 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Object Detection via Meta-Learning
Paper and Code


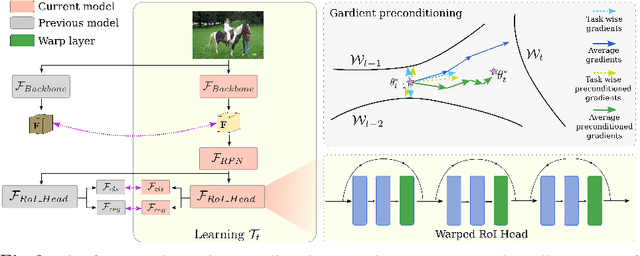

In a real-world setting, object instances from new classes may be continuously encountered by object detectors. When existing object detectors are applied to such scenarios, their performance on old classes deteriorates significantly. A few efforts have been reported to address this limitation, all of which apply variants of knowledge distillation to avoid catastrophic forgetting. We note that although distillation helps to retain previous learning, it obstructs fast adaptability to new tasks, which is a critical requirement for incremental learning. In this pursuit, we propose a meta-learning approach that learns to reshape model gradients, such that information across incremental tasks is optimally shared. This ensures a seamless information transfer via a meta-learned gradient preconditioning that minimizes forgetting and maximizes knowledge transfer. In comparison to existing meta-learning methods, our approach is task-agnostic, allows incremental addition of new-classes and scales to large-sized models for object detection. We evaluate our approach on a variety of incremental settings defined on PASCAL-VOC and MS COCO datasets, demonstrating significant improvements over state-of-the-art.