 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoDiv: Framework For Measuring Geographical Diversity In Text-To-Image Models
Feb 25, 2026Text-to-image (T2I) models are rapidly gaining popularity, yet their outputs often lack geographical diversity, reinforce stereotypes, and misrepresent regions. Given their broad reach, it is critical to rigorously evaluate how these models portray the world. Existing diversity metrics either rely on curated datasets or focus on surface-level visual similarity, limiting interpretability. We introduce GeoDiv, a framework leveraging large language and vision-language models to assess geographical diversity along two complementary axes: the Socio-Economic Visual Index (SEVI), capturing economic and condition-related cues, and the Visual Diversity Index (VDI), measuring variation in primary entities and backgrounds. Applied to images generated by models such as Stable Diffusion and FLUX.1-dev across $10$ entities and $16$ countries, GeoDiv reveals a consistent lack of diversity and identifies fine-grained attributes where models default to biased portrayals. Strikingly, depictions of countries like India, Nigeria, and Colombia are disproportionately impoverished and worn, reflecting underlying socio-economic biases. These results highlight the need for greater geographical nuance in generative models. GeoDiv provides the first systematic, interpretable framework for measuring such biases, marking a step toward fairer and more inclusive generative systems. Project page: https://abhipsabasu.github.io/geodiv
Where Do Images Come From? Analyzing Captions to Geographically Profile Datasets
Feb 10, 2026Recent studies show that text-to-image models often fail to generate geographically representative images, raising concerns about the representativeness of their training data and motivating the question: which parts of the world do these training examples come from? We geographically profile large-scale multimodal datasets by mapping image-caption pairs to countries based on location information extracted from captions using LLMs. Studying English captions from three widely used datasets (Re-LAION, DataComp1B, and Conceptual Captions) across $20$ common entities (e.g., house, flag), we find that the United States, the United Kingdom, and Canada account for $48.0\%$ of samples, while South American and African countries are severely under-represented with only $1.8\%$ and $3.8\%$ of images, respectively. We observe a strong correlation between a country's GDP and its representation in the data ($ρ= 0.82$). Examining non-English subsets for $4$ languages from the Re-LAION dataset, we find that representation skews heavily toward countries where these languages are predominantly spoken. Additionally, we find that higher representation does not necessarily translate to greater visual or semantic diversity. Finally, analyzing country-specific images generated by Stable Diffusion v1.3 trained on Re-LAION, we show that while generations appear realistic, they are severely limited in their coverage compared to real-world images.
Harnessing Diffusion-Generated Synthetic Images for Fair Image Classification
Nov 11, 2025Image classification systems often inherit biases from uneven group representation in training data. For example, in face datasets for hair color classification, blond hair may be disproportionately associated with females, reinforcing stereotypes. A recent approach leverages the Stable Diffusion model to generate balanced training data, but these models often struggle to preserve the original data distribution. In this work, we explore multiple diffusion-finetuning techniques, e.g., LoRA and DreamBooth, to generate images that more accurately represent each training group by learning directly from their samples. Additionally, in order to prevent a single DreamBooth model from being overwhelmed by excessive intra-group variations, we explore a technique of clustering images within each group and train a DreamBooth model per cluster. These models are then used to generate group-balanced data for pretraining, followed by fine-tuning on real data. Experiments on multiple benchmarks demonstrate that the studied finetuning approaches outperform vanilla Stable Diffusion on average and achieve results comparable to SOTA debiasing techniques like Group-DRO, while surpassing them as the dataset bias severity increases.
Balancing Act: Distribution-Guided Debiasing in Diffusion Models
Feb 28, 2024Diffusion Models (DMs) have emerged as powerful generative models with unprecedented image generation capability. These models are widely used for data augmentation and creative applications. However, DMs reflect the biases present in the training datasets. This is especially concerning in the context of faces, where the DM prefers one demographic subgroup vs others (eg. female vs male). In this work, we present a method for debiasing DMs without relying on additional data or model retraining. Specifically, we propose Distribution Guidance, which enforces the generated images to follow the prescribed attribute distribution. To realize this, we build on the key insight that the latent features of denoising UNet hold rich demographic semantics, and the same can be leveraged to guide debiased generation. We train Attribute Distribution Predictor (ADP) - a small mlp that maps the latent features to the distribution of attributes. ADP is trained with pseudo labels generated from existing attribute classifiers. The proposed Distribution Guidance with ADP enables us to do fair generation. Our method reduces bias across single/multiple attributes and outperforms the baseline by a significant margin for unconditional and text-conditional diffusion models. Further, we present a downstream task of training a fair attribute classifier by rebalancing the training set with our generated data.
Inspecting the Geographical Representativeness of Images from Text-to-Image Models
May 18, 2023



Recent progress in generative models has resulted in models that produce both realistic as well as relevant images for most textual inputs. These models are being used to generate millions of images everyday, and hold the potential to drastically impact areas such as generative art, digital marketing and data augmentation. Given their outsized impact, it is important to ensure that the generated content reflects the artifacts and surroundings across the globe, rather than over-representing certain parts of the world. In this paper, we measure the geographical representativeness of common nouns (e.g., a house) generated through DALL.E 2 and Stable Diffusion models using a crowdsourced study comprising 540 participants across 27 countries. For deliberately underspecified inputs without country names, the generated images most reflect the surroundings of the United States followed by India, and the top generations rarely reflect surroundings from all other countries (average score less than 3 out of 5). Specifying the country names in the input increases the representativeness by 1.44 points on average for DALL.E 2 and 0.75 for Stable Diffusion, however, the overall scores for many countries still remain low, highlighting the need for future models to be more geographically inclusive. Lastly, we examine the feasibility of quantifying the geographical representativeness of generated images without conducting user studies.
All that is English may be Hindi: Enhancing language identification through automatic ranking of likeliness of word borrowing in social media
Jul 29, 2017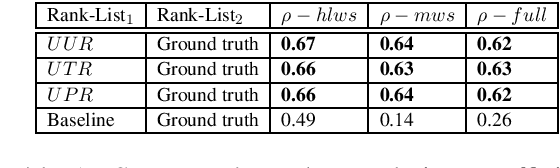
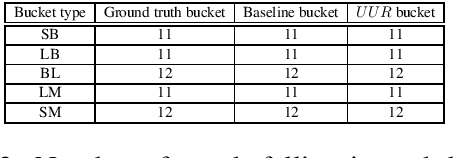

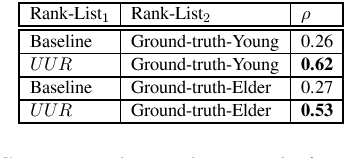
In this paper, we present a set of computational methods to identify the likeliness of a word being borrowed, based on the signals from social media. In terms of Spearman correlation coefficient values, our methods perform more than two times better (nearly 0.62) in predicting the borrowing likeliness compared to the best performing baseline (nearly 0.26) reported in literature. Based on this likeliness estimate we asked annotators to re-annotate the language tags of foreign words in predominantly native contexts. In 88 percent of cases the annotators felt that the foreign language tag should be replaced by native language tag, thus indicating a huge scope for improvement of automatic language identification systems.