 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSumo: Dynamic and Generalizable Whole-Body Loco-Manipulation
Apr 09, 2026This paper presents a sim-to-real approach that enables legged robots to dynamically manipulate large and heavy objects with whole-body dexterity. Our key insight is that by performing test-time steering of a pre-trained whole-body control policy with a sample-based planner, we can enable these robots to solve a variety of dynamic loco-manipulation tasks. Interestingly, we find our method generalizes to a diverse set of objects and tasks with no additional tuning or training, and can be further enhanced by flexibly adjusting the cost function at test time. We demonstrate the capabilities of our approach through a variety of challenging loco-manipulation tasks on a Spot quadruped robot in the real world, including uprighting a tire heavier than the robot's nominal lifting capacity and dragging a crowd-control barrier larger and taller than the robot itself. Additionally, we show that the same approach can be generalized to humanoid loco-manipulation tasks, such as opening a door and pushing a table, in simulation. Project code and videos are available at \href{https://sumo.rai-inst.com/}{https://sumo.rai-inst.com/}.
EVORA: Deep Evidential Traversability Learning for Risk-Aware Off-Road Autonomy
Nov 10, 2023

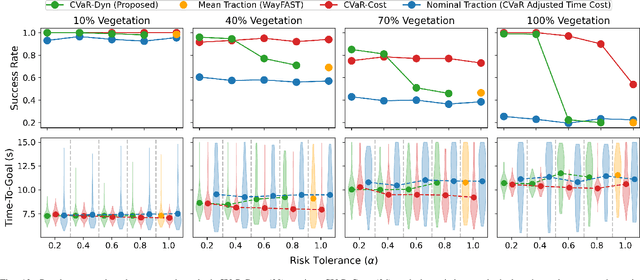

Traversing terrain with good traction is crucial for achieving fast off-road navigation. Instead of manually designing costs based on terrain features, existing methods learn terrain properties directly from data via self-supervision, but challenges remain to properly quantify and mitigate risks due to uncertainties in learned models. This work efficiently quantifies both aleatoric and epistemic uncertainties by learning discrete traction distributions and probability densities of the traction predictor's latent features. Leveraging evidential deep learning, we parameterize Dirichlet distributions with the network outputs and propose a novel uncertainty-aware squared Earth Mover's distance loss with a closed-form expression that improves learning accuracy and navigation performance. The proposed risk-aware planner simulates state trajectories with the worst-case expected traction to handle aleatoric uncertainty, and penalizes trajectories moving through terrain with high epistemic uncertainty. Our approach is extensively validated in simulation and on wheeled and quadruped robots, showing improved navigation performance compared to methods that assume no slip, assume the expected traction, or optimize for the worst-case expected cost.
Learning Portrait Style Representations
Dec 08, 2020



Style analysis of artwork in computer vision predominantly focuses on achieving results in target image generation through optimizing understanding of low level style characteristics such as brush strokes. However, fundamentally different techniques are required to computationally understand and control qualities of art which incorporate higher level style characteristics. We study style representations learned by neural network architectures incorporating these higher level characteristics. We find variation in learned style features from incorporating triplets annotated by art historians as supervision for style similarity. Networks leveraging statistical priors or pretrained on photo collections such as ImageNet can also derive useful visual representations of artwork. We align the impact of these expert human knowledge, statistical, and photo realism priors on style representations with art historical research and use these representations to perform zero-shot classification of artists. To facilitate this work, we also present the first large-scale dataset of portraits prepared for computational analysis.
All Graphs Lead to Rome: Learning Geometric and Cycle-Consistent Representations with Graph Convolutional Networks
Jan 07, 2019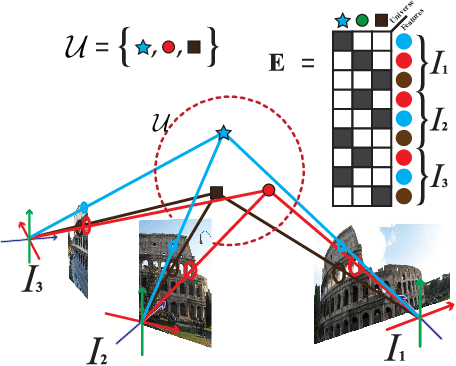

Image feature matching is a fundamental part of many geometric computer vision applications, and using multiple images can improve performance. In this work, we formulate multi-image matching as a graph embedding problem then use a Graph Convolutional Network to learn an appropriate embedding function for aligning image features. We use cycle consistency to train our network in an unsupervised fashion, since ground truth correspondence is difficult or expensive to aquire. In addition, geometric consistency losses can be added at training time, even if the information is not available in the test set, unlike previous approaches that optimize cycle consistency directly. To the best of our knowledge, no other works have used learning for multi-image feature matching. Our experiments show that our method is competitive with other optimization based approaches.
Understanding image motion with group representations
Feb 26, 2018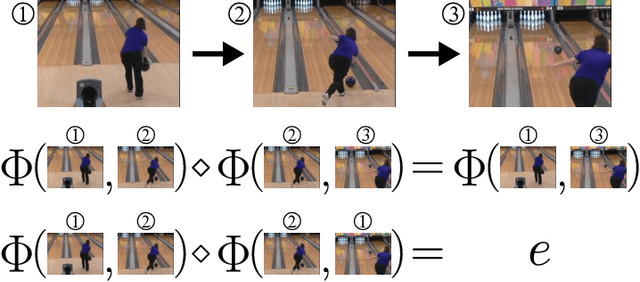


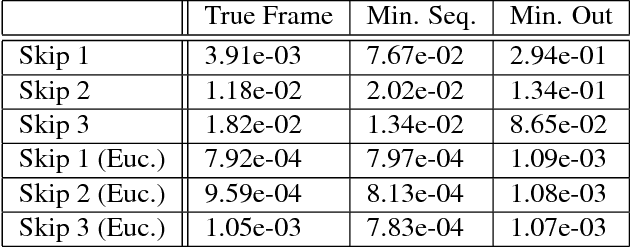
Motion is an important signal for agents in dynamic environments, but learning to represent motion from unlabeled video is a difficult and underconstrained problem. We propose a model of motion based on elementary group properties of transformations and use it to train a representation of image motion. While most methods of estimating motion are based on pixel-level constraints, we use these group properties to constrain the abstract representation of motion itself. We demonstrate that a deep neural network trained using this method captures motion in both synthetic 2D sequences and real-world sequences of vehicle motion, without requiring any labels. Networks trained to respect these constraints implicitly identify the image characteristic of motion in different sequence types. In the context of vehicle motion, this method extracts information useful for localization, tracking, and odometry. Our results demonstrate that this representation is useful for learning motion in the general setting where explicit labels are difficult to obtain.
Fast, Robust, Continuous Monocular Egomotion Computation
Feb 16, 2016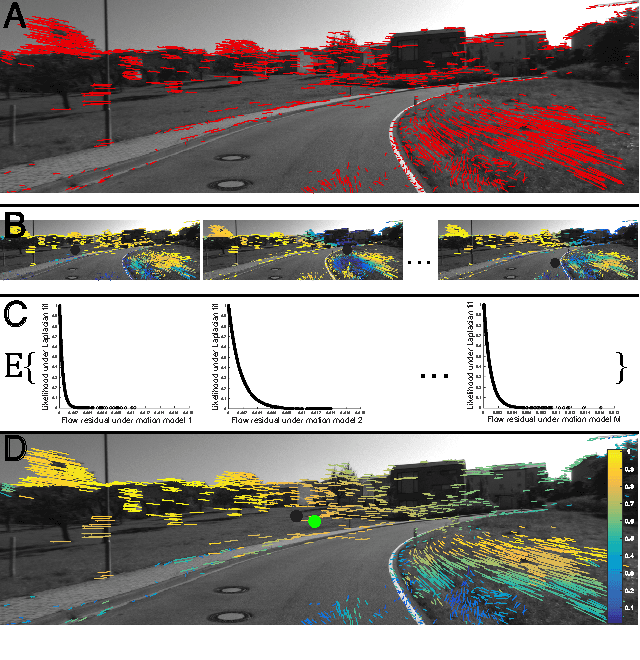

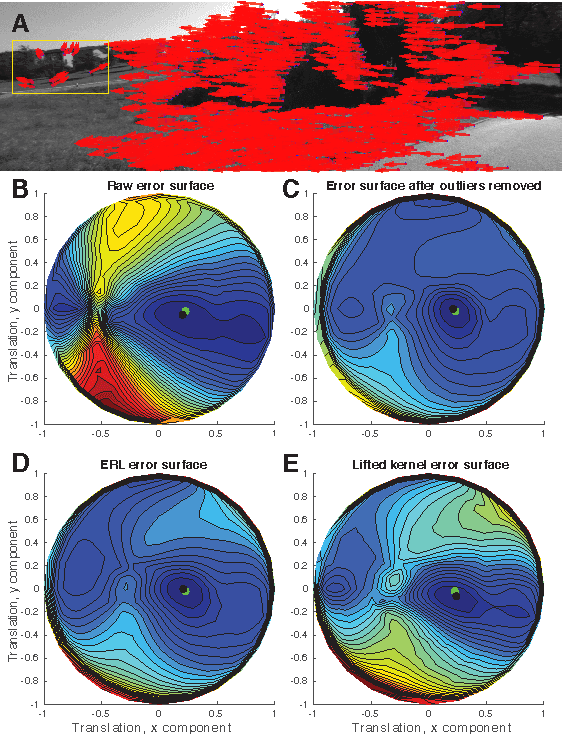

We propose robust methods for estimating camera egomotion in noisy, real-world monocular image sequences in the general case of unknown observer rotation and translation with two views and a small baseline. This is a difficult problem because of the nonconvex cost function of the perspective camera motion equation and because of non-Gaussian noise arising from noisy optical flow estimates and scene non-rigidity. To address this problem, we introduce the expected residual likelihood method (ERL), which estimates confidence weights for noisy optical flow data using likelihood distributions of the residuals of the flow field under a range of counterfactual model parameters. We show that ERL is effective at identifying outliers and recovering appropriate confidence weights in many settings. We compare ERL to a novel formulation of the perspective camera motion equation using a lifted kernel, a recently proposed optimization framework for joint parameter and confidence weight estimation with good empirical properties. We incorporate these strategies into a motion estimation pipeline that avoids falling into local minima. We find that ERL outperforms the lifted kernel method and baseline monocular egomotion estimation strategies on the challenging KITTI dataset, while adding almost no runtime cost over baseline egomotion methods.