 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Know Therefore I Score: Label-Free Crafting of Scoring Functions using Constraints Based on Domain Expertise
Paper and Code

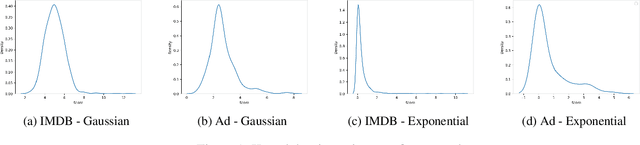
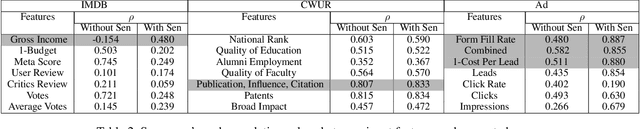

Several real-life applications require crafting concise, quantitative scoring functions (also called rating systems) from measured observations. For example, an effectiveness score needs to be created for advertising campaigns using a number of engagement metrics. Experts often need to create such scoring functions in the absence of labelled data, where the scores need to reflect business insights and rules as understood by the domain experts. Without a way to capture these inputs systematically, this becomes a time-consuming process involving trial and error. In this paper, we introduce a label-free practical approach to learn a scoring function from multi-dimensional numerical data. The approach incorporates insights and business rules from domain experts in the form of easily observable and specifiable constraints, which are used as weak supervision by a machine learning model. We convert such constraints into loss functions that are optimized simultaneously while learning the scoring function. We examine the efficacy of the approach using a synthetic dataset as well as four real-life datasets, and also compare how it performs vis-a-vis supervised learning models.