 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Reasons Help Improve Pedestrian Intent Estimation? A Cross-Modal Approach
Nov 20, 2024



With the increased importance of autonomous navigation systems has come an increasing need to protect the safety of Vulnerable Road Users (VRUs) such as pedestrians. Predicting pedestrian intent is one such challenging task, where prior work predicts the binary cross/no-cross intention with a fusion of visual and motion features. However, there has been no effort so far to hedge such predictions with human-understandable reasons. We address this issue by introducing a novel problem setting of exploring the intuitive reasoning behind a pedestrian's intent. In particular, we show that predicting the 'WHY' can be very useful in understanding the 'WHAT'. To this end, we propose a novel, reason-enriched PIE++ dataset consisting of multi-label textual explanations/reasons for pedestrian intent. We also introduce a novel multi-task learning framework called MINDREAD, which leverages a cross-modal representation learning framework for predicting pedestrian intent as well as the reason behind the intent. Our comprehensive experiments show significant improvement of 5.6% and 7% in accuracy and F1-score for the task of intent prediction on the PIE++ dataset using MINDREAD. We also achieved a 4.4% improvement in accuracy on a commonly used JAAD dataset. Extensive evaluation using quantitative/qualitative metrics and user studies shows the effectiveness of our approach.
Fiducial Focus Augmentation for Facial Landmark Detection
Feb 23, 2024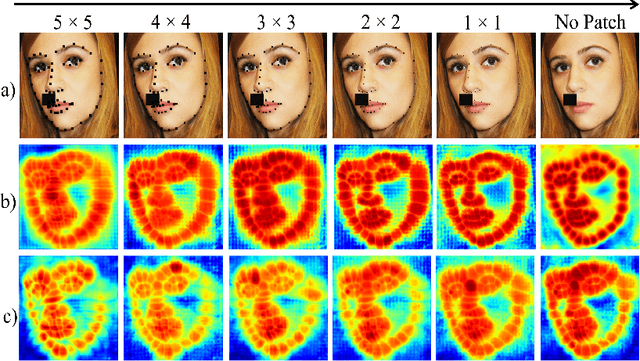
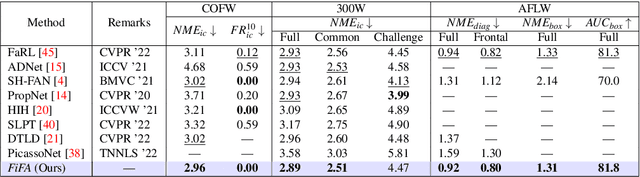
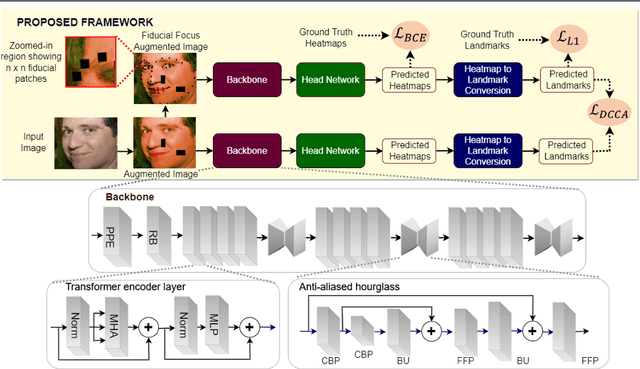

Deep learning methods have led to significant improvements in the performance on the facial landmark detection (FLD) task. However, detecting landmarks in challenging settings, such as head pose changes, exaggerated expressions, or uneven illumination, continue to remain a challenge due to high variability and insufficient samples. This inadequacy can be attributed to the model's inability to effectively acquire appropriate facial structure information from the input images. To address this, we propose a novel image augmentation technique specifically designed for the FLD task to enhance the model's understanding of facial structures. To effectively utilize the newly proposed augmentation technique, we employ a Siamese architecture-based training mechanism with a Deep Canonical Correlation Analysis (DCCA)-based loss to achieve collective learning of high-level feature representations from two different views of the input images. Furthermore, we employ a Transformer + CNN-based network with a custom hourglass module as the robust backbone for the Siamese framework. Extensive experiments show that our approach outperforms multiple state-of-the-art approaches across various benchmark datasets.
Class-Incremental Learning with Cross-Space Clustering and Controlled Transfer
Aug 16, 2022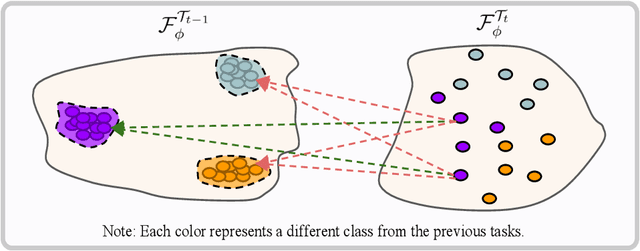
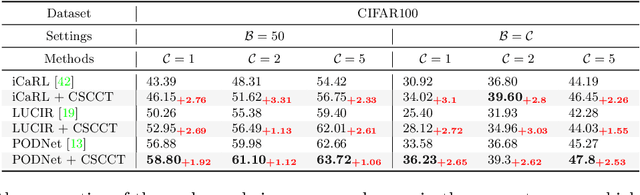
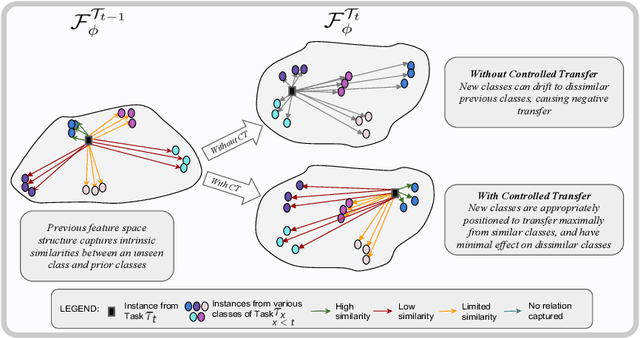
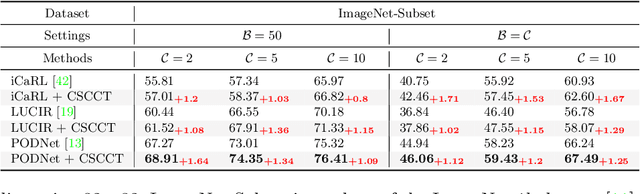
In class-incremental learning, the model is expected to learn new classes continually while maintaining knowledge on previous classes. The challenge here lies in preserving the model's ability to effectively represent prior classes in the feature space, while adapting it to represent incoming new classes. We propose two distillation-based objectives for class incremental learning that leverage the structure of the feature space to maintain accuracy on previous classes, as well as enable learning the new classes. In our first objective, termed cross-space clustering (CSC), we propose to use the feature space structure of the previous model to characterize directions of optimization that maximally preserve the class: directions that all instances of a specific class should collectively optimize towards, and those that they should collectively optimize away from. Apart from minimizing forgetting, this indirectly encourages the model to cluster all instances of a class in the current feature space, and gives rise to a sense of herd-immunity, allowing all samples of a class to jointly combat the model from forgetting the class. Our second objective termed controlled transfer (CT) tackles incremental learning from an understudied perspective of inter-class transfer. CT explicitly approximates and conditions the current model on the semantic similarities between incrementally arriving classes and prior classes. This allows the model to learn classes in such a way that it maximizes positive forward transfer from similar prior classes, thus increasing plasticity, and minimizes negative backward transfer on dissimilar prior classes, whereby strengthening stability. We perform extensive experiments on two benchmark datasets, adding our method (CSCCT) on top of three prominent class-incremental learning methods. We observe consistent performance improvement on a variety of experimental settings.
Learning Modular Structures That Generalize Out-of-Distribution
Aug 07, 2022
Out-of-distribution (O.O.D.) generalization remains to be a key challenge for real-world machine learning systems. We describe a method for O.O.D. generalization that, through training, encourages models to only preserve features in the network that are well reused across multiple training domains. Our method combines two complementary neuron-level regularizers with a probabilistic differentiable binary mask over the network, to extract a modular sub-network that achieves better O.O.D. performance than the original network. Preliminary evaluation on two benchmark datasets corroborates the promise of our method.
Retrospective Loss: Looking Back to Improve Training of Deep Neural Networks
Jun 24, 2020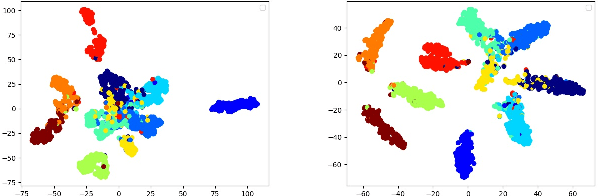
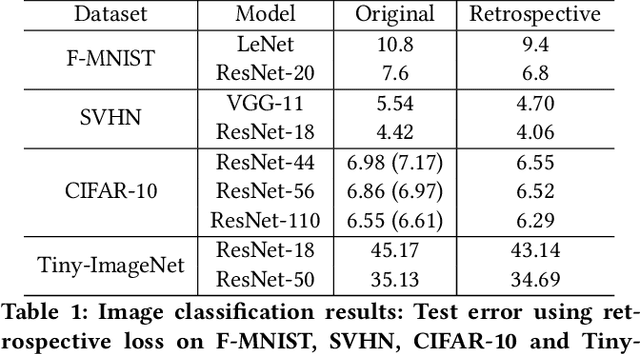
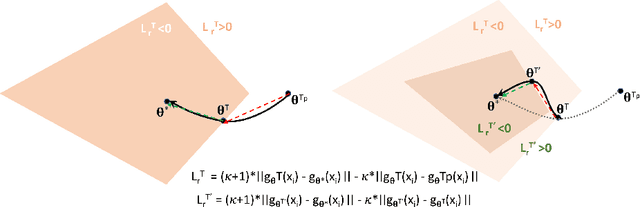
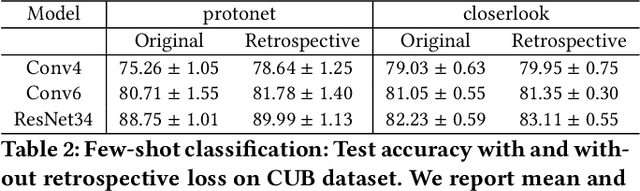
Deep neural networks (DNNs) are powerful learning machines that have enabled breakthroughs in several domains. In this work, we introduce a new retrospective loss to improve the training of deep neural network models by utilizing the prior experience available in past model states during training. Minimizing the retrospective loss, along with the task-specific loss, pushes the parameter state at the current training step towards the optimal parameter state while pulling it away from the parameter state at a previous training step. Although a simple idea, we analyze the method as well as to conduct comprehensive sets of experiments across domains - images, speech, text, and graphs - to show that the proposed loss results in improved performance across input domains, tasks, and architectures.
Incremental Object Detection via Meta-Learning
Mar 17, 2020

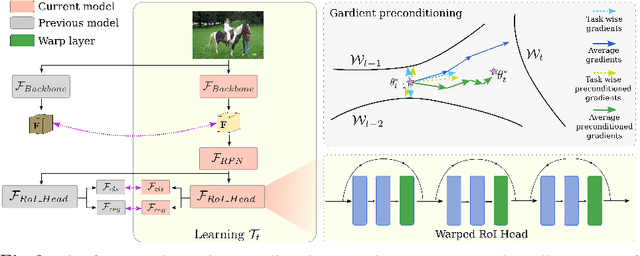

In a real-world setting, object instances from new classes may be continuously encountered by object detectors. When existing object detectors are applied to such scenarios, their performance on old classes deteriorates significantly. A few efforts have been reported to address this limitation, all of which apply variants of knowledge distillation to avoid catastrophic forgetting. We note that although distillation helps to retain previous learning, it obstructs fast adaptability to new tasks, which is a critical requirement for incremental learning. In this pursuit, we propose a meta-learning approach that learns to reshape model gradients, such that information across incremental tasks is optimally shared. This ensures a seamless information transfer via a meta-learned gradient preconditioning that minimizes forgetting and maximizes knowledge transfer. In comparison to existing meta-learning methods, our approach is task-agnostic, allows incremental addition of new-classes and scales to large-sized models for object detection. We evaluate our approach on a variety of incremental settings defined on PASCAL-VOC and MS COCO datasets, demonstrating significant improvements over state-of-the-art.
DAiSEE: Towards User Engagement Recognition in the Wild
Apr 13, 2018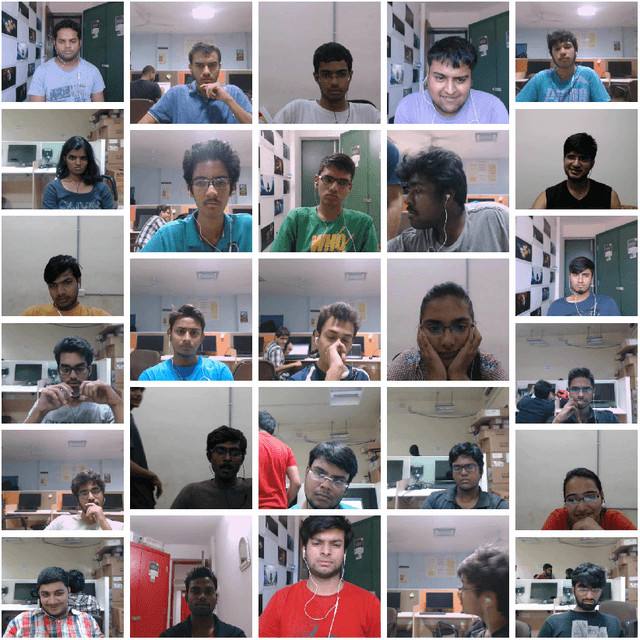
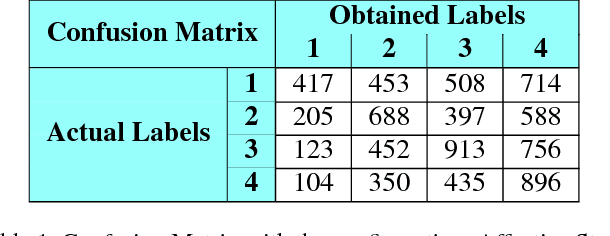

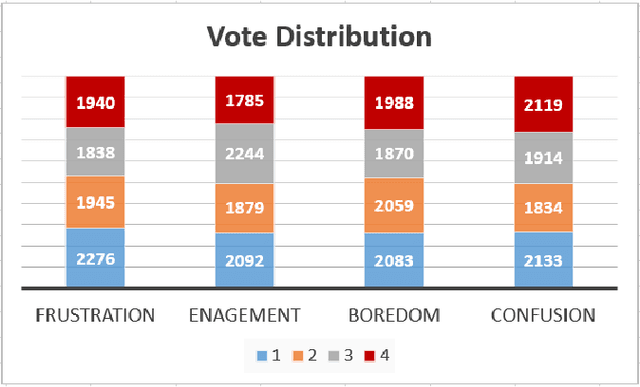
We introduce DAiSEE, the first multi-label video classification dataset comprising of 9068 video snippets captured from 112 users for recognizing the user affective states of boredom, confusion, engagement, and frustration in the wild. The dataset has four levels of labels namely - very low, low, high, and very high for each of the affective states, which are crowd annotated and correlated with a gold standard annotation created using a team of expert psychologists. We have also established benchmark results on this dataset using state-of-the-art video classification methods that are available today. We believe that DAiSEE will provide the research community with challenges in feature extraction, context-based inference, and development of suitable machine learning methods for related tasks, thus providing a springboard for further research. The dataset is available for download at https://iith.ac.in/~daisee-dataset