 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeiT-LT Distillation Strikes Back for Vision Transformer Training on Long-Tailed Datasets
Apr 03, 2024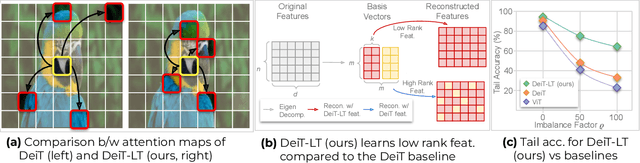
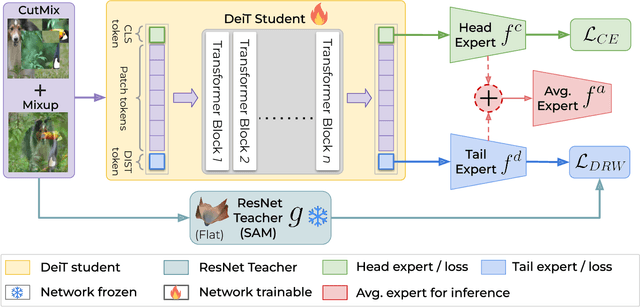
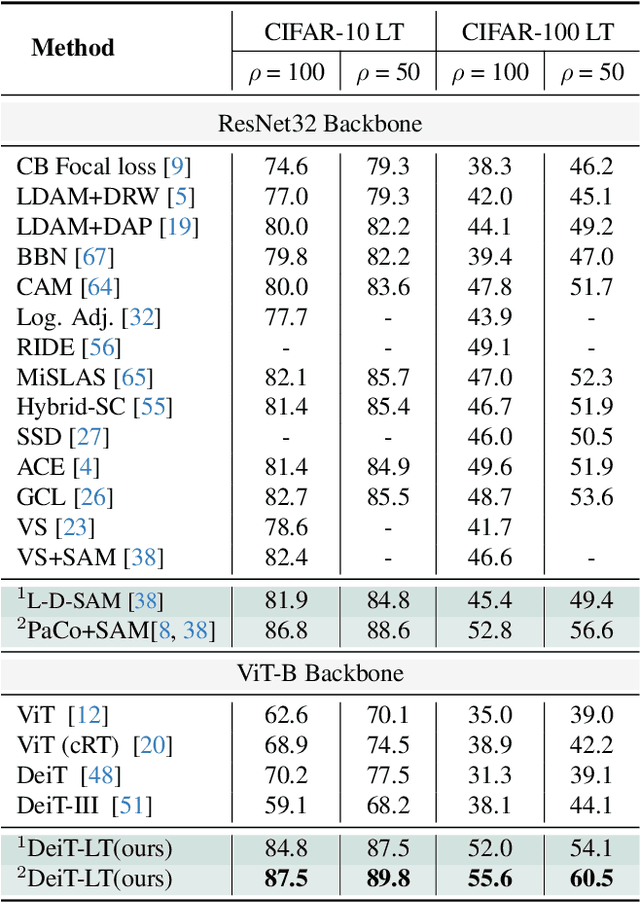
Vision Transformer (ViT) has emerged as a prominent architecture for various computer vision tasks. In ViT, we divide the input image into patch tokens and process them through a stack of self attention blocks. However, unlike Convolutional Neural Networks (CNN), ViTs simple architecture has no informative inductive bias (e.g., locality,etc. ). Due to this, ViT requires a large amount of data for pre-training. Various data efficient approaches (DeiT) have been proposed to train ViT on balanced datasets effectively. However, limited literature discusses the use of ViT for datasets with long-tailed imbalances. In this work, we introduce DeiT-LT to tackle the problem of training ViTs from scratch on long-tailed datasets. In DeiT-LT, we introduce an efficient and effective way of distillation from CNN via distillation DIST token by using out-of-distribution images and re-weighting the distillation loss to enhance focus on tail classes. This leads to the learning of local CNN-like features in early ViT blocks, improving generalization for tail classes. Further, to mitigate overfitting, we propose distilling from a flat CNN teacher, which leads to learning low-rank generalizable features for DIST tokens across all ViT blocks. With the proposed DeiT-LT scheme, the distillation DIST token becomes an expert on the tail classes, and the classifier CLS token becomes an expert on the head classes. The experts help to effectively learn features corresponding to both the majority and minority classes using a distinct set of tokens within the same ViT architecture. We show the effectiveness of DeiT-LT for training ViT from scratch on datasets ranging from small-scale CIFAR-10 LT to large-scale iNaturalist-2018.
Aligning Non-Causal Factors for Transformer-Based Source-Free Domain Adaptation
Nov 27, 2023
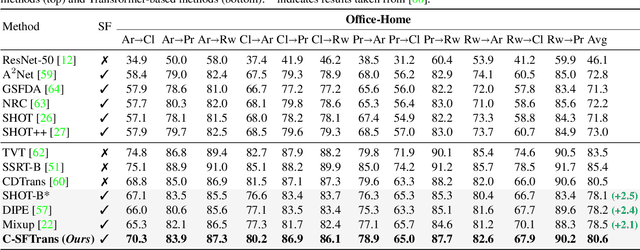


Conventional domain adaptation algorithms aim to achieve better generalization by aligning only the task-discriminative causal factors between a source and target domain. However, we find that retaining the spurious correlation between causal and non-causal factors plays a vital role in bridging the domain gap and improving target adaptation. Therefore, we propose to build a framework that disentangles and supports causal factor alignment by aligning the non-causal factors first. We also investigate and find that the strong shape bias of vision transformers, coupled with its multi-head attention, make it a suitable architecture for realizing our proposed disentanglement. Hence, we propose to build a Causality-enforcing Source-Free Transformer framework (C-SFTrans) to achieve disentanglement via a novel two-stage alignment approach: a) non-causal factor alignment: non-causal factors are aligned using a style classification task which leads to an overall global alignment, b) task-discriminative causal factor alignment: causal factors are aligned via target adaptation. We are the first to investigate the role of vision transformers (ViTs) in a privacy-preserving source-free setting. Our approach achieves state-of-the-art results in several DA benchmarks.
Distilling from Vision-Language Models for Improved OOD Generalization in Vision Tasks
Oct 12, 2023Vision-Language Models (VLMs) such as CLIP are trained on large amounts of image-text pairs, resulting in remarkable generalization across several data distributions. The prohibitively expensive training and data collection/curation costs of these models make them valuable Intellectual Property (IP) for organizations. This motivates a vendor-client paradigm, where a vendor trains a large-scale VLM and grants only input-output access to clients on a pay-per-query basis in a black-box setting. The client aims to minimize inference cost by distilling the VLM to a student model using the limited available task-specific data, and further deploying this student model in the downstream application. While naive distillation largely improves the In-Domain (ID) accuracy of the student, it fails to transfer the superior out-of-distribution (OOD) generalization of the VLM teacher using the limited available labeled images. To mitigate this, we propose Vision-Language to Vision-Align, Distill, Predict (VL2V-ADiP), which first aligns the vision and language modalities of the teacher model with the vision modality of a pre-trained student model, and further distills the aligned VLM embeddings to the student. This maximally retains the pre-trained features of the student, while also incorporating the rich representations of the VLM image encoder and the superior generalization of the text embeddings. The proposed approach achieves state-of-the-art results on the standard Domain Generalization benchmarks in a black-box teacher setting, and also when weights of the VLM are accessible.
Domain-Specificity Inducing Transformers for Source-Free Domain Adaptation
Aug 27, 2023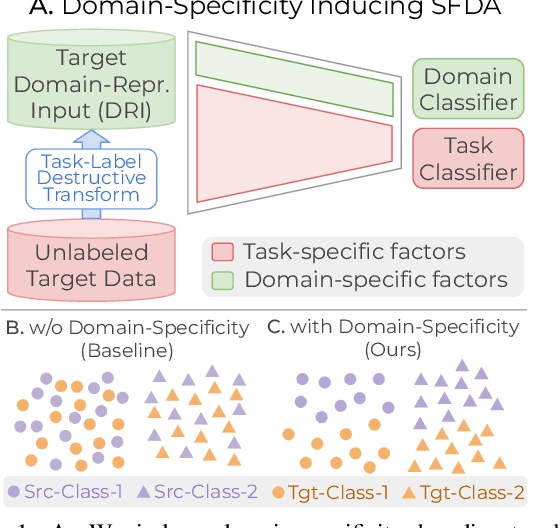
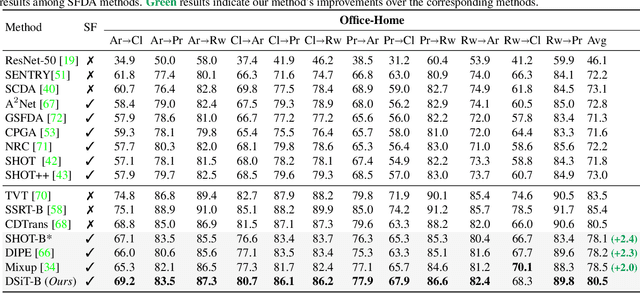
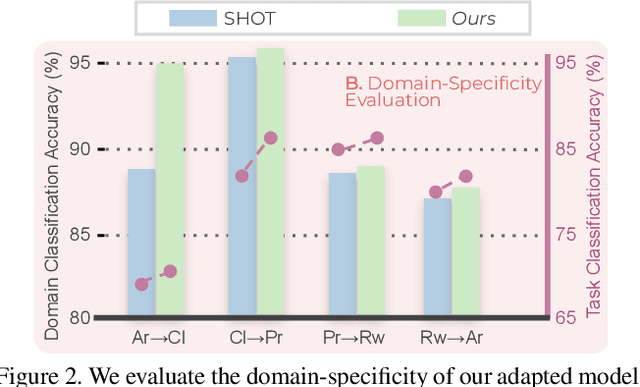

Conventional Domain Adaptation (DA) methods aim to learn domain-invariant feature representations to improve the target adaptation performance. However, we motivate that domain-specificity is equally important since in-domain trained models hold crucial domain-specific properties that are beneficial for adaptation. Hence, we propose to build a framework that supports disentanglement and learning of domain-specific factors and task-specific factors in a unified model. Motivated by the success of vision transformers in several multi-modal vision problems, we find that queries could be leveraged to extract the domain-specific factors. Hence, we propose a novel Domain-specificity-inducing Transformer (DSiT) framework for disentangling and learning both domain-specific and task-specific factors. To achieve disentanglement, we propose to construct novel Domain-Representative Inputs (DRI) with domain-specific information to train a domain classifier with a novel domain token. We are the first to utilize vision transformers for domain adaptation in a privacy-oriented source-free setting, and our approach achieves state-of-the-art performance on single-source, multi-source, and multi-target benchmarks
Interpretability for Multimodal Emotion Recognition using Concept Activation Vectors
Feb 02, 2022
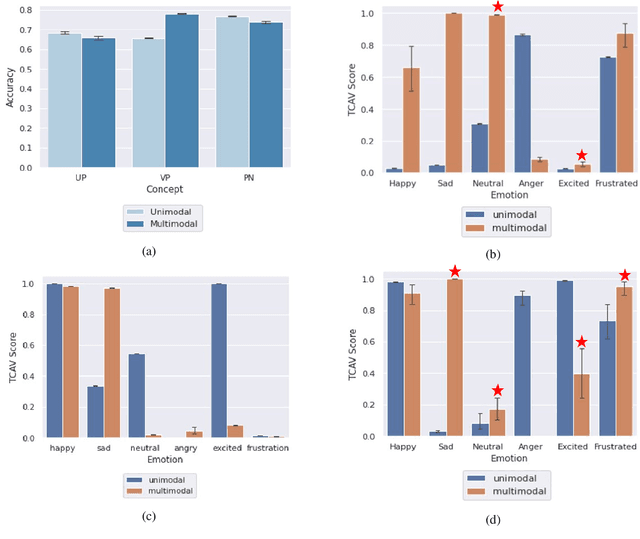
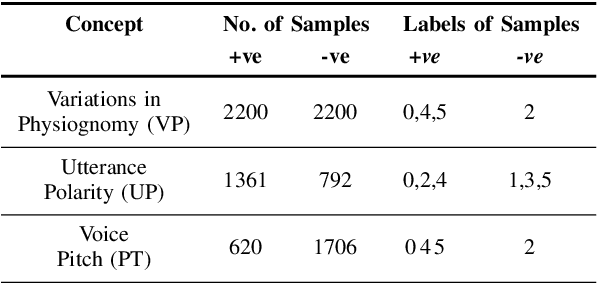
Multimodal Emotion Recognition refers to the classification of input video sequences into emotion labels based on multiple input modalities (usually video, audio and text). In recent years, Deep Neural networks have shown remarkable performance in recognizing human emotions, and are on par with human-level performance on this task. Despite the recent advancements in this field, emotion recognition systems are yet to be accepted for real world setups due to the obscure nature of their reasoning and decision-making process. Most of the research in this field deals with novel architectures to improve the performance for this task, with a few attempts at providing explanations for these models' decisions. In this paper, we address the issue of interpretability for neural networks in the context of emotion recognition using Concept Activation Vectors (CAVs). To analyse the model's latent space, we define human-understandable concepts specific to Emotion AI and map them to the widely-used IEMOCAP multimodal database. We then evaluate the influence of our proposed concepts at multiple layers of the Bi-directional Contextual LSTM (BC-LSTM) network to show that the reasoning process of neural networks for emotion recognition can be represented using human-understandable concepts. Finally, we perform hypothesis testing on our proposed concepts to show that they are significant for interpretability of this task.