 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Augmented LLMs: Expanding Capabilities through Composition
Jan 04, 2024



Foundational models with billions of parameters which have been trained on large corpora of data have demonstrated non-trivial skills in a variety of domains. However, due to their monolithic structure, it is challenging and expensive to augment them or impart new skills. On the other hand, due to their adaptation abilities, several new instances of these models are being trained towards new domains and tasks. In this work, we study the problem of efficient and practical composition of existing foundation models with more specific models to enable newer capabilities. To this end, we propose CALM -- Composition to Augment Language Models -- which introduces cross-attention between models to compose their representations and enable new capabilities. Salient features of CALM are: (i) Scales up LLMs on new tasks by 're-using' existing LLMs along with a few additional parameters and data, (ii) Existing model weights are kept intact, and hence preserves existing capabilities, and (iii) Applies to diverse domains and settings. We illustrate that augmenting PaLM2-S with a smaller model trained on low-resource languages results in an absolute improvement of up to 13\% on tasks like translation into English and arithmetic reasoning for low-resource languages. Similarly, when PaLM2-S is augmented with a code-specific model, we see a relative improvement of 40\% over the base model for code generation and explanation tasks -- on-par with fully fine-tuned counterparts.
XTREME-UP: A User-Centric Scarce-Data Benchmark for Under-Represented Languages
May 24, 2023



Data scarcity is a crucial issue for the development of highly multilingual NLP systems. Yet for many under-represented languages (ULs) -- languages for which NLP re-search is particularly far behind in meeting user needs -- it is feasible to annotate small amounts of data. Motivated by this, we propose XTREME-UP, a benchmark defined by: its focus on the scarce-data scenario rather than zero-shot; its focus on user-centric tasks -- tasks with broad adoption by speakers of high-resource languages; and its focus on under-represented languages where this scarce-data scenario tends to be most realistic. XTREME-UP evaluates the capabilities of language models across 88 under-represented languages over 9 key user-centric technologies including ASR, OCR, MT, and information access tasks that are of general utility. We create new datasets for OCR, autocomplete, semantic parsing, and transliteration, and build on and refine existing datasets for other tasks. XTREME-UP provides methodology for evaluating many modeling scenarios including text-only, multi-modal (vision, audio, and text),supervised parameter tuning, and in-context learning. We evaluate commonly used models on the benchmark. We release all code and scripts to train and evaluate models
CrysGNN : Distilling pre-trained knowledge to enhance property prediction for crystalline materials
Jan 14, 2023In recent years, graph neural network (GNN) based approaches have emerged as a powerful technique to encode complex topological structure of crystal materials in an enriched representation space. These models are often supervised in nature and using the property-specific training data, learn relationship between crystal structure and different properties like formation energy, bandgap, bulk modulus, etc. Most of these methods require a huge amount of property-tagged data to train the system which may not be available for different properties. However, there is an availability of a huge amount of crystal data with its chemical composition and structural bonds. To leverage these untapped data, this paper presents CrysGNN, a new pre-trained GNN framework for crystalline materials, which captures both node and graph level structural information of crystal graphs using a huge amount of unlabelled material data. Further, we extract distilled knowledge from CrysGNN and inject into different state of the art property predictors to enhance their property prediction accuracy. We conduct extensive experiments to show that with distilled knowledge from the pre-trained model, all the SOTA algorithms are able to outperform their own vanilla version with good margins. We also observe that the distillation process provides a significant improvement over the conventional approach of finetuning the pre-trained model. We have released the pre-trained model along with the large dataset of 800K crystal graph which we carefully curated; so that the pretrained model can be plugged into any existing and upcoming models to enhance their prediction accuracy.
Bootstrapping Multilingual Semantic Parsers using Large Language Models
Oct 13, 2022
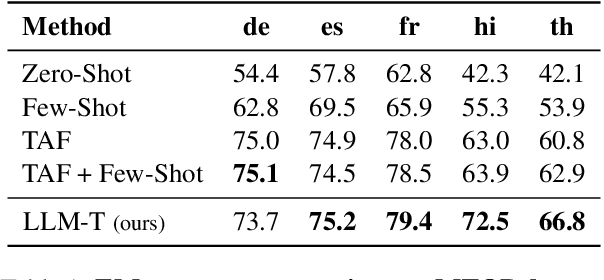

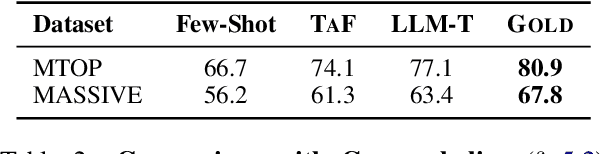
Despite cross-lingual generalization demonstrated by pre-trained multilingual models, the translate-train paradigm of transferring English datasets across multiple languages remains to be the key ingredient for training task-specific multilingual models. However, for many low-resource languages, the availability of a reliable translation service entails significant amounts of costly human-annotated translation pairs. Further, the translation services for low-resource languages may continue to be brittle due to domain mismatch between the task-specific input text and the general-purpose text used while training the translation models. We consider the task of multilingual semantic parsing and demonstrate the effectiveness and flexibility offered by large language models (LLMs) for translating English datasets into several languages via few-shot prompting. We provide (i) Extensive comparisons with prior translate-train methods across 50 languages demonstrating that LLMs can serve as highly effective data translators, outperforming prior translation based methods on 40 out of 50 languages; (ii) A comprehensive study of the key design choices that enable effective data translation via prompted LLMs.
A Data Bootstrapping Recipe for Low Resource Multilingual Relation Classification
Oct 18, 2021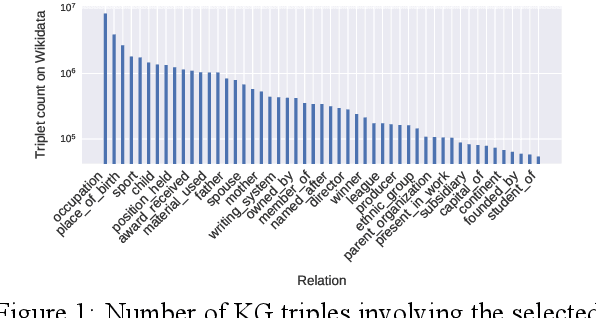

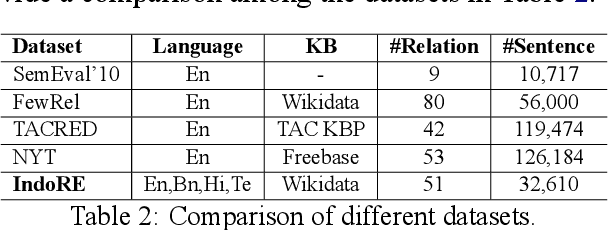
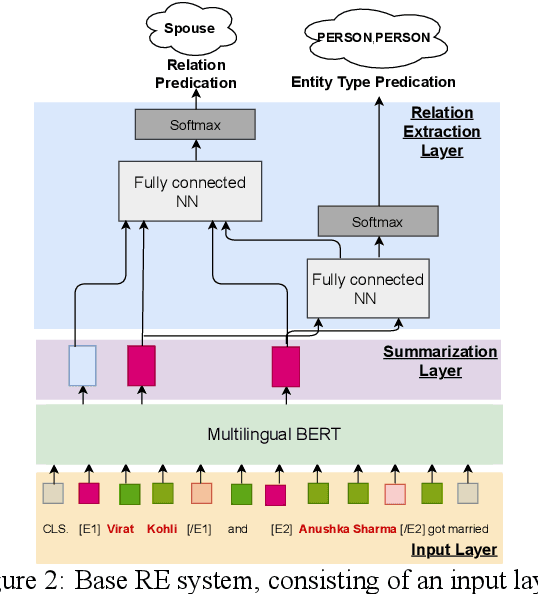
Relation classification (sometimes called 'extraction') requires trustworthy datasets for fine-tuning large language models, as well as for evaluation. Data collection is challenging for Indian languages, because they are syntactically and morphologically diverse, as well as different from resource-rich languages like English. Despite recent interest in deep generative models for Indian languages, relation classification is still not well served by public data sets. In response, we present IndoRE, a dataset with 21K entity and relation tagged gold sentences in three Indian languages, plus English. We start with a multilingual BERT (mBERT) based system that captures entity span positions and type information and provides competitive monolingual relation classification. Using this system, we explore and compare transfer mechanisms between languages. In particular, we study the accuracy efficiency tradeoff between expensive gold instances vs. translated and aligned 'silver' instances. We release the dataset for future research.
Few-shot Controllable Style Transfer for Low-Resource Settings: A Study in Indian Languages
Oct 14, 2021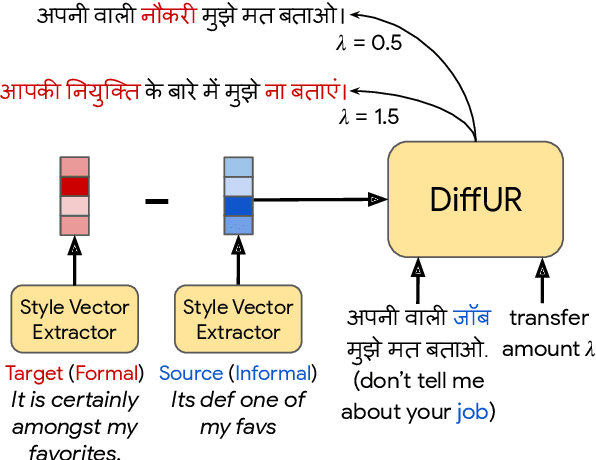
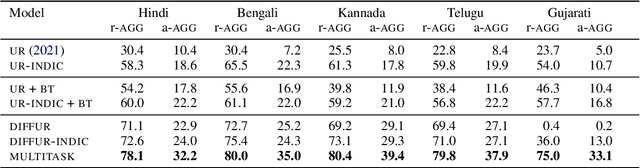
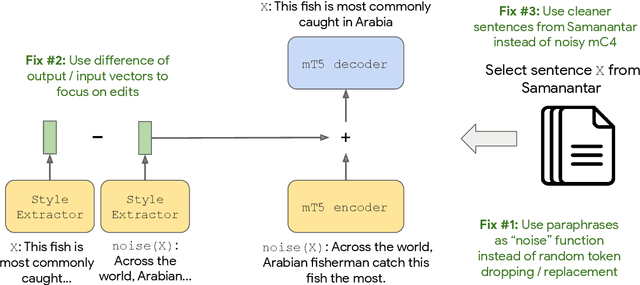
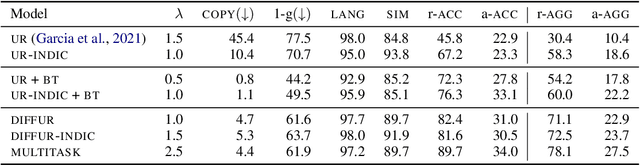
Style transfer is the task of rewriting an input sentence into a target style while approximately preserving its content. While most prior literature assumes access to large style-labelled corpora, recent work (Riley et al. 2021) has attempted "few-shot" style transfer using only 3-10 sentences at inference for extracting the target style. In this work we consider one such low resource setting where no datasets are available: style transfer for Indian languages. We find that existing few-shot methods perform this task poorly, with a strong tendency to copy inputs verbatim. We push the state-of-the-art for few-shot style transfer with a new method modeling the stylistic difference between paraphrases. When compared to prior work using automatic and human evaluations, our model achieves 2-3x better performance and output diversity in formality transfer and code-mixing addition across five Indian languages. Moreover, our method is better able to control the amount of style transfer using an input scalar knob. We report promising qualitative results for several attribute transfer directions, including sentiment transfer, text simplification, gender neutralization and text anonymization, all without retraining the model. Finally we found model evaluation to be difficult due to the lack of evaluation datasets and metrics for Indian languages. To facilitate further research in formality transfer for Indic languages, we crowdsource annotations for 4000 sentence pairs in four languages, and use this dataset to design our automatic evaluation suite.
Fine-grained Sentiment Controlled Text Generation
Jun 17, 2020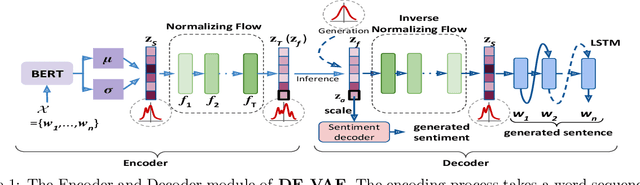
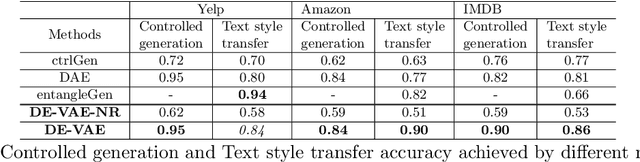
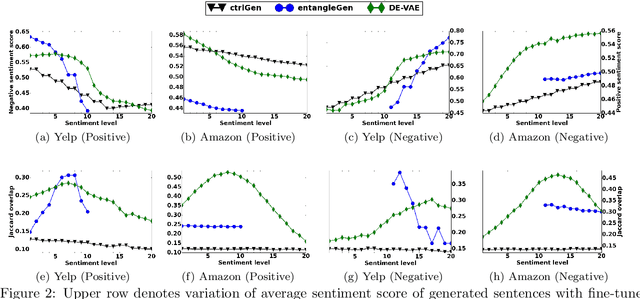

Controlled text generation techniques aim to regulate specific attributes (e.g. sentiment) while preserving the attribute independent content. The state-of-the-art approaches model the specified attribute as a structured or discrete representation while making the content representation independent of it to achieve a better control. However, disentangling the text representation into separate latent spaces overlooks complex dependencies between content and attribute, leading to generation of poorly constructed and not so meaningful sentences. Moreover, such an approach fails to provide a finer control on the degree of attribute change. To address these problems of controlled text generation, in this paper, we propose DE-VAE, a hierarchical framework which captures both information enriched entangled representation and attribute specific disentangled representation in different hierarchies. DE-VAE achieves better control of sentiment as an attribute while preserving the content by learning a suitable lossless transformation network from the disentangled sentiment space to the desired entangled representation. Through feature supervision on a single dimension of the disentangled representation, DE-VAE maps the variation of sentiment to a continuous space which helps in smoothly regulating sentiment from positive to negative and vice versa. Detailed experiments on three publicly available review datasets show the superiority of DE-VAE over recent state-of-the-art approaches.
A Deep Generative Model for Code-Switched Text
Jun 21, 2019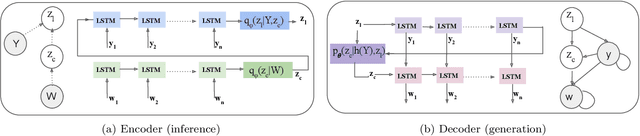
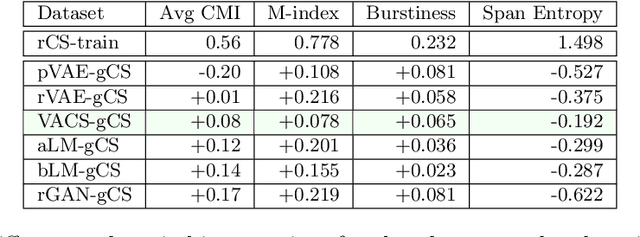
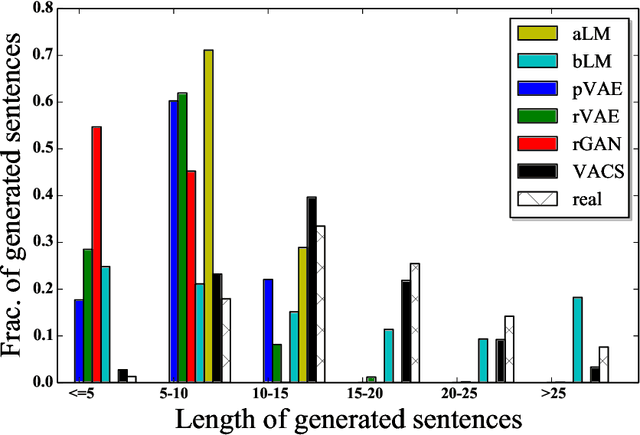

Code-switching, the interleaving of two or more languages within a sentence or discourse is pervasive in multilingual societies. Accurate language models for code-switched text are critical for NLP tasks. State-of-the-art data-intensive neural language models are difficult to train well from scarce language-labeled code-switched text. A potential solution is to use deep generative models to synthesize large volumes of realistic code-switched text. Although generative adversarial networks and variational autoencoders can synthesize plausible monolingual text from continuous latent space, they cannot adequately address code-switched text, owing to their informal style and complex interplay between the constituent languages. We introduce VACS, a novel variational autoencoder architecture specifically tailored to code-switching phenomena. VACS encodes to and decodes from a two-level hierarchical representation, which models syntactic contextual signals in the lower level, and language switching signals in the upper layer. Sampling representations from the prior and decoding them produced well-formed, diverse code-switched sentences. Extensive experiments show that using synthetic code-switched text with natural monolingual data results in significant (33.06%) drop in perplexity.
Improved Sentiment Detection via Label Transfer from Monolingual to Synthetic Code-Switched Text
Jun 13, 2019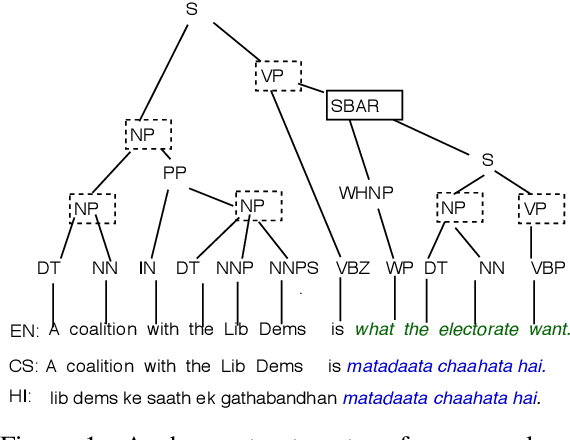
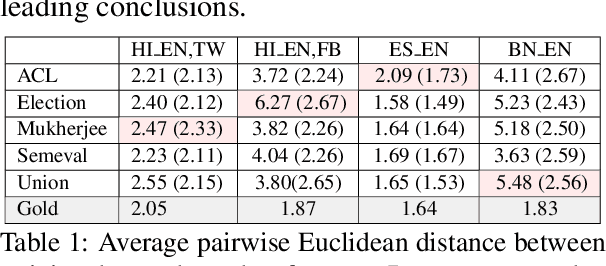
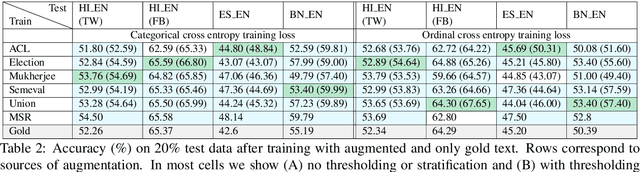

Multilingual writers and speakers often alternate between two languages in a single discourse, a practice called "code-switching". Existing sentiment detection methods are usually trained on sentiment-labeled monolingual text. Manually labeled code-switched text, especially involving minority languages, is extremely rare. Consequently, the best monolingual methods perform relatively poorly on code-switched text. We present an effective technique for synthesizing labeled code-switched text from labeled monolingual text, which is more readily available. The idea is to replace carefully selected subtrees of constituency parses of sentences in the resource-rich language with suitable token spans selected from automatic translations to the resource-poor language. By augmenting scarce human-labeled code-switched text with plentiful synthetic code-switched text, we achieve significant improvements in sentiment labeling accuracy (1.5%, 5.11%, 7.20%) for three different language pairs (English-Hindi, English-Spanish and English-Bengali). We also get significant gains for hate speech detection: 4% improvement using only synthetic text and 6% if augmented with real text.
Designing Random Graph Models Using Variational Autoencoders With Applications to Chemical Design
May 23, 2018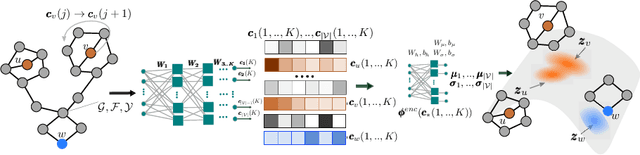
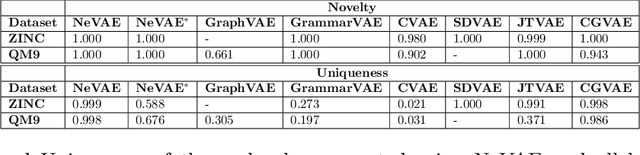
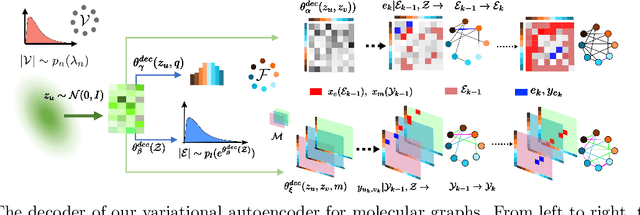

Deep generative models have been praised for their ability to learn smooth latent representation of images, text, and audio, which can then be used to generate new, plausible data. However, current generative models are unable to work with graphs due to their unique characteristics--their underlying structure is not Euclidean or grid-like, they remain isomorphic under permutation of the nodes labels, and they come with a different number of nodes and edges. In this paper, we propose NeVAE, a novel variational autoencoder for graphs, whose encoder and decoder are specially designed to account for the above properties by means of several technical innovations. In addition, by using masking, the decoder is able to guarantee a set of local structural and functional properties in the generated graphs. Experiments reveal that our model is able to learn and mimic the generative process of several well-known random graph models and can be used to discover new molecules more effectively than several state of the art methods. Moreover, by utilizing Bayesian optimization over the continuous latent representation of molecules our model finds, we can also identify molecules that maximize certain desirable properties more effectively than alternatives.