 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlotTwist: A Creative Plot Generation Framework with Small Language Models
Mar 17, 2026Creative plot generation presents a fundamental challenge for language models: transforming a concise premise into a coherent narrative that sustains global structure, character development, and emotional resonance. Although recent Large Language Models (LLMs) demonstrate strong fluency across general-purpose tasks, they typically require preference alignment to perform well on specialized domains such as creative plot generation. However, conducting such alignment at the scale of frontier LLMs is computationally prohibitive, significantly limiting accessibility and practical deployment. To address this, we present PlotTwist, a structured framework that enables Small Language Models (SLMs) with $\leq$ 5B active parameters to generate high-quality, premise-conditioned plots competitive with frontier systems up to $200\times$ larger. Our approach decomposes generation into three specialized components: (1) an Aspect Rating Reward Model trained via a novel Positive-Negative prompting strategy to deliver structured narratives across five Narrative Quality Dimensions (NQDs); (2) a Mixture-of-Experts (MoE) plot generator aligned via Direct Preference Optimization on high-confidence preference pairs; and (3) an Agentic Evaluation module that emulates human critical judgment for unbiased post-hoc assessment. Extensive experiments demonstrate that PlotTwist consistently outperforms frontier models across multiple NQDs despite substantially tighter capacity constraints. Further validation confirms strong sensitivity to narrative quality, as the framework reliably distinguishes plots derived from critically acclaimed versus widely panned screenplays. Together, these results establish structured, preference-based alignment as a resource-efficient approach to high-quality creative plot generation.
KANITE: Kolmogorov-Arnold Networks for ITE estimation
Mar 18, 2025



We introduce KANITE, a framework leveraging Kolmogorov-Arnold Networks (KANs) for Individual Treatment Effect (ITE) estimation under multiple treatments setting in causal inference. By utilizing KAN's unique abilities to learn univariate activation functions as opposed to learning linear weights by Multi-Layer Perceptrons (MLPs), we improve the estimates of ITEs. The KANITE framework comprises two key architectures: 1.Integral Probability Metric (IPM) architecture: This employs an IPM loss in a specialized manner to effectively align towards ITE estimation across multiple treatments. 2. Entropy Balancing (EB) architecture: This uses weights for samples that are learned by optimizing entropy subject to balancing the covariates across treatment groups. Extensive evaluations on benchmark datasets demonstrate that KANITE outperforms state-of-the-art algorithms in both $\epsilon_{\text{PEHE}}$ and $\epsilon_{\text{ATE}}$ metrics. Our experiments highlight the advantages of KANITE in achieving improved causal estimates, emphasizing the potential of KANs to advance causal inference methodologies across diverse application areas.
I See, Therefore I Do: Estimating Causal Effects for Image Treatments
Nov 28, 2024



Causal effect estimation under observational studies is challenging due to the lack of ground truth data and treatment assignment bias. Though various methods exist in literature for addressing this problem, most of them ignore multi-dimensional treatment information by considering it as scalar, either continuous or discrete. Recently, certain works have demonstrated the utility of this rich yet complex treatment information into the estimation process, resulting in better causal effect estimation. However, these works have been demonstrated on either graphs or textual treatments. There is a notable gap in existing literature in addressing higher dimensional data such as images that has a wide variety of applications. In this work, we propose a model named NICE (Network for Image treatments Causal effect Estimation), for estimating individual causal effects when treatments are images. NICE demonstrates an effective way to use the rich multidimensional information present in image treatments that helps in obtaining improved causal effect estimates. To evaluate the performance of NICE, we propose a novel semi-synthetic data simulation framework that generates potential outcomes when images serve as treatments. Empirical results on these datasets, under various setups including the zero-shot case, demonstrate that NICE significantly outperforms existing models that incorporate treatment information for causal effect estimation.
Estimation of individual causal effects in network setup for multiple treatments
Dec 18, 2023We study the problem of estimation of Individual Treatment Effects (ITE) in the context of multiple treatments and networked observational data. Leveraging the network information, we aim to utilize hidden confounders that may not be directly accessible in the observed data, thereby enhancing the practical applicability of the strong ignorability assumption. To achieve this, we first employ Graph Convolutional Networks (GCN) to learn a shared representation of the confounders. Then, our approach utilizes separate neural networks to infer potential outcomes for each treatment. We design a loss function as a weighted combination of two components: representation loss and Mean Squared Error (MSE) loss on the factual outcomes. To measure the representation loss, we extend existing metrics such as Wasserstein and Maximum Mean Discrepancy (MMD) from the binary treatment setting to the multiple treatments scenario. To validate the effectiveness of our proposed methodology, we conduct a series of experiments on the benchmark datasets such as BlogCatalog and Flickr. The experimental results consistently demonstrate the superior performance of our models when compared to baseline methods.
MParrotTTS: Multilingual Multi-speaker Text to Speech Synthesis in Low Resource Setting
May 19, 2023



We present MParrotTTS, a unified multilingual, multi-speaker text-to-speech (TTS) synthesis model that can produce high-quality speech. Benefiting from a modularized training paradigm exploiting self-supervised speech representations, MParrotTTS adapts to a new language with minimal supervised data and generalizes to languages not seen while training the self-supervised backbone. Moreover, without training on any bilingual or parallel examples, MParrotTTS can transfer voices across languages while preserving the speaker-specific characteristics, e.g., synthesizing fluent Hindi speech using a French speaker's voice and accent. We present extensive results on six languages in terms of speech naturalness and speaker similarity in parallel and cross-lingual synthesis. The proposed model outperforms the state-of-the-art multilingual TTS models and baselines, using only a small fraction of supervised training data. Speech samples from our model can be found at https://paper2438.github.io/tts/
I Know Therefore I Score: Label-Free Crafting of Scoring Functions using Constraints Based on Domain Expertise
Mar 18, 2022
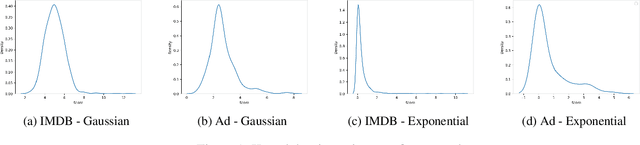
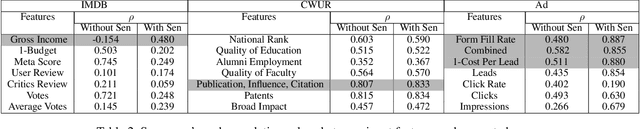

Several real-life applications require crafting concise, quantitative scoring functions (also called rating systems) from measured observations. For example, an effectiveness score needs to be created for advertising campaigns using a number of engagement metrics. Experts often need to create such scoring functions in the absence of labelled data, where the scores need to reflect business insights and rules as understood by the domain experts. Without a way to capture these inputs systematically, this becomes a time-consuming process involving trial and error. In this paper, we introduce a label-free practical approach to learn a scoring function from multi-dimensional numerical data. The approach incorporates insights and business rules from domain experts in the form of easily observable and specifiable constraints, which are used as weak supervision by a machine learning model. We convert such constraints into loss functions that are optimized simultaneously while learning the scoring function. We examine the efficacy of the approach using a synthetic dataset as well as four real-life datasets, and also compare how it performs vis-a-vis supervised learning models.