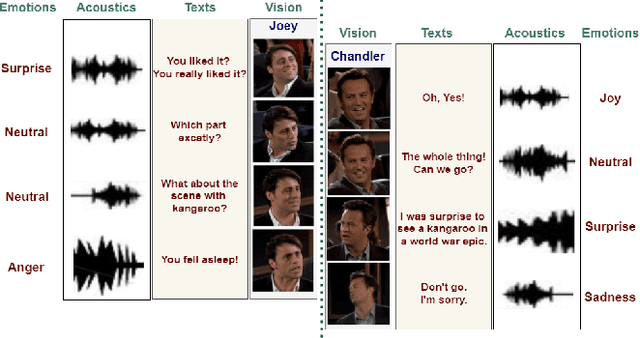
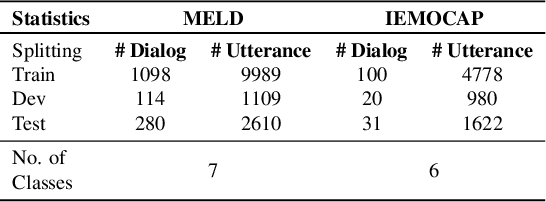

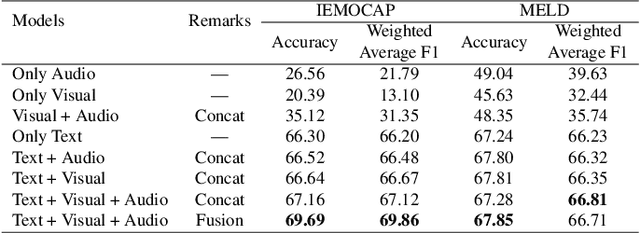
Emotion Recognition in Conversations (ERC) is crucial in developing sympathetic human-machine interaction. In conversational videos, emotion can be present in multiple modalities, i.e., audio, video, and transcript. However, due to the inherent characteristics of these modalities, multi-modal ERC has always been considered a challenging undertaking. Existing ERC research focuses mainly on using text information in a discussion, ignoring the other two modalities. We anticipate that emotion recognition accuracy can be improved by employing a multi-modal approach. Thus, in this study, we propose a Multi-modal Fusion Network (M2FNet) that extracts emotion-relevant features from visual, audio, and text modality. It employs a multi-head attention-based fusion mechanism to combine emotion-rich latent representations of the input data. We introduce a new feature extractor to extract latent features from the audio and visual modality. The proposed feature extractor is trained with a novel adaptive margin-based triplet loss function to learn emotion-relevant features from the audio and visual data. In the domain of ERC, the existing methods perform well on one benchmark dataset but not on others. Our results show that the proposed M2FNet architecture outperforms all other methods in terms of weighted average F1 score on well-known MELD and IEMOCAP datasets and sets a new state-of-the-art performance in ERC.