 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Hierarchical Cross-Modal Fusion Predict Human Perception of AI Dubbed Content?
Mar 30, 2026Evaluating AI generated dubbed content is inherently multi-dimensional, shaped by synchronization, intelligibility, speaker consistency, emotional alignment, and semantic context. Human Mean Opinion Scores (MOS) remain the gold standard but are costly and impractical at scale. We present a hierarchical multimodal architecture for perceptually meaningful dubbing evaluation, integrating complementary cues from audio, video, and text. The model captures fine-grained features such as speaker identity, prosody, and content from audio, facial expressions and scene-level cues from video and semantic context from text, which are progressively fused through intra and inter-modal layers. Lightweight LoRA adapters enable parameter-efficient fine-tuning across modalities. To overcome limited subjective labels, we derive proxy MOS by aggregating objective metrics with weights optimized via active learning. The proposed architecture was trained on 12k Hindi-English bidirectional dubbed clips, followed by fine-tuning with human MOS. Our approach achieves strong perceptual alignment (PCC > 0.75), providing a scalable solution for automatic evaluation of AI-dubbed content.
EmoReg: Directional Latent Vector Modeling for Emotional Intensity Regularization in Diffusion-based Voice Conversion
Dec 29, 2024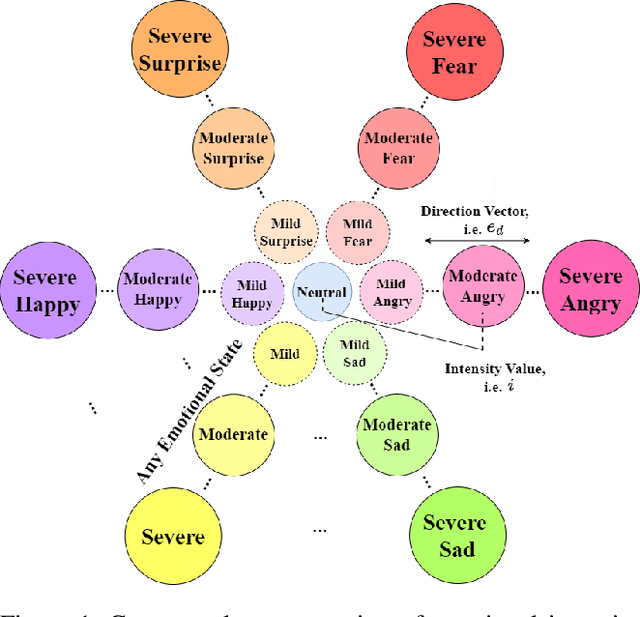
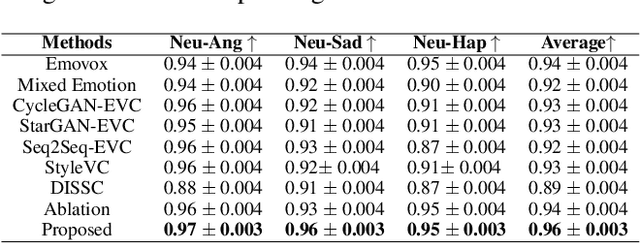
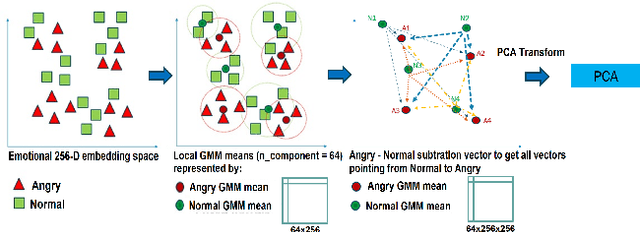
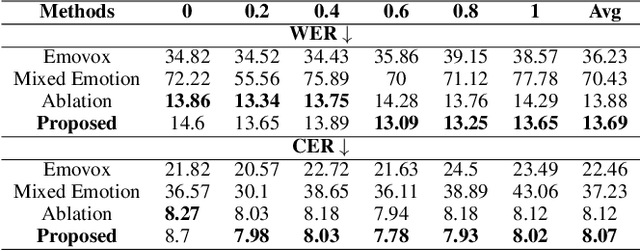
The Emotional Voice Conversion (EVC) aims to convert the discrete emotional state from the source emotion to the target for a given speech utterance while preserving linguistic content. In this paper, we propose regularizing emotion intensity in the diffusion-based EVC framework to generate precise speech of the target emotion. Traditional approaches control the intensity of an emotional state in the utterance via emotion class probabilities or intensity labels that often lead to inept style manipulations and degradations in quality. On the contrary, we aim to regulate emotion intensity using self-supervised learning-based feature representations and unsupervised directional latent vector modeling (DVM) in the emotional embedding space within a diffusion-based framework. These emotion embeddings can be modified based on the given target emotion intensity and the corresponding direction vector. Furthermore, the updated embeddings can be fused in the reverse diffusion process to generate the speech with the desired emotion and intensity. In summary, this paper aims to achieve high-quality emotional intensity regularization in the diffusion-based EVC framework, which is the first of its kind work. The effectiveness of the proposed method has been shown across state-of-the-art (SOTA) baselines in terms of subjective and objective evaluations for the English and Hindi languages \footnote{Demo samples are available at the following URL: \url{https://nirmesh-sony.github.io/EmoReg/}}.
DubWise: Video-Guided Speech Duration Control in Multimodal LLM-based Text-to-Speech for Dubbing
Jun 13, 2024



Audio-visual alignment after dubbing is a challenging research problem. To this end, we propose a novel method, DubWise Multi-modal Large Language Model (LLM)-based Text-to-Speech (TTS), which can control the speech duration of synthesized speech in such a way that it aligns well with the speakers lip movements given in the reference video even when the spoken text is different or in a different language. To accomplish this, we propose to utilize cross-modal attention techniques in a pre-trained GPT-based TTS. We combine linguistic tokens from text, speaker identity tokens via a voice cloning network, and video tokens via a proposed duration controller network. We demonstrate the effectiveness of our system on the Lip2Wav-Chemistry and LRS2 datasets. Also, the proposed method achieves improved lip sync and naturalness compared to the SOTAs for the same language but different text (i.e., non-parallel) and the different language, different text (i.e., cross-lingual) scenarios.
VECL-TTS: Voice identity and Emotional style controllable Cross-Lingual Text-to-Speech
Jun 12, 2024


Despite the significant advancements in Text-to-Speech (TTS) systems, their full utilization in automatic dubbing remains limited. This task necessitates the extraction of voice identity and emotional style from a reference speech in a source language and subsequently transferring them to a target language using cross-lingual TTS techniques. While previous approaches have mainly concentrated on controlling voice identity within the cross-lingual TTS framework, there has been limited work on incorporating emotion and voice identity together. To this end, we introduce an end-to-end Voice Identity and Emotional Style Controllable Cross-Lingual (VECL) TTS system using multilingual speakers and an emotion embedding network. Moreover, we introduce content and style consistency losses to enhance the quality of synthesized speech further. The proposed system achieved an average relative improvement of 8.83\% compared to the state-of-the-art (SOTA) methods on a database comprising English and three Indian languages (Hindi, Telugu, and Marathi).