 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChainCQG: Flow-Aware Conversational Question Generation
Feb 04, 2021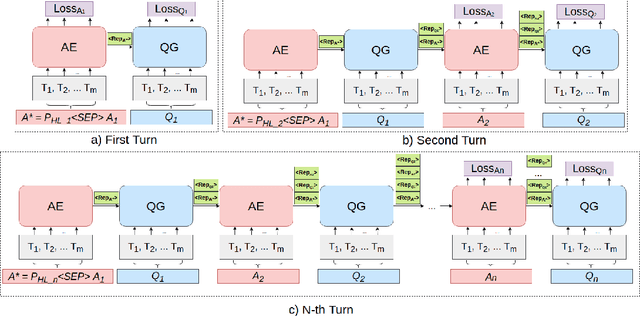
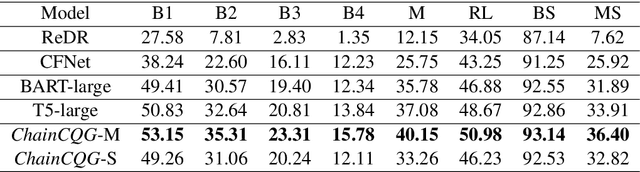

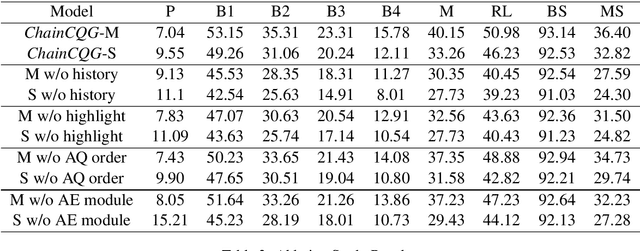
Conversational systems enable numerous valuable applications, and question-answering is an important component underlying many of these. However, conversational question-answering remains challenging due to the lack of realistic, domain-specific training data. Inspired by this bottleneck, we focus on conversational question generation as a means to generate synthetic conversations for training and evaluation purposes. We present a number of novel strategies to improve conversational flow and accommodate varying question types and overall fluidity. Specifically, we design ChainCQG as a two-stage architecture that learns question-answer representations across multiple dialogue turns using a flow propagation training strategy.ChainCQG significantly outperforms both answer-aware and answer-unaware SOTA baselines (e.g., up to 48% BLEU-1 improvement). Additionally, our model is able to generate different types of questions, with improved fluidity and coreference alignment.
O-MedAL: Online Active Deep Learning for Medical Image Analysis
Aug 28, 2019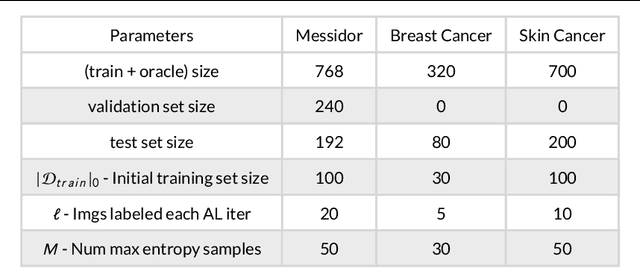
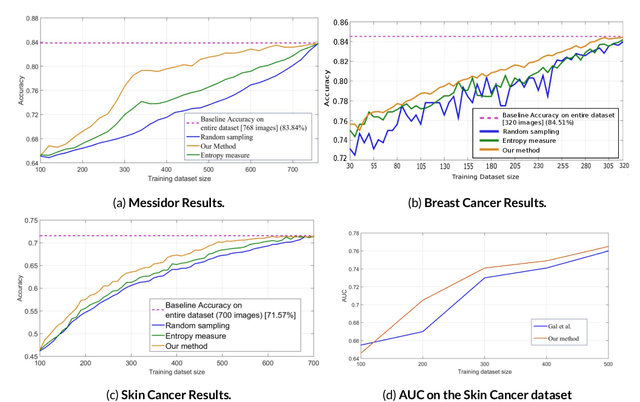
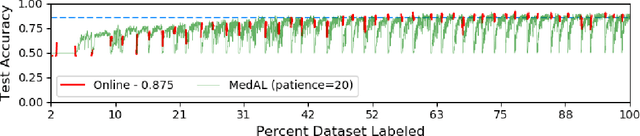
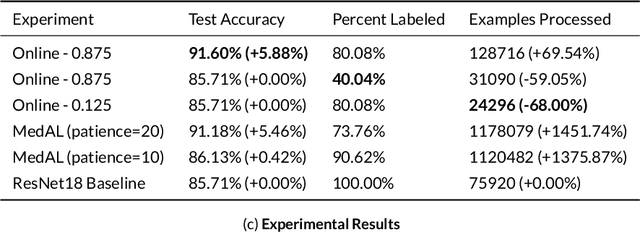
Active Learning methods create an optimized and labeled training set from unlabeled data. We introduce a novel Online Active Deep Learning method for Medical Image Analysis. We extend our MedAL active learning framework to present new results in this paper. Experiments on three medical image datasets show that our novel online active learning model requires significantly less labelings, is more accurate, and is more robust to class imbalances than existing methods. Our method is also more accurate and computationally efficient than the baseline model. Compared to random sampling and uncertainty sampling, the method uses 275 and 200 (out of 768) fewer labeled examples, respectively. For Diabetic Retinopathy detection, our method attains a 5.88% accuracy improvement over the baseline model when 80% of the dataset is labeled, and the model reaches baseline accuracy when only 40% is labeled.
MedAL: Deep Active Learning Sampling Method for Medical Image Analysis
Sep 28, 2018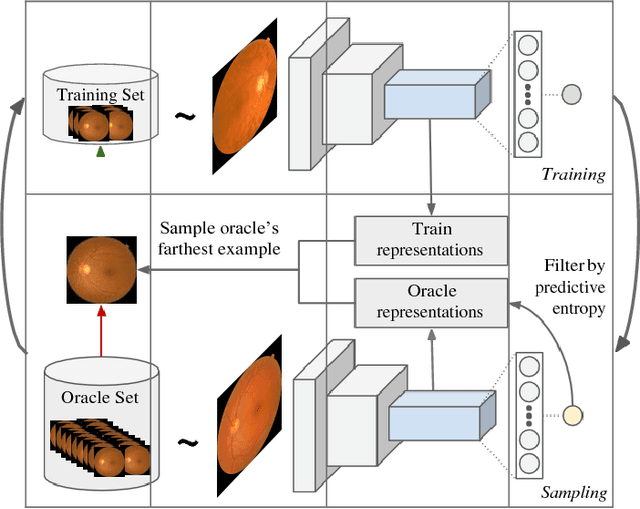
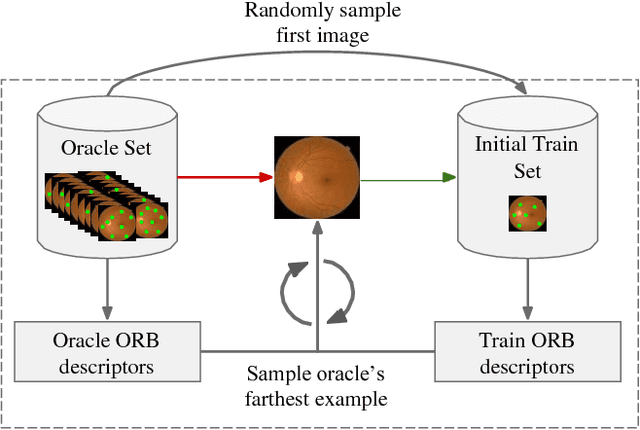
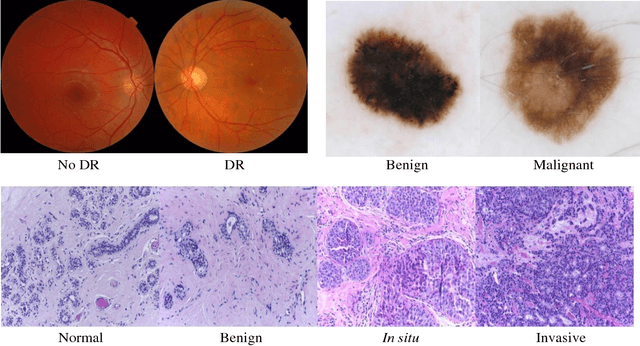
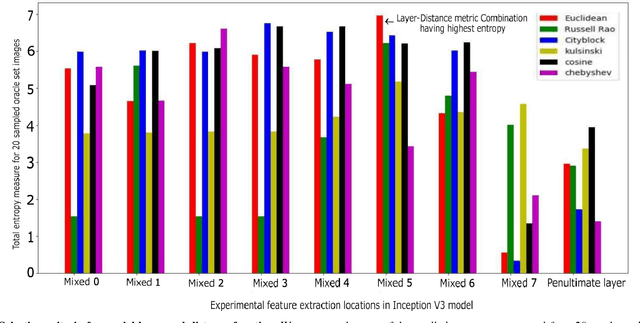
Deep learning models have been successfully used in medical image analysis problems but they require a large amount of labeled images to obtain good performance.Deep learning models have been successfully used in medical image analysis problems but they require a large amount of labeled images to obtain good performance. However, such large labeled datasets are costly to acquire. Active learning techniques can be used to minimize the number of required training labels while maximizing the model's performance.In this work, we propose a novel sampling method that queries the unlabeled examples that maximize the average distance to all training set examples in a learned feature space. We then extend our sampling method to define a better initial training set, without the need for a trained model, by using ORB feature descriptors. We validate MedAL on 3 medical image datasets and show that our method is robust to different dataset properties. MedAL is also efficient, achieving 80% accuracy on the task of Diabetic Retinopathy detection using only 425 labeled images, corresponding to a 32% reduction in the number of required labeled examples compared to the standard uncertainty sampling technique, and a 40% reduction compared to random sampling.