 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
Black-box Adaptation of ASR for Accented Speech
Jun 24, 2020
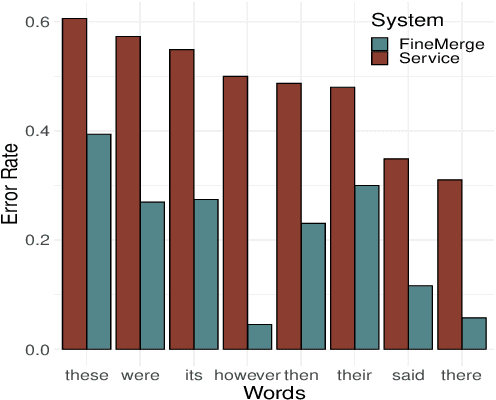


We introduce the problem of adapting a black-box, cloud-based ASR system to speech from a target accent. While leading online ASR services obtain impressive performance on main-stream accents, they perform poorly on sub-populations - we observed that the word error rate (WER) achieved by Google's ASR API on Indian accents is almost twice the WER on US accents. Existing adaptation methods either require access to model parameters or overlay an error-correcting module on output transcripts. We highlight the need for correlating outputs with the original speech to fix accent errors. Accordingly, we propose a novel coupling of an open-source accent-tuned local model with the black-box service where the output from the service guides frame-level inference in the local model. Our fine-grained merging algorithm is better at fixing accent errors than existing word-level combination strategies. Experiments on Indian and Australian accents with three leading ASR models as service, show that we achieve as much as 28% relative reduction in WER over both the local and service models.
O-MedAL: Online Active Deep Learning for Medical Image Analysis
Aug 28, 2019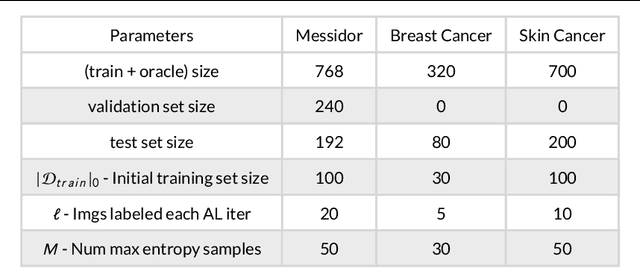
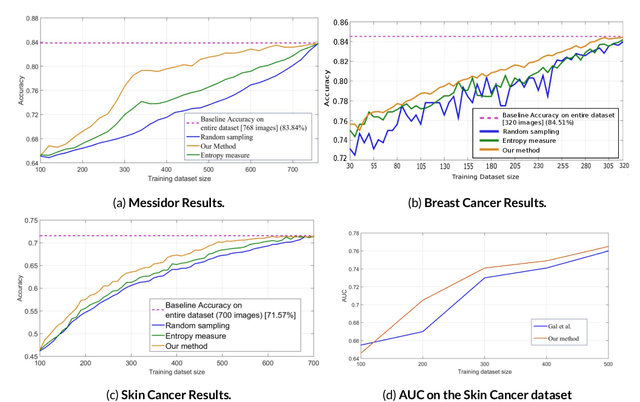
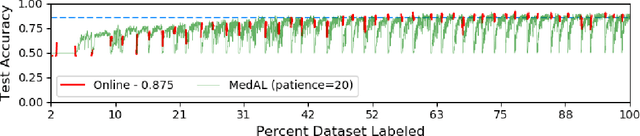
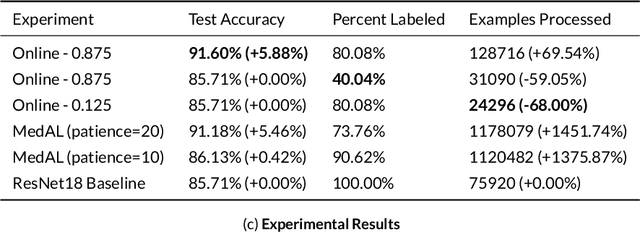
Active Learning methods create an optimized and labeled training set from unlabeled data. We introduce a novel Online Active Deep Learning method for Medical Image Analysis. We extend our MedAL active learning framework to present new results in this paper. Experiments on three medical image datasets show that our novel online active learning model requires significantly less labelings, is more accurate, and is more robust to class imbalances than existing methods. Our method is also more accurate and computationally efficient than the baseline model. Compared to random sampling and uncertainty sampling, the method uses 275 and 200 (out of 768) fewer labeled examples, respectively. For Diabetic Retinopathy detection, our method attains a 5.88% accuracy improvement over the baseline model when 80% of the dataset is labeled, and the model reaches baseline accuracy when only 40% is labeled.
MedAL: Deep Active Learning Sampling Method for Medical Image Analysis
Sep 28, 2018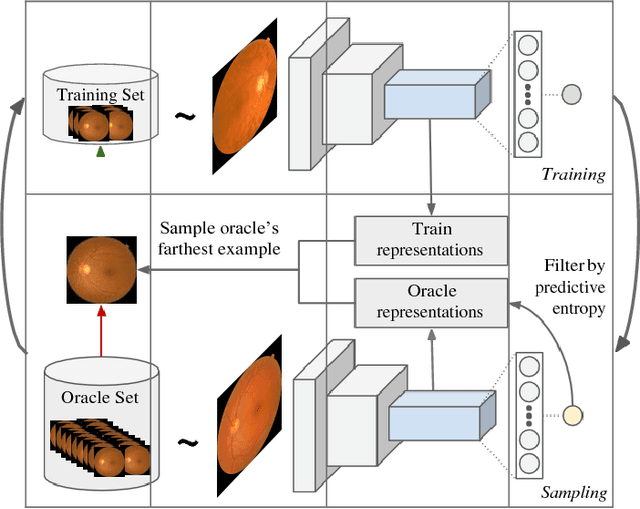
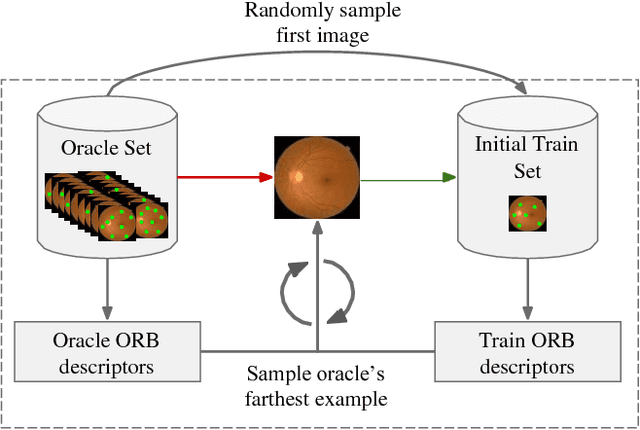
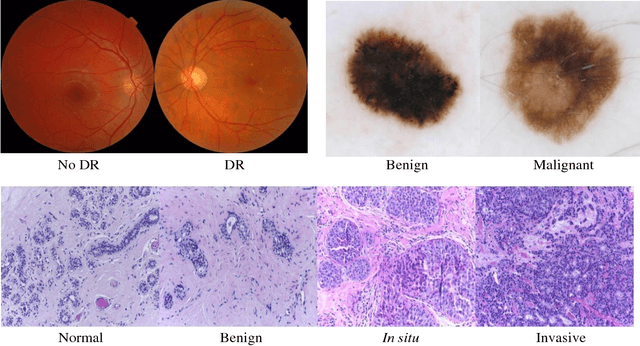
Deep learning models have been successfully used in medical image analysis problems but they require a large amount of labeled images to obtain good performance.Deep learning models have been successfully used in medical image analysis problems but they require a large amount of labeled images to obtain good performance. However, such large labeled datasets are costly to acquire. Active learning techniques can be used to minimize the number of required training labels while maximizing the model's performance.In this work, we propose a novel sampling method that queries the unlabeled examples that maximize the average distance to all training set examples in a learned feature space. We then extend our sampling method to define a better initial training set, without the need for a trained model, by using ORB feature descriptors. We validate MedAL on 3 medical image datasets and show that our method is robust to different dataset properties. MedAL is also efficient, achieving 80% accuracy on the task of Diabetic Retinopathy detection using only 425 labeled images, corresponding to a 32% reduction in the number of required labeled examples compared to the standard uncertainty sampling technique, and a 40% reduction compared to random sampling.