 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXray-Visual Models: Scaling Vision models on Industry Scale Data
Feb 18, 2026We present Xray-Visual, a unified vision model architecture for large-scale image and video understanding trained on industry-scale social media data. Our model leverages over 15 billion curated image-text pairs and 10 billion video-hashtag pairs from Facebook and Instagram, employing robust data curation pipelines that incorporate balancing and noise suppression strategies to maximize semantic diversity while minimizing label noise. We introduce a three-stage training pipeline that combines self-supervised MAE, semi-supervised hashtag classification, and CLIP-style contrastive learning to jointly optimize image and video modalities. Our architecture builds on a Vision Transformer backbone enhanced with efficient token reorganization (EViT) for improved computational efficiency. Extensive experiments demonstrate that Xray-Visual achieves state-of-the-art performance across diverse benchmarks, including ImageNet for image classification, Kinetics and HMDB51 for video understanding, and MSCOCO for cross-modal retrieval. The model exhibits strong robustness to domain shift and adversarial perturbations. We further demonstrate that integrating large language models as text encoders (LLM2CLIP) significantly enhances retrieval performance and generalization capabilities, particularly in real-world environments. Xray-Visual establishes new benchmarks for scalable, multimodal vision models, while maintaining superior accuracy and computational efficiency.
Think Then Embed: Generative Context Improves Multimodal Embedding
Oct 06, 2025There is a growing interest in Universal Multimodal Embeddings (UME), where models are required to generate task-specific representations. While recent studies show that Multimodal Large Language Models (MLLMs) perform well on such tasks, they treat MLLMs solely as encoders, overlooking their generative capacity. However, such an encoding paradigm becomes less effective as instructions become more complex and require compositional reasoning. Inspired by the proven effectiveness of chain-of-thought reasoning, we propose a general Think-Then-Embed (TTE) framework for UME, composed of a reasoner and an embedder. The reasoner MLLM first generates reasoning traces that explain complex queries, followed by an embedder that produces representations conditioned on both the original query and the intermediate reasoning. This explicit reasoning step enables more nuanced understanding of complex multimodal instructions. Our contributions are threefold. First, by leveraging a powerful MLLM reasoner, we achieve state-of-the-art performance on the MMEB-V2 benchmark, surpassing proprietary models trained on massive in-house datasets. Second, to reduce the dependency on large MLLM reasoners, we finetune a smaller MLLM reasoner using high-quality embedding-centric reasoning traces, achieving the best performance among open-source models with a 7% absolute gain over recently proposed models. Third, we investigate strategies for integrating the reasoner and embedder into a unified model for improved efficiency without sacrificing performance.
Robust Learning of Diverse Code Edits
Mar 05, 2025Software engineering activities frequently involve edits to existing code. However, contemporary code language models (LMs) lack the ability to handle diverse types of code-edit requirements. In this work, we attempt to overcome this shortcoming through (1) a novel synthetic data generation pipeline and (2) a robust model adaptation algorithm. Starting with seed code examples and diverse editing criteria, our pipeline generates high-quality samples comprising original and modified code, along with natural language instructions in different styles and verbosity. Today's code LMs come bundled with strong abilities, such as code generation and instruction following, which should not be lost due to fine-tuning. To ensure this, we propose a novel adaptation algorithm, SeleKT, that (a) leverages a dense gradient-based step to identify the weights that are most important for code editing, and (b) does a sparse projection onto the base model to avoid overfitting. Using our approach, we obtain a new series of models NextCoder (adapted from QwenCoder-2.5) that achieves strong results on five code-editing benchmarks, outperforming comparable size models and even several larger ones. We show the generality of our approach on two model families (DeepSeekCoder and QwenCoder), compare against other fine-tuning approaches, and demonstrate robustness by showing retention of code generation abilities post adaptation.
NoFunEval: Funny How Code LMs Falter on Requirements Beyond Functional Correctness
Feb 02, 2024Existing evaluation benchmarks of language models of code (code LMs) focus almost exclusively on whether the LMs can generate functionally-correct code. In real-world software engineering, developers think beyond functional correctness. They have requirements on "how" a functionality should be implemented to meet overall system design objectives like efficiency, security, and maintainability. They would also trust the code LMs more if the LMs demonstrate robust understanding of requirements and code semantics. We propose a new benchmark NoFunEval to evaluate code LMs on non-functional requirements and simple classification instances for both functional and non-functional requirements. We propose a prompting method, Coding Concepts (CoCo), as a way for a developer to communicate the domain knowledge to the LMs. We conduct an extensive evaluation of twenty-two code LMs. Our finding is that they generally falter when tested on our benchmark, hinting at fundamental blindspots in their training setups. Surprisingly, even the classification accuracy on functional-correctness instances derived from the popular HumanEval benchmark is low, calling in question the depth of their comprehension and the source of their success in generating functionally-correct code in the first place. We will release our benchmark and evaluation scripts publicly at https://aka.ms/NoFunEval.
Structured Case-based Reasoning for Inference-time Adaptation of Text-to-SQL parsers
Jan 10, 2023



Inference-time adaptation methods for semantic parsing are useful for leveraging examples from newly-observed domains without repeated fine-tuning. Existing approaches typically bias the decoder by simply concatenating input-output example pairs (cases) from the new domain at the encoder's input in a Seq-to-Seq model. Such methods cannot adequately leverage the structure of logical forms in the case examples. We propose StructCBR, a structured case-based reasoning approach, which leverages subtree-level similarity between logical forms of cases and candidate outputs, resulting in better decoder decisions. For the task of adapting Text-to-SQL models to unseen schemas, we show that exploiting case examples in a structured manner via StructCBR offers consistent performance improvements over prior inference-time adaptation methods across five different databases. To the best of our knowledge, we are the first to attempt inference-time adaptation of Text-to-SQL models, and harness trainable structured similarity between subqueries.
Diverse Parallel Data Synthesis for Cross-Database Adaptation of Text-to-SQL Parsers
Oct 29, 2022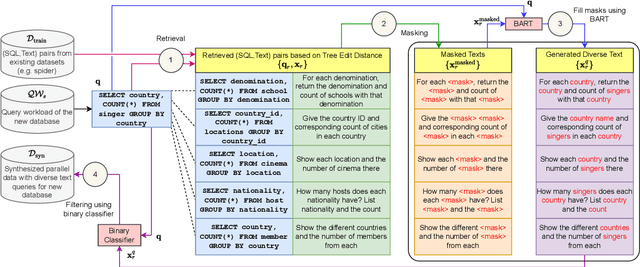
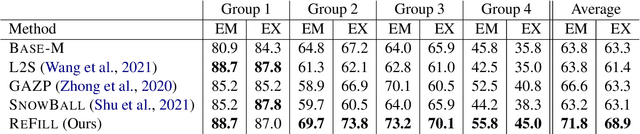
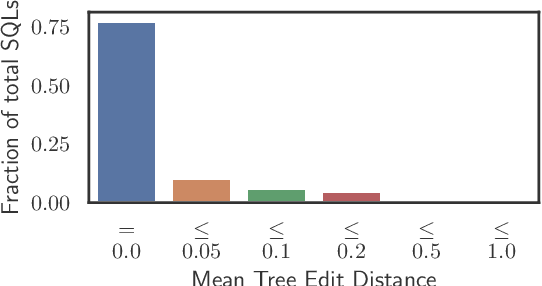
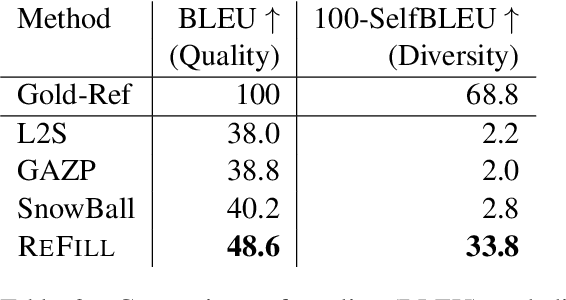
Text-to-SQL parsers typically struggle with databases unseen during the train time. Adapting parsers to new databases is a challenging problem due to the lack of natural language queries in the new schemas. We present ReFill, a framework for synthesizing high-quality and textually diverse parallel datasets for adapting a Text-to-SQL parser to a target schema. ReFill learns to retrieve-and-edit text queries from the existing schemas and transfers them to the target schema. We show that retrieving diverse existing text, masking their schema-specific tokens, and refilling with tokens relevant to the target schema, leads to significantly more diverse text queries than achievable by standard SQL-to-Text generation methods. Through experiments spanning multiple databases, we demonstrate that fine-tuning parsers on datasets synthesized using ReFill consistently outperforms the prior data-augmentation methods.
Bootstrapping Multilingual Semantic Parsers using Large Language Models
Oct 13, 2022
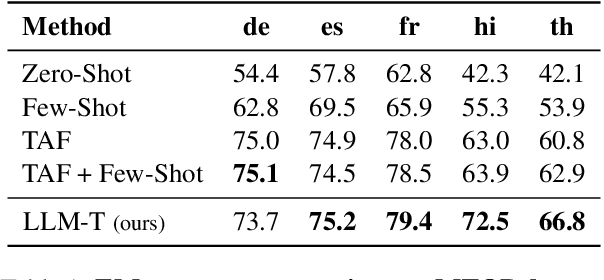

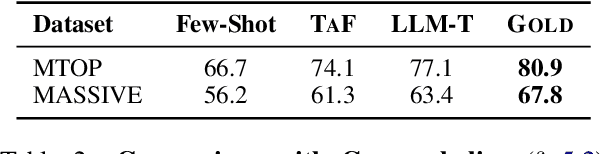
Despite cross-lingual generalization demonstrated by pre-trained multilingual models, the translate-train paradigm of transferring English datasets across multiple languages remains to be the key ingredient for training task-specific multilingual models. However, for many low-resource languages, the availability of a reliable translation service entails significant amounts of costly human-annotated translation pairs. Further, the translation services for low-resource languages may continue to be brittle due to domain mismatch between the task-specific input text and the general-purpose text used while training the translation models. We consider the task of multilingual semantic parsing and demonstrate the effectiveness and flexibility offered by large language models (LLMs) for translating English datasets into several languages via few-shot prompting. We provide (i) Extensive comparisons with prior translate-train methods across 50 languages demonstrating that LLMs can serve as highly effective data translators, outperforming prior translation based methods on 40 out of 50 languages; (ii) A comprehensive study of the key design choices that enable effective data translation via prompted LLMs.
Exploiting Language Relatedness for Low Web-Resource Language Model Adaptation: An Indic Languages Study
Jun 09, 2021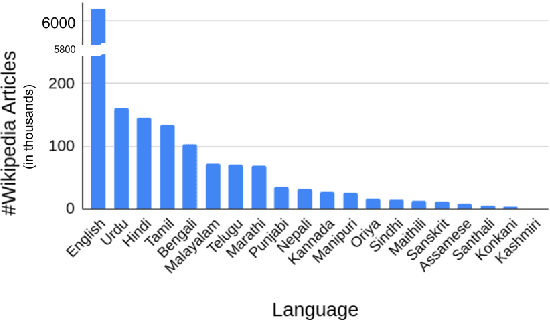
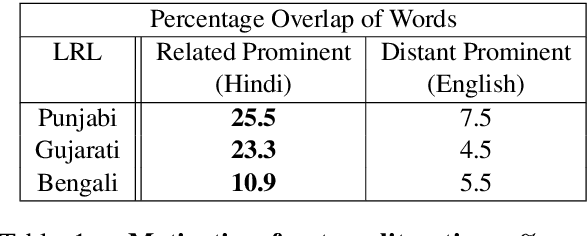
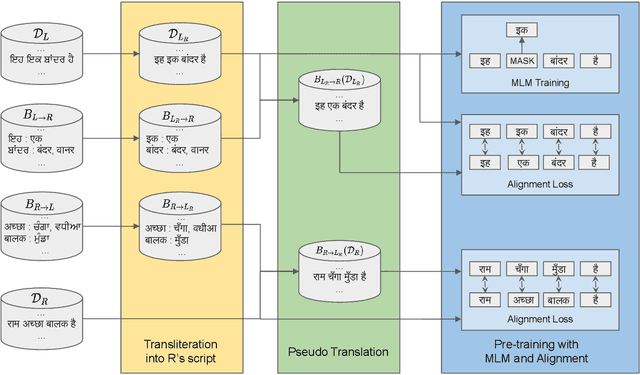
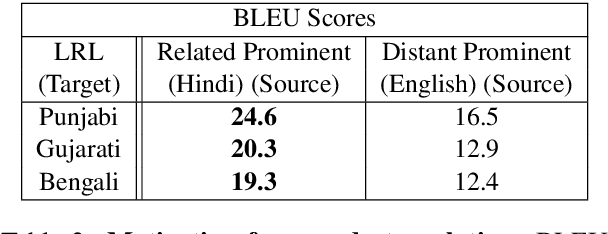
Recent research in multilingual language models (LM) has demonstrated their ability to effectively handle multiple languages in a single model. This holds promise for low web-resource languages (LRL) as multilingual models can enable transfer of supervision from high resource languages to LRLs. However, incorporating a new language in an LM still remains a challenge, particularly for languages with limited corpora and in unseen scripts. In this paper we argue that relatedness among languages in a language family may be exploited to overcome some of the corpora limitations of LRLs, and propose RelateLM. We focus on Indian languages, and exploit relatedness along two dimensions: (1) script (since many Indic scripts originated from the Brahmic script), and (2) sentence structure. RelateLM uses transliteration to convert the unseen script of limited LRL text into the script of a Related Prominent Language (RPL) (Hindi in our case). While exploiting similar sentence structures, RelateLM utilizes readily available bilingual dictionaries to pseudo translate RPL text into LRL corpora. Experiments on multiple real-world benchmark datasets provide validation to our hypothesis that using a related language as pivot, along with transliteration and pseudo translation based data augmentation, can be an effective way to adapt LMs for LRLs, rather than direct training or pivoting through English.
Teaching keyword spotters to spot new keywords with limited examples
Jun 04, 2021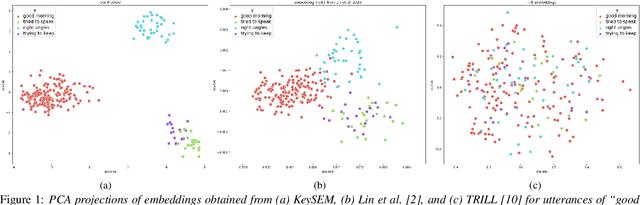
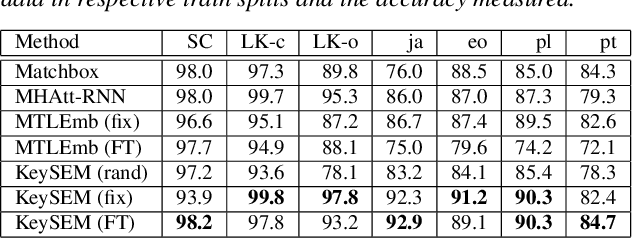
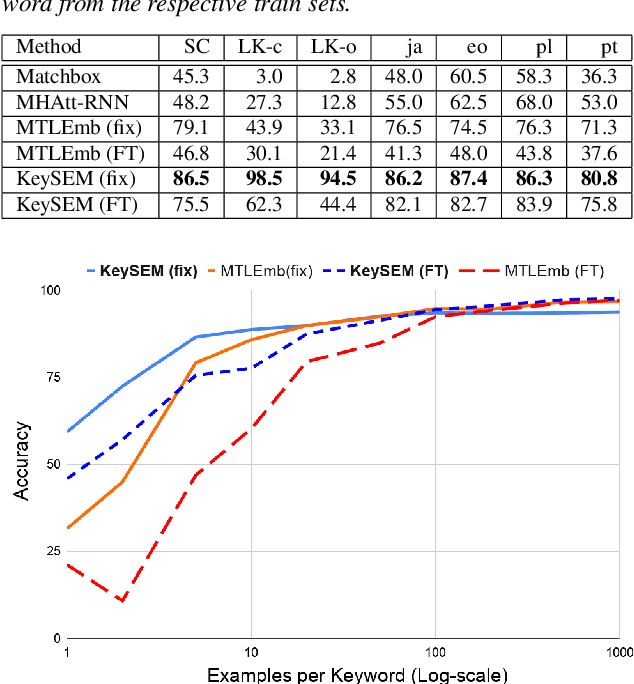
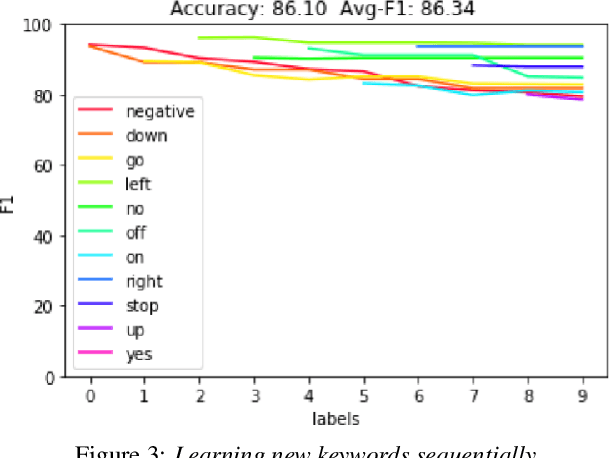
Learning to recognize new keywords with just a few examples is essential for personalizing keyword spotting (KWS) models to a user's choice of keywords. However, modern KWS models are typically trained on large datasets and restricted to a small vocabulary of keywords, limiting their transferability to a broad range of unseen keywords. Towards easily customizable KWS models, we present KeySEM (Keyword Speech EMbedding), a speech embedding model pre-trained on the task of recognizing a large number of keywords. Speech representations offered by KeySEM are highly effective for learning new keywords from a limited number of examples. Comparisons with a diverse range of related work across several datasets show that our method achieves consistently superior performance with fewer training examples. Although KeySEM was pre-trained only on English utterances, the performance gains also extend to datasets from four other languages indicating that KeySEM learns useful representations well aligned with the task of keyword spotting. Finally, we demonstrate KeySEM's ability to learn new keywords sequentially without requiring to re-train on previously learned keywords. Our experimental observations suggest that KeySEM is well suited to on-device environments where post-deployment learning and ease of customization are often desirable.
Error-driven Fixed-Budget ASR Personalization for Accented Speakers
Mar 04, 2021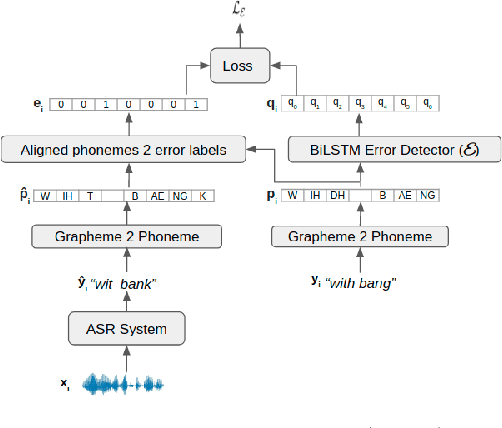
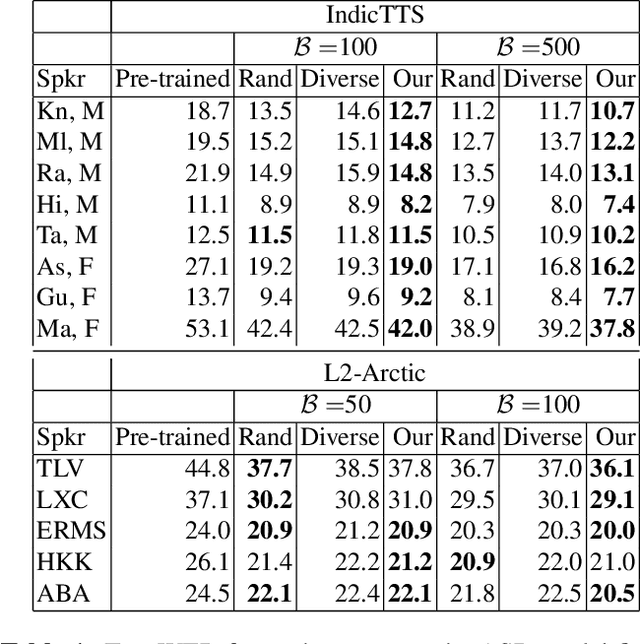


We consider the task of personalizing ASR models while being constrained by a fixed budget on recording speaker-specific utterances. Given a speaker and an ASR model, we propose a method of identifying sentences for which the speaker's utterances are likely to be harder for the given ASR model to recognize. We assume a tiny amount of speaker-specific data to learn phoneme-level error models which help us select such sentences. We show that speaker's utterances on the sentences selected using our error model indeed have larger error rates when compared to speaker's utterances on randomly selected sentences. We find that fine-tuning the ASR model on the sentence utterances selected with the help of error models yield higher WER improvements in comparison to fine-tuning on an equal number of randomly selected sentence utterances. Thus, our method provides an efficient way of collecting speaker utterances under budget constraints for personalizing ASR models.