 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Parallel Data Synthesis for Cross-Database Adaptation of Text-to-SQL Parsers
Paper and Code
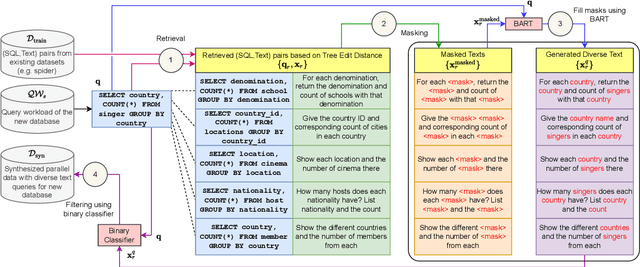
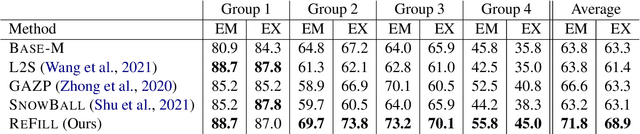
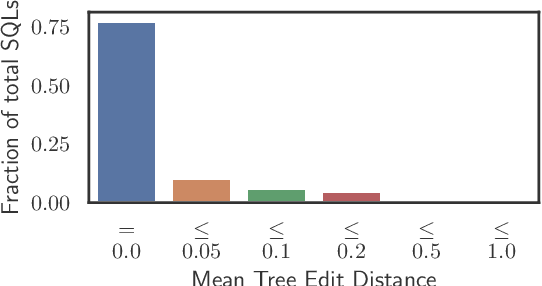
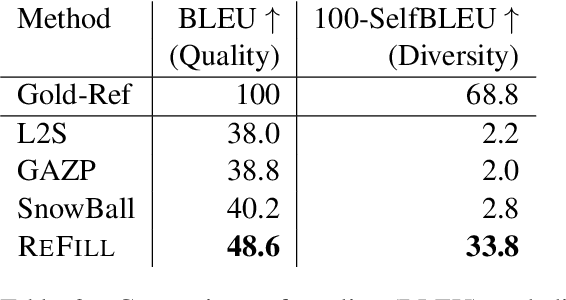
Text-to-SQL parsers typically struggle with databases unseen during the train time. Adapting parsers to new databases is a challenging problem due to the lack of natural language queries in the new schemas. We present ReFill, a framework for synthesizing high-quality and textually diverse parallel datasets for adapting a Text-to-SQL parser to a target schema. ReFill learns to retrieve-and-edit text queries from the existing schemas and transfers them to the target schema. We show that retrieving diverse existing text, masking their schema-specific tokens, and refilling with tokens relevant to the target schema, leads to significantly more diverse text queries than achievable by standard SQL-to-Text generation methods. Through experiments spanning multiple databases, we demonstrate that fine-tuning parsers on datasets synthesized using ReFill consistently outperforms the prior data-augmentation methods.