 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Image Captioning
Jul 02, 2019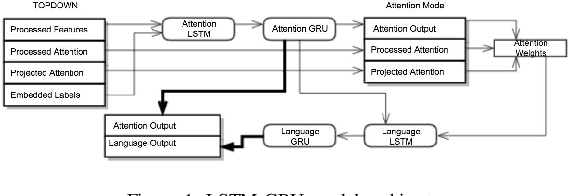



In recent years, the biggest advances in major Computer Vision tasks, such as object recognition, handwritten-digit identification, facial recognition, and many others., have all come through the use of Convolutional Neural Networks (CNNs). Similarly, in the domain of Natural Language Processing, Recurrent Neural Networks (RNNs), and Long Short Term Memory networks (LSTMs) in particular, have been crucial to some of the biggest breakthroughs in performance for tasks such as machine translation, part-of-speech tagging, sentiment analysis, and many others. These individual advances have greatly benefited tasks even at the intersection of NLP and Computer Vision, and inspired by this success, we studied some existing neural image captioning models that have proven to work well. In this work, we study some existing captioning models that provide near state-of-the-art performances, and try to enhance one such model. We also present a simple image captioning model that makes use of a CNN, an LSTM, and the beam search1 algorithm, and study its performance based on various qualitative and quantitative metrics.