 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubimage Overlap Prediction: Task-Aligned Self-Supervised Pretraining For Semantic Segmentation In Remote Sensing Imagery
Jan 05, 2026Self-supervised learning (SSL) methods have become a dominant paradigm for creating general purpose models whose capabilities can be transferred to downstream supervised learning tasks. However, most such methods rely on vast amounts of pretraining data. This work introduces Subimage Overlap Prediction, a novel self-supervised pretraining task to aid semantic segmentation in remote sensing imagery that uses significantly lesser pretraining imagery. Given an image, a sub-image is extracted and the model is trained to produce a semantic mask of the location of the extracted sub-image within the original image. We demonstrate that pretraining with this task results in significantly faster convergence, and equal or better performance (measured via mIoU) on downstream segmentation. This gap in convergence and performance widens when labeled training data is reduced. We show this across multiple architecture types, and with multiple downstream datasets. We also show that our method matches or exceeds performance while requiring significantly lesser pretraining data relative to other SSL methods. Code and model weights are provided at \href{https://github.com/sharmalakshay93/subimage-overlap-prediction}{github.com/sharmalakshay93/subimage-overlap-prediction}.
Landsat-Bench: Datasets and Benchmarks for Landsat Foundation Models
Jun 10, 2025The Landsat program offers over 50 years of globally consistent Earth imagery. However, the lack of benchmarks for this data constrains progress towards Landsat-based Geospatial Foundation Models (GFM). In this paper, we introduce Landsat-Bench, a suite of three benchmarks with Landsat imagery that adapt from existing remote sensing datasets -- EuroSAT-L, BigEarthNet-L, and LC100-L. We establish baseline and standardized evaluation methods across both common architectures and Landsat foundation models pretrained on the SSL4EO-L dataset. Notably, we provide evidence that SSL4EO-L pretrained GFMs extract better representations for downstream tasks in comparison to ImageNet, including performance gains of +4% OA and +5.1% mAP on EuroSAT-L and BigEarthNet-L.
SuoiAI: Building a Dataset for Aquatic Invertebrates in Vietnam
Apr 21, 2025
Understanding and monitoring aquatic biodiversity is critical for ecological health and conservation efforts. This paper proposes SuoiAI, an end-to-end pipeline for building a dataset of aquatic invertebrates in Vietnam and employing machine learning (ML) techniques for species classification. We outline the methods for data collection, annotation, and model training, focusing on reducing annotation effort through semi-supervised learning and leveraging state-of-the-art object detection and classification models. Our approach aims to overcome challenges such as data scarcity, fine-grained classification, and deployment in diverse environmental conditions.
Look Before You Leap: Socially Acceptable High-Speed Ground Robot Navigation in Crowded Hallways
Mar 20, 2024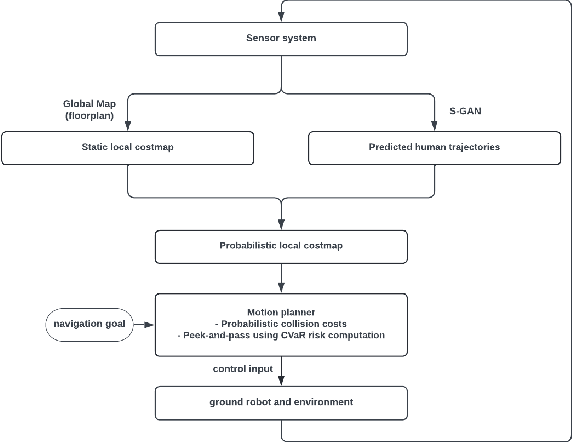
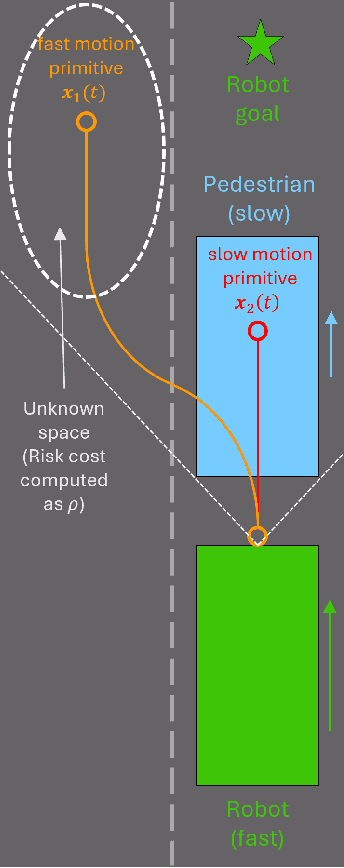
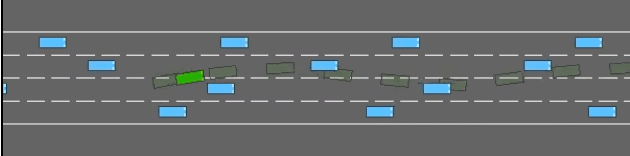
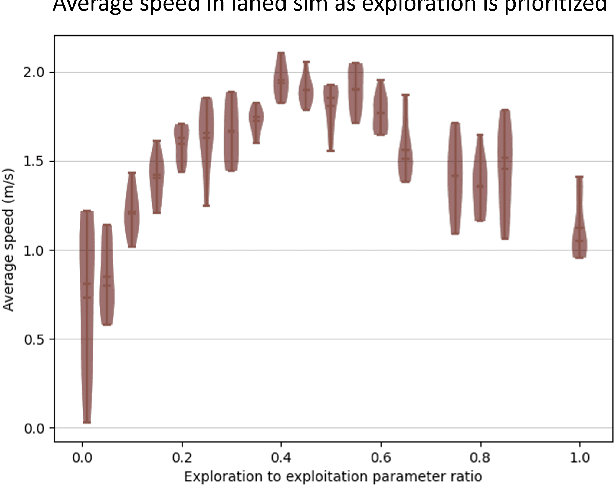
To operate safely and efficiently, autonomous warehouse/delivery robots must be able to accomplish tasks while navigating in dynamic environments and handling the large uncertainties associated with the motions/behaviors of other robots and/or humans. A key scenario in such environments is the hallway problem, where robots must operate in the same narrow corridor as human traffic going in one or both directions. Traditionally, robot planners have tended to focus on socially acceptable behavior in the hallway scenario at the expense of performance. This paper proposes a planner that aims to address the consequent "robot freezing problem" in hallways by allowing for "peek-and-pass" maneuvers. We then go on to demonstrate in simulation how this planner improves robot time to goal without violating social norms. Finally, we show initial hardware demonstrations of this planner in the real world.
EVORA: Deep Evidential Traversability Learning for Risk-Aware Off-Road Autonomy
Nov 10, 2023

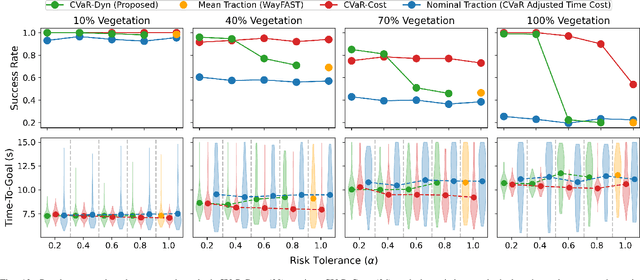

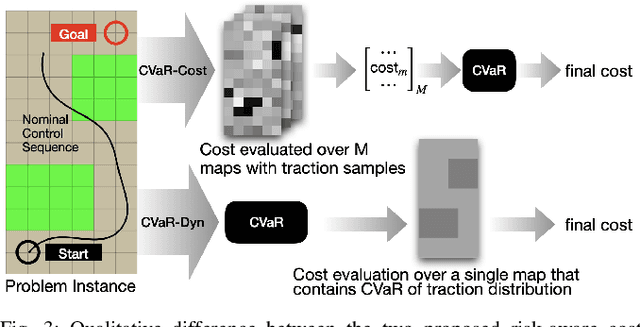
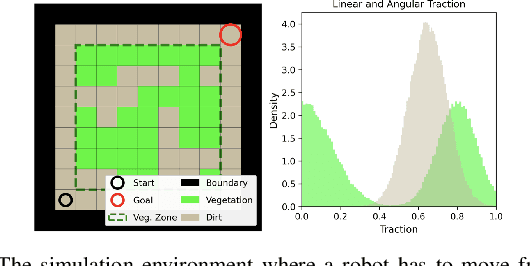
Traversing terrain with good traction is crucial for achieving fast off-road navigation. Instead of manually designing costs based on terrain features, existing methods learn terrain properties directly from data via self-supervision, but challenges remain to properly quantify and mitigate risks due to uncertainties in learned models. This work efficiently quantifies both aleatoric and epistemic uncertainties by learning discrete traction distributions and probability densities of the traction predictor's latent features. Leveraging evidential deep learning, we parameterize Dirichlet distributions with the network outputs and propose a novel uncertainty-aware squared Earth Mover's distance loss with a closed-form expression that improves learning accuracy and navigation performance. The proposed risk-aware planner simulates state trajectories with the worst-case expected traction to handle aleatoric uncertainty, and penalizes trajectories moving through terrain with high epistemic uncertainty. Our approach is extensively validated in simulation and on wheeled and quadruped robots, showing improved navigation performance compared to methods that assume no slip, assume the expected traction, or optimize for the worst-case expected cost.
Distilling from Vision-Language Models for Improved OOD Generalization in Vision Tasks
Oct 12, 2023Vision-Language Models (VLMs) such as CLIP are trained on large amounts of image-text pairs, resulting in remarkable generalization across several data distributions. The prohibitively expensive training and data collection/curation costs of these models make them valuable Intellectual Property (IP) for organizations. This motivates a vendor-client paradigm, where a vendor trains a large-scale VLM and grants only input-output access to clients on a pay-per-query basis in a black-box setting. The client aims to minimize inference cost by distilling the VLM to a student model using the limited available task-specific data, and further deploying this student model in the downstream application. While naive distillation largely improves the In-Domain (ID) accuracy of the student, it fails to transfer the superior out-of-distribution (OOD) generalization of the VLM teacher using the limited available labeled images. To mitigate this, we propose Vision-Language to Vision-Align, Distill, Predict (VL2V-ADiP), which first aligns the vision and language modalities of the teacher model with the vision modality of a pre-trained student model, and further distills the aligned VLM embeddings to the student. This maximally retains the pre-trained features of the student, while also incorporating the rich representations of the VLM image encoder and the superior generalization of the text embeddings. The proposed approach achieves state-of-the-art results on the standard Domain Generalization benchmarks in a black-box teacher setting, and also when weights of the VLM are accessible.
RAMP: A Risk-Aware Mapping and Planning Pipeline for Fast Off-Road Ground Robot Navigation
Oct 12, 2022
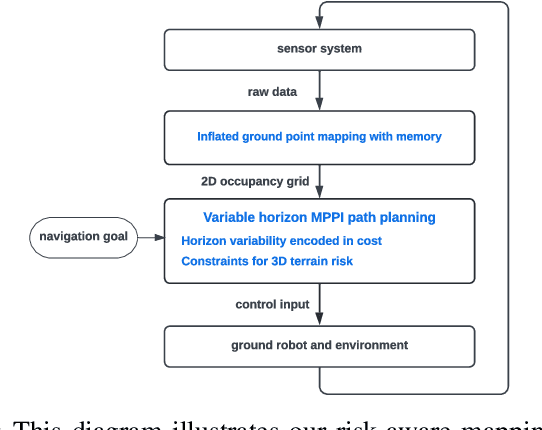

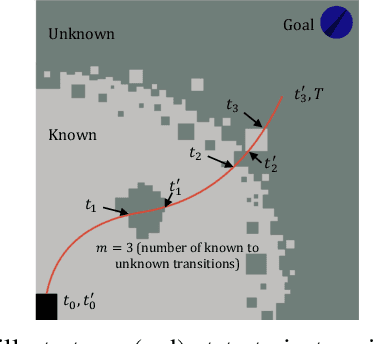
A key challenge in fast ground robot navigation in 3D terrain is balancing robot speed and safety. Recent work has shown that 2.5D maps (2D representations with additional 3D information) are ideal for real-time safe and fast planning. However, raytracing as a prevalent method of generating occupancy grid as the base 2D representation makes the generated map unsafe to plan in, due to inaccurate representation of unknown space. Additionally, existing planners such as MPPI do not reason about speeds in known free and unknown space separately, leading to slow plans. This work therefore first presents ground point inflation as a way to generate accurate occupancy grid maps from classified pointclouds. Then we present an MPPI-based planner with embedded variability in horizon, to maximize speed in known free space while retaining cautionary penetration into unknown space. Finally, we integrate this mapping and planning pipeline with risk constraints arising from 3D terrain, and verify that it enables fast and safe navigation using simulations and a hardware demonstration.
Probabilistic Traversability Model for Risk-Aware Motion Planning in Off-Road Environments
Oct 01, 2022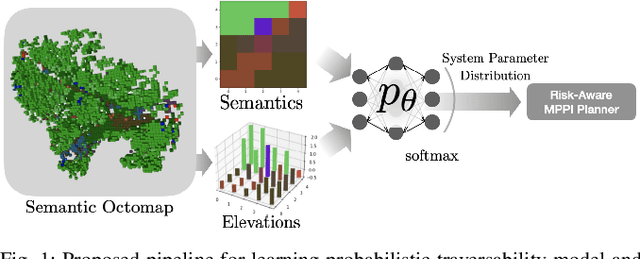
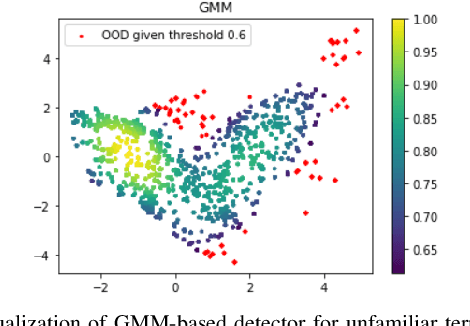
A key challenge in off-road navigation is that even visually similar or semantically identical terrain may have substantially different traction properties. Existing work typically assumes a nominal or expected robot dynamical model for planning, which can lead to degraded performance if the assumed models are not realizable given the terrain properties. In contrast, this work introduces a new probabilistic representation of traversability as a distribution of parameters in the robot's dynamical model that are conditioned on the terrain characteristics. This model is learned in a self-supervised manner by fitting a probability distribution over the parameters identified online, encoded as a neural network that takes terrain features as input. This work then presents two risk-aware planning algorithms that leverage the learned traversability model to plan risk-aware trajectories. Finally, a method for detecting unfamiliar terrain with respect to the training data is introduced based on a Gaussian Mixture Model fit to the latent space of the trained model. Experiments demonstrate that the proposed approach outperforms existing work that assumes nominal or expected robot dynamics in both success rate and completion time for representative navigation tasks. Furthermore, when the proposed approach is deployed in an unseen environment, excluding unfamiliar terrains during planning leads to improved success rate.
Neural Image Captioning
Jul 02, 2019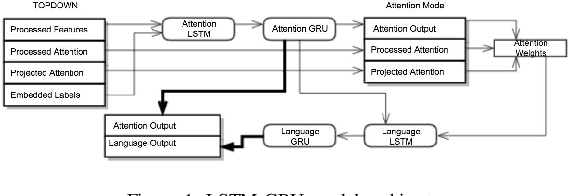



In recent years, the biggest advances in major Computer Vision tasks, such as object recognition, handwritten-digit identification, facial recognition, and many others., have all come through the use of Convolutional Neural Networks (CNNs). Similarly, in the domain of Natural Language Processing, Recurrent Neural Networks (RNNs), and Long Short Term Memory networks (LSTMs) in particular, have been crucial to some of the biggest breakthroughs in performance for tasks such as machine translation, part-of-speech tagging, sentiment analysis, and many others. These individual advances have greatly benefited tasks even at the intersection of NLP and Computer Vision, and inspired by this success, we studied some existing neural image captioning models that have proven to work well. In this work, we study some existing captioning models that provide near state-of-the-art performances, and try to enhance one such model. We also present a simple image captioning model that makes use of a CNN, an LSTM, and the beam search1 algorithm, and study its performance based on various qualitative and quantitative metrics.
Natural Language Understanding with the Quora Question Pairs Dataset
Jul 01, 2019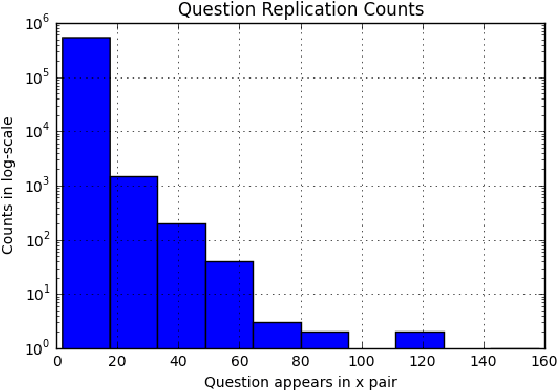
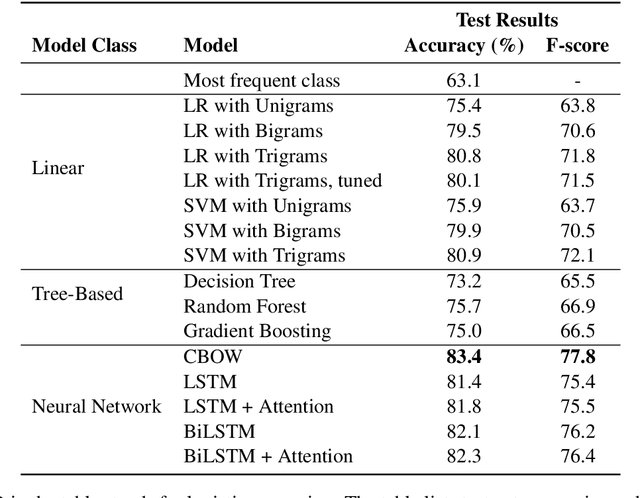
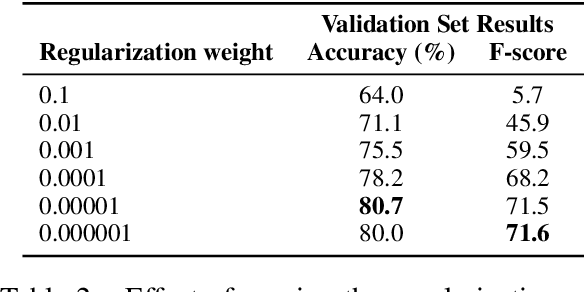

This paper explores the task Natural Language Understanding (NLU) by looking at duplicate question detection in the Quora dataset. We conducted extensive exploration of the dataset and used various machine learning models, including linear and tree-based models. Our final finding was that a simple Continuous Bag of Words neural network model had the best performance, outdoing more complicated recurrent and attention based models. We also conducted error analysis and found some subjectivity in the labeling of the dataset.