 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dynamic Belief Graphs for Theory-of-mind Reasoning
Mar 20, 2026Theory of Mind (ToM) reasoning with Large Language Models (LLMs) requires inferring how people's implicit, evolving beliefs shape what they seek and how they act under uncertainty -- especially in high-stakes settings such as disaster response, emergency medicine, and human-in-the-loop autonomy. Prior approaches either prompt LLMs directly or use latent-state models that treat beliefs as static and independent, often producing incoherent mental models over time and weak reasoning in dynamic contexts. We introduce a structured cognitive trajectory model for LLM-based ToM that represents mental state as a dynamic belief graph, jointly inferring latent beliefs, learning their time-varying dependencies, and linking belief evolution to information seeking and decisions. Our model contributes (i) a novel projection from textualized probabilistic statements to consistent probabilistic graphical model updates, (ii) an energy-based factor graph representation of belief interdependencies, and (iii) an ELBO-based objective that captures belief accumulation and delayed decisions. Across multiple real-world disaster evacuation datasets, our model significantly improves action prediction and recovers interpretable belief trajectories consistent with human reasoning, providing a principled module for augmenting LLMs with ToM in high-uncertainty environment. https://anonymous.4open.science/r/ICML_submission-6373/
Multi-Task Anti-Causal Learning for Reconstructing Urban Events from Residents' Reports
Mar 12, 2026Many real-world machine learning tasks are anti-causal: they require inferring latent causes from observed effects. In practice, we often face multiple related tasks where part of the forward causal mechanism is invariant across tasks, while other components are task-specific. We propose Multi-Task Anti-Causal learning (MTAC), a framework for estimating causes from outcomes and confounders by explicitly exploiting such cross-task invariances. MTAC first performs causal discovery to learn a shared causal graph and then instantiates a structured multi-task structural equation model (SEM) that factorizes the outcome-generation process into (i) a task-invariant mechanism and (ii) task-specific mechanisms via a shared backbone with task-specific heads. Building on the learned forward model, MTAC performs maximum A posteriori (MAP)based inference to reconstruct causes by jointly optimizing latent mechanism variables and cause magnitudes under the learned causal structure. We evaluate MTAC on the application of urban event reconstruction from resident reports, spanning three tasks:parking violations, abandoned properties, and unsanitary conditions. On real-world data collected from Manhattan and the city of Newark, MTAC consistently improves reconstruction accuracy over strong baselines, achieving up to 34.61\% MAE reduction and demonstrating the benefit of learning transferable causal mechanisms across tasks.
Persona-aware and Explainable Bikeability Assessment: A Vision-Language Model Approach
Jan 07, 2026Bikeability assessment is essential for advancing sustainable urban transportation and creating cyclist-friendly cities, and it requires incorporating users' perceptions of safety and comfort. Yet existing perception-based bikeability assessment approaches face key limitations in capturing the complexity of road environments and adequately accounting for heterogeneity in subjective user perceptions. This paper proposes a persona-aware Vision-Language Model framework for bikeability assessment with three novel contributions: (i) theory-grounded persona conditioning based on established cyclist typology that generates persona-specific explanations via chain-of-thought reasoning; (ii) multi-granularity supervised fine-tuning that combines scarce expert-annotated reasoning with abundant user ratings for joint prediction and explainable assessment; and (iii) AI-enabled data augmentation that creates controlled paired data to isolate infrastructure variable impacts. To test and validate this framework, we developed a panoramic image-based crowdsourcing system and collected 12,400 persona-conditioned assessments from 427 cyclists. Experiment results show that the proposed framework offers competitive bikeability rating prediction while uniquely enabling explainable factor attribution.
QUIDS: Quality-informed Incentive-driven Multi-agent Dispatching System for Mobile Crowdsensing
Dec 18, 2025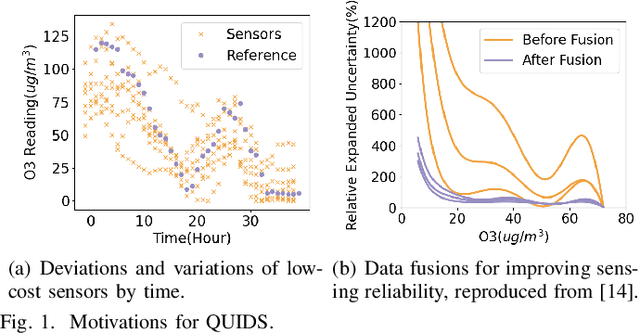
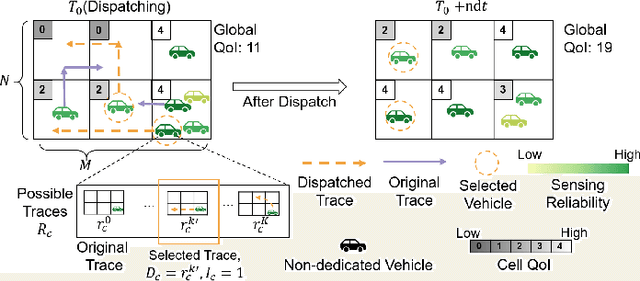
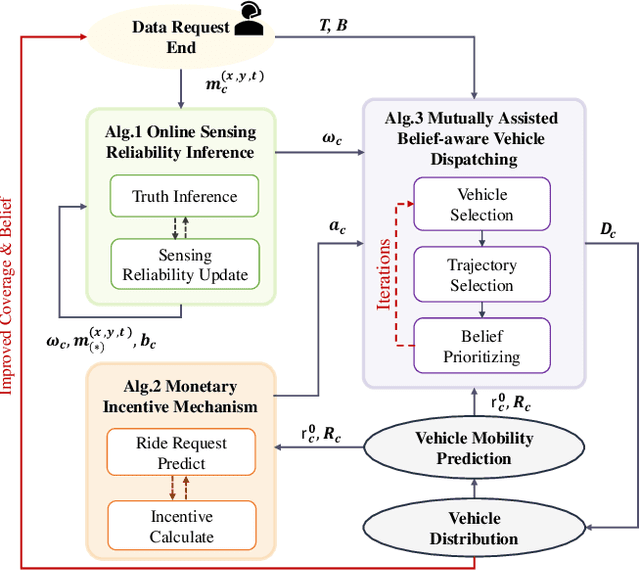

This paper addresses the challenge of achieving optimal Quality of Information (QoI) in non-dedicated vehicular mobile crowdsensing (NVMCS) systems. The key obstacles are the interrelated issues of sensing coverage, sensing reliability, and the dynamic participation of vehicles. To tackle these, we propose QUIDS, a QUality-informed Incentive-driven multi-agent Dispatching System, which ensures high sensing coverage and reliability under budget constraints. QUIDS introduces a novel metric, Aggregated Sensing Quality (ASQ), to quantitatively capture QoI by integrating both coverage and reliability. We also develop a Mutually Assisted Belief-aware Vehicle Dispatching algorithm that estimates sensing reliability and allocates incentives under uncertainty, further improving ASQ. Evaluation using real-world data from a metropolitan NVMCS deployment shows QUIDS improves ASQ by 38% over non-dispatching scenarios and by 10% over state-of-the-art methods. It also reduces reconstruction map errors by 39-74% across algorithms. By jointly optimizing coverage and reliability via a quality-informed incentive mechanism, QUIDS enables low-cost, high-quality urban monitoring without dedicated infrastructure, applicable to smart-city scenarios like traffic and environmental sensing.
Where You Go is Who You Are: Behavioral Theory-Guided LLMs for Inverse Reinforcement Learning
May 22, 2025Big trajectory data hold great promise for human mobility analysis, but their utility is often constrained by the absence of critical traveler attributes, particularly sociodemographic information. While prior studies have explored predicting such attributes from mobility patterns, they often overlooked underlying cognitive mechanisms and exhibited low predictive accuracy. This study introduces SILIC, short for Sociodemographic Inference with LLM-guided Inverse Reinforcement Learning (IRL) and Cognitive Chain Reasoning (CCR), a theoretically grounded framework that leverages LLMs to infer sociodemographic attributes from observed mobility patterns by capturing latent behavioral intentions and reasoning through psychological constructs. Particularly, our approach explicitly follows the Theory of Planned Behavior (TPB), a foundational behavioral framework in transportation research, to model individuals' latent cognitive processes underlying travel decision-making. The LLMs further provide heuristic guidance to improve IRL reward function initialization and update by addressing its ill-posedness and optimization challenges arising from the vast and unstructured reward space. Evaluated in the 2017 Puget Sound Regional Council Household Travel Survey, our method substantially outperforms state-of-the-art baselines and shows great promise for enriching big trajectory data to support more behaviorally grounded applications in transportation planning and beyond.
Multi-resolution Score-Based Variational Graphical Diffusion for Causal Disaster System Modeling and Inference
Apr 05, 2025Complex systems with intricate causal dependencies challenge accurate prediction. Effective modeling requires precise physical process representation, integration of interdependent factors, and incorporation of multi-resolution observational data. These systems manifest in both static scenarios with instantaneous causal chains and temporal scenarios with evolving dynamics, complicating modeling efforts. Current methods struggle to simultaneously handle varying resolutions, capture physical relationships, model causal dependencies, and incorporate temporal dynamics, especially with inconsistently sampled data from diverse sources. We introduce Temporal-SVGDM: Score-based Variational Graphical Diffusion Model for Multi-resolution observations. Our framework constructs individual SDEs for each variable at its native resolution, then couples these SDEs through a causal score mechanism where parent nodes inform child nodes' evolution. This enables unified modeling of both immediate causal effects in static scenarios and evolving dependencies in temporal scenarios. In temporal models, state representations are processed through a sequence prediction model to predict future states based on historical patterns and causal relationships. Experiments on real-world datasets demonstrate improved prediction accuracy and causal understanding compared to existing methods, with robust performance under varying levels of background knowledge. Our model exhibits graceful degradation across different disaster types, successfully handling both static earthquake scenarios and temporal hurricane and wildfire scenarios, while maintaining superior performance even with limited data.
Spatially-Heterogeneous Causal Bayesian Networks for Seismic Multi-Hazard Estimation: A Variational Approach with Gaussian Processes and Normalizing Flows
Apr 05, 2025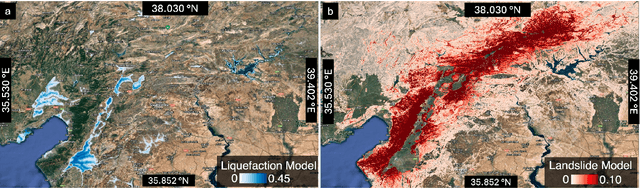



Post-earthquake hazard and impact estimation are critical for effective disaster response, yet current approaches face significant limitations. Traditional models employ fixed parameters regardless of geographical context, misrepresenting how seismic effects vary across diverse landscapes, while remote sensing technologies struggle to distinguish between co-located hazards. We address these challenges with a spatially-aware causal Bayesian network that decouples co-located hazards by modeling their causal relationships with location-specific parameters. Our framework integrates sensing observations, latent variables, and spatial heterogeneity through a novel combination of Gaussian Processes with normalizing flows, enabling us to capture how same earthquake produces different effects across varied geological and topographical features. Evaluations across three earthquakes demonstrate Spatial-VCBN achieves Area Under the Curve (AUC) improvements of up to 35.2% over existing methods. These results highlight the critical importance of modeling spatial heterogeneity in causal mechanisms for accurate disaster assessment, with direct implications for improving emergency response resource allocation.
Multi-class Seismic Building Damage Assessment from InSAR Imagery using Quadratic Variational Causal Bayesian Inference
Feb 25, 2025

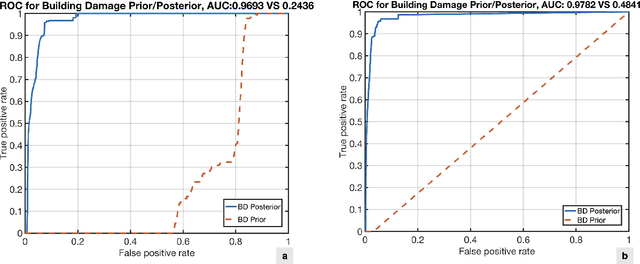
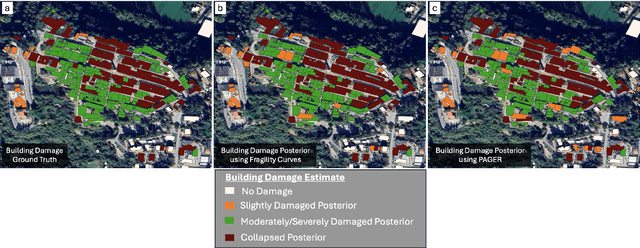
Interferometric Synthetic Aperture Radar (InSAR) technology uses satellite radar to detect surface deformation patterns and monitor earthquake impacts on buildings. While vital for emergency response planning, extracting multi-class building damage classifications from InSAR data faces challenges: overlapping damage signatures with environmental noise, computational complexity in multi-class scenarios, and the need for rapid regional-scale processing. Our novel multi-class variational causal Bayesian inference framework with quadratic variational bounds provides rigorous approximations while ensuring efficiency. By integrating InSAR observations with USGS ground failure models and building fragility functions, our approach separates building damage signals while maintaining computational efficiency through strategic pruning. Evaluation across five major earthquakes (Haiti 2021, Puerto Rico 2020, Zagreb 2020, Italy 2016, Ridgecrest 2019) shows improved damage classification accuracy (AUC: 0.94-0.96), achieving up to 35.7% improvement over existing methods. Our approach maintains high accuracy (AUC > 0.93) across all damage categories while reducing computational overhead by over 40% without requiring extensive ground truth data.
From Perceptions to Decisions: Wildfire Evacuation Decision Prediction with Behavioral Theory-informed LLMs
Feb 24, 2025Evacuation decision prediction is critical for efficient and effective wildfire response by helping emergency management anticipate traffic congestion and bottlenecks, allocate resources, and minimize negative impacts. Traditional statistical methods for evacuation decision prediction fail to capture the complex and diverse behavioral logic of different individuals. In this work, for the first time, we introduce FLARE, short for facilitating LLM for advanced reasoning on wildfire evacuation decision prediction, a Large Language Model (LLM)-based framework that integrates behavioral theories and models to streamline the Chain-of-Thought (CoT) reasoning and subsequently integrate with memory-based Reinforcement Learning (RL) module to provide accurate evacuation decision prediction and understanding. Our proposed method addresses the limitations of using existing LLMs for evacuation behavioral predictions, such as limited survey data, mismatching with behavioral theory, conflicting individual preferences, implicit and complex mental states, and intractable mental state-behavior mapping. Experiments on three post-wildfire survey datasets show an average of 20.47% performance improvement over traditional theory-informed behavioral models, with strong cross-event generalizability. Our complete code is publicly available at https://github.com/SusuXu-s-Lab/FLARE
Spatial-variant causal Bayesian inference for rapid seismic ground failures and impacts estimation
Nov 18, 2024Rapid and accurate estimation of post-earthquake ground failures and building damage is critical for effective post-disaster responses. Progression in remote sensing technologies has paved the way for rapid acquisition of detailed, localized data, enabling swift hazard estimation through analysis of correlation deviations between pre- and post-quake satellite imagery. However, discerning seismic hazards and their impacts is challenged by overlapping satellite signals from ground failures, building damage, and environmental noise. Previous advancements introduced a novel causal graph-based Bayesian network that continually refines seismic ground failure and building damage estimates derived from satellite imagery, accounting for the intricate interplay among geospatial elements, seismic activity, ground failures, building structures, damages, and satellite data. However, this model's neglect of spatial heterogeneity across different locations in a seismic region limits its precision in capturing the spatial diversity of seismic effects. In this study, we pioneer an approach that accounts for spatial intricacies by introducing a spatial variable influenced by the bilateral filter to capture relationships from surrounding hazards. The bilateral filter considers both spatial proximity of neighboring hazards and their ground shaking intensity values, ensuring refined modeling of spatial relationships. This integration achieves a balance between site-specific characteristics and spatial tendencies, offering a comprehensive representation of the post-disaster landscape. Our model, tested across multiple earthquake events, demonstrates significant improvements in capturing spatial heterogeneity in seismic hazard estimation. The results highlight enhanced accuracy and efficiency in post-earthquake large-scale multi-impact estimation, effectively informing rapid disaster responses.
* This paper was accepted for 2024 WCEE conference