 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInHabit: Leveraging Image Foundation Models for Scalable 3D Human Placement
Apr 21, 2026Training embodied agents to understand 3D scenes as humans do requires large-scale data of people meaningfully interacting with diverse environments, yet such data is scarce. Real-world motion capture is costly and limited to controlled settings, while existing synthetic datasets rely on simple geometric heuristics that ignore rich scene context. In contrast, 2D foundation models trained on internet-scale data have implicitly acquired commonsense knowledge of human-environment interactions. To transfer this knowledge into 3D, we introduce InHabit, a fully automatic and scalable data generator for populating 3D scenes with interacting humans. InHabit follows a render-generate-lift principle: given a rendered 3D scene, a vision-language model proposes contextually meaningful actions, an image-editing model inserts a human, and an optimization procedure lifts the edited result into physically plausible SMPL-X bodies aligned with the scene geometry. Applied to Habitat-Matterport3D, InHabit produces the first large-scale photorealistic 3D human-scene interaction dataset, containing 78K samples across 800 building-scale scenes with complete 3D geometry, SMPL-X bodies, and RGB images. Augmenting standard training data with our samples improves RGB-based 3D human-scene reconstruction and contact estimation, and in a perceptual user study our data is preferred in 78% of cases over the state of the art.
GRAFT: Geometric Refinement and Fitting Transformer for Human Scene Reconstruction
Apr 21, 2026Reconstructing physically plausible 3D human-scene interactions (HSI) from a single image currently presents a trade-off: optimization based methods offer accurate contact but are slow (~20s), while feed-forward approaches are fast yet lack explicit interaction reasoning, producing floating and interpenetration artifacts. Our key insight is that geometry-based human--scene fitting can be amortized into fast feed-forward inference. We present GRAFT (Geometric Refinement And Fitting Transformer), a learned HSI prior that predicts Interaction Gradients: corrective parameter updates that iteratively refine human meshes by reasoning about their 3D relationship to the surrounding scene. GRAFT encodes the interaction state into compact body-anchored tokens, each grounded in the scene geometry via Geometric Probes that capture spatial relationships with nearby surfaces. A lightweight transformer recurrently updates human meshes and re-probes the scene, ensuring the final pose aligns with both learned priors and observed geometry. GRAFT operates either as an end-to-end reconstructor using image features, or with geometry alone as a transferable plug-and-play HSI prior that improves feed-forward methods without retraining. Experiments show GRAFT improves interaction quality by up to 113% over state-of-the-art feed-forward methods and matches optimization-based interaction quality at ${\sim}50{\times}$ lower runtime, while generalizing seamlessly to in-the-wild multi-person scenes and being preferred in 64.8% of three-way user study. Project page: https://pradyumnaym.github.io/graft .
Aligning Non-Causal Factors for Transformer-Based Source-Free Domain Adaptation
Nov 27, 2023
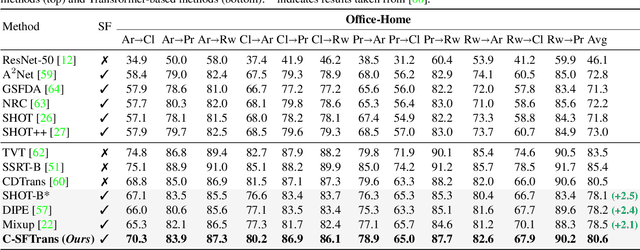


Conventional domain adaptation algorithms aim to achieve better generalization by aligning only the task-discriminative causal factors between a source and target domain. However, we find that retaining the spurious correlation between causal and non-causal factors plays a vital role in bridging the domain gap and improving target adaptation. Therefore, we propose to build a framework that disentangles and supports causal factor alignment by aligning the non-causal factors first. We also investigate and find that the strong shape bias of vision transformers, coupled with its multi-head attention, make it a suitable architecture for realizing our proposed disentanglement. Hence, we propose to build a Causality-enforcing Source-Free Transformer framework (C-SFTrans) to achieve disentanglement via a novel two-stage alignment approach: a) non-causal factor alignment: non-causal factors are aligned using a style classification task which leads to an overall global alignment, b) task-discriminative causal factor alignment: causal factors are aligned via target adaptation. We are the first to investigate the role of vision transformers (ViTs) in a privacy-preserving source-free setting. Our approach achieves state-of-the-art results in several DA benchmarks.
Non-Local Latent Relation Distillation for Self-Adaptive 3D Human Pose Estimation
Apr 06, 2022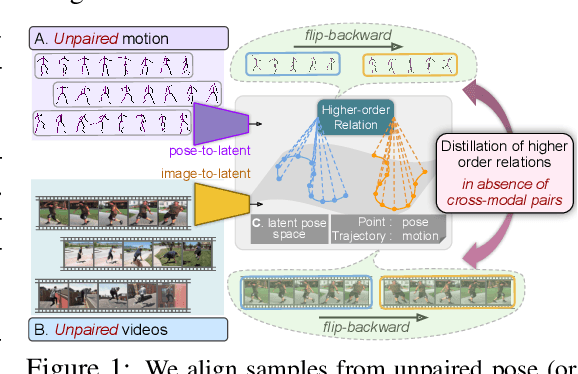
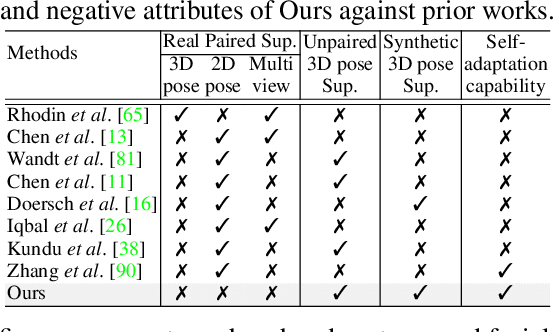
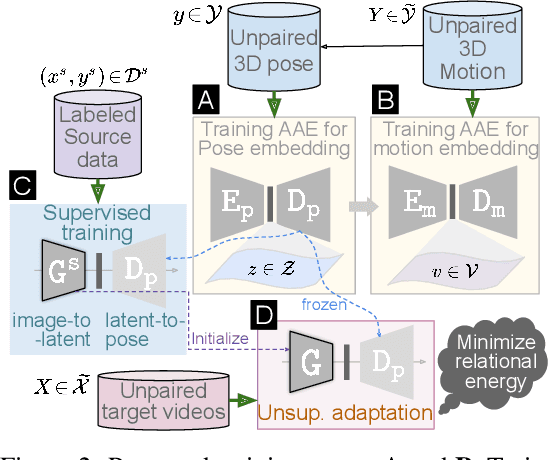
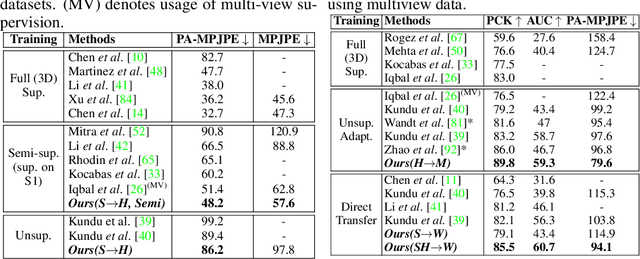
Available 3D human pose estimation approaches leverage different forms of strong (2D/3D pose) or weak (multi-view or depth) paired supervision. Barring synthetic or in-studio domains, acquiring such supervision for each new target environment is highly inconvenient. To this end, we cast 3D pose learning as a self-supervised adaptation problem that aims to transfer the task knowledge from a labeled source domain to a completely unpaired target. We propose to infer image-to-pose via two explicit mappings viz. image-to-latent and latent-to-pose where the latter is a pre-learned decoder obtained from a prior-enforcing generative adversarial auto-encoder. Next, we introduce relation distillation as a means to align the unpaired cross-modal samples i.e. the unpaired target videos and unpaired 3D pose sequences. To this end, we propose a new set of non-local relations in order to characterize long-range latent pose interactions unlike general contrastive relations where positive couplings are limited to a local neighborhood structure. Further, we provide an objective way to quantify non-localness in order to select the most effective relation set. We evaluate different self-adaptation settings and demonstrate state-of-the-art 3D human pose estimation performance on standard benchmarks.
Uncertainty-Aware Adaptation for Self-Supervised 3D Human Pose Estimation
Mar 29, 2022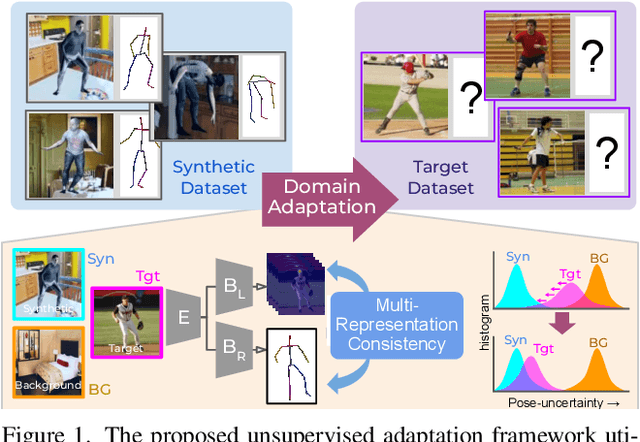

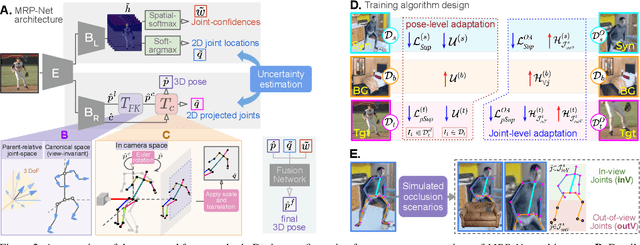
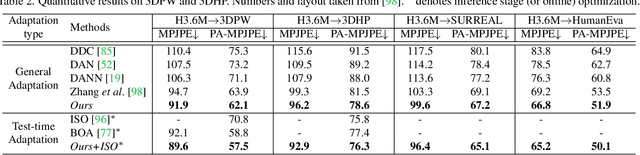
The advances in monocular 3D human pose estimation are dominated by supervised techniques that require large-scale 2D/3D pose annotations. Such methods often behave erratically in the absence of any provision to discard unfamiliar out-of-distribution data. To this end, we cast the 3D human pose learning as an unsupervised domain adaptation problem. We introduce MRP-Net that constitutes a common deep network backbone with two output heads subscribing to two diverse configurations; a) model-free joint localization and b) model-based parametric regression. Such a design allows us to derive suitable measures to quantify prediction uncertainty at both pose and joint level granularity. While supervising only on labeled synthetic samples, the adaptation process aims to minimize the uncertainty for the unlabeled target images while maximizing the same for an extreme out-of-distribution dataset (backgrounds). Alongside synthetic-to-real 3D pose adaptation, the joint-uncertainties allow expanding the adaptation to work on in-the-wild images even in the presence of occlusion and truncation scenarios. We present a comprehensive evaluation of the proposed approach and demonstrate state-of-the-art performance on benchmark datasets.