 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoDrive: Pareto Evolution for Safety-Critical Autonomous Driving via Self-Improving LLM Agents
Jun 02, 2026Generating safety-critical scenarios is essential for validating and improving autonomous driving systems, yet it inherently requires maximizing adversariality to expose failures while preserving realism. Existing methods usually manage this trade-off with handcrafted heuristics, confining generation to known priors and overlooking underexplored patterns. While recent open-ended agentic evolution can push this limit, unconstrained general agents lack strict simulator grounding and tend to collapse the multi-objective tension into single-scalar maximization. Here we present EvoDrive, the first automated, LLM-based agentic evolution framework for multi-objective scenario generation. EvoDrive employs a simulator-grounded actor-critic architecture where a memory-driven actor iteratively proposes improvements to the generators and critics filter out implausible candidates, and a self-evolving world evaluator routes promising proposals to optimize simulation budgets. EvoDrive further maintains a Pareto archive of evaluated candidates to preserve diverse attack-realism trade-offs and guide future evolution via simulation feedback. Benchmark results on MetaDrive and CARLA show that EvoDrive not only significantly expands the Pareto frontier across various generators, but also produces valuable scenarios for policy training.
MobEvolve: An Agentic Self-Evolving Heuristic System for Interpretable Human Mobility Generation
Jun 01, 2026Human mobility generation aims to synthesize realistic trip chains for target populations based on individual features. Existing paradigms, including deep generative models, LLM-based methods, and traditional heuristics, struggle to satisfy the complex demands of this task while simultaneously maintaining interpretability, behavioral plausibility, population-level distributional alignment, and inference efficiency. To bridge this gap, we introduce MobEvolve, the first agentic self-evolving heuristic framework for human mobility generation. MobEvolve initializes a behavior-inspired heuristic system and employs an LLM agent to iteratively evolve its internal logic. By diagnosing empirical misalignments and failure cases on a validation set, the agent proposes targeted updates and accumulates evolution memory for cumulative self-improvement. Extensive evaluations on the Singapore and Montreal benchmarks demonstrate that MobEvolve significantly outperforms state-of-the-art deep generative and LLM-based methods in individual trajectory fidelity, population-level distribution alignment, and behavioral plausibility, while preserving interpretability and high inference efficiency.
Reasoning-preserved Efficient Distillation of Large Language Models via Activation-aware Initialization
May 28, 2026Efficient Distillation (EDistill) compresses large language models (LLMs) by structured pruning parameters and tuning lightweight modules with high training efficiency. Although these EDistilled LLMs achieve state-of-the-art (SOTA) performance on general ability benchmarks relative to similarly sized LLMs, we identify a severe degradation in their multi-step reasoning ability, which we term reasoning collapse. We systematically analyze the geometric origins of reasoning collapse and show that the SOTA EDistill method based on width-reducing projection matrices suffers from eRank collapse, in which the effective rank (eRank) of hidden representations drops. We theoretically explain how singular values of randomly initialized projection matrices become unevenly distributed, leading to eRank collapse and thus token indistinguishability. To address this issue, we propose RED (Reasoning-preserved Efficient Distillation) for LLMs, which introduces activation-aware initialization to initialize projection matrices as channel-selection matrices, thus theoretically mitigating eRank collapse. Experiments on Llama and Qwen series demonstrate that RED substantially recovers reasoning while maintaining high training efficiency and SOTA general ability.
Bridge: Retrieval-Augmented Spatiotemporal Modeling for Urban Delivery Demand
May 18, 2026Forecasting urban delivery demand becomes substantially more challenging when newly added service regions lack historical records. Existing spatiotemporal forecasters effectively model spatial dependence once sufficient node histories are available. Still, they remain parametric and therefore struggle to recover short-term operational dynamics in cold-start regions. Geospatial embeddings help identify where a region is and what function it serves, yet they do not directly reveal how a similar region behaves under a comparable temporal context. We propose Bridge, a retrieval-augmented spatiotemporal graph framework that combines an inductive contextual graph backbone with a time-aware memory of region-time windows. For each target region, Bridge retrieves future demand patterns from the memory using both regional context and recent dynamics, and refines the backbone forecast through a gated fusion mechanism. To align retrieval with forecasting utility, we further train the retriever with a future-aware objective that favors entries whose future trajectories best match the target. Experiments on four real-world delivery datasets show that Bridge consistently improves over competitive spatiotemporal baselines in both within-city cold-start and cross-city transfer with partial observations. The results show that retrieval augmentation provides a useful operational memory for cold-start urban demand forecasting when parametric graph generalization alone is insufficient.
ADV-0: Closed-Loop Min-Max Adversarial Training for Long-Tail Robustness in Autonomous Driving
Mar 16, 2026Deploying autonomous driving systems requires robustness against long-tail scenarios that are rare but safety-critical. While adversarial training offers a promising solution, existing methods typically decouple scenario generation from policy optimization and rely on heuristic surrogates. This leads to objective misalignment and fails to capture the shifting failure modes of evolving policies. This paper presents ADV-0, a closed-loop min-max optimization framework that treats the interaction between driving policy (defender) and adversarial agent (attacker) as a zero-sum Markov game. By aligning the attacker's utility directly with the defender's objective, we reveal the optimal adversary distribution. To make this tractable, we cast dynamic adversary evolution as iterative preference learning, efficiently approximating this optimum and offering an algorithm-agnostic solution to the game. Theoretically, ADV-0 converges to a Nash Equilibrium and maximizes a certified lower bound on real-world performance. Experiments indicate that it effectively exposes diverse safety-critical failures and greatly enhances the generalizability of both learned policies and motion planners against unseen long-tail risks.
Solving Oversmoothing in GNNs via Nonlocal Message Passing: Algebraic Smoothing and Depth Scalability
Dec 10, 2025



The relationship between Layer Normalization (LN) placement and the oversmoothing phenomenon remains underexplored. We identify a critical dilemma: Pre-LN architectures avoid oversmoothing but suffer from the curse of depth, while Post-LN architectures bypass the curse of depth but experience oversmoothing. To resolve this, we propose a new method based on Post-LN that induces algebraic smoothing, preventing oversmoothing without the curse of depth. Empirical results across five benchmarks demonstrate that our approach supports deeper networks (up to 256 layers) and improves performance, requiring no additional parameters. Key contributions: Theoretical Characterization: Analysis of LN dynamics and their impact on oversmoothing and the curse of depth. A Principled Solution: A parameter-efficient method that induces algebraic smoothing and avoids oversmoothing and the curse of depth. Empirical Validation: Extensive experiments showing the effectiveness of the method in deeper GNNs.
Preventing Dimensional Collapse in Self-Supervised Learning via Orthogonality Regularization
Nov 01, 2024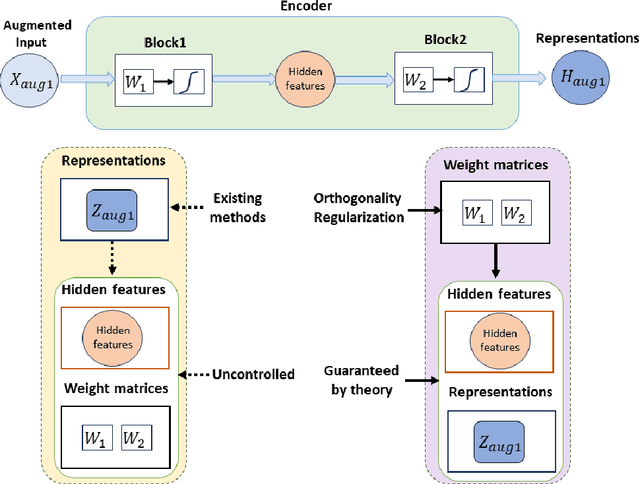

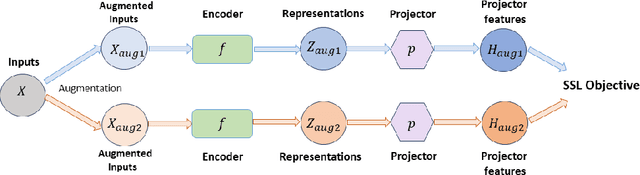
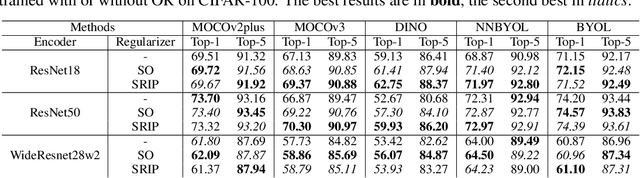
Self-supervised learning (SSL) has rapidly advanced in recent years, approaching the performance of its supervised counterparts through the extraction of representations from unlabeled data. However, dimensional collapse, where a few large eigenvalues dominate the eigenspace, poses a significant obstacle for SSL. When dimensional collapse occurs on features (e.g. hidden features and representations), it prevents features from representing the full information of the data; when dimensional collapse occurs on weight matrices, their filters are self-related and redundant, limiting their expressive power. Existing studies have predominantly concentrated on the dimensional collapse of representations, neglecting whether this can sufficiently prevent the dimensional collapse of the weight matrices and hidden features. To this end, we first time propose a mitigation approach employing orthogonal regularization (OR) across the encoder, targeting both convolutional and linear layers during pretraining. OR promotes orthogonality within weight matrices, thus safeguarding against the dimensional collapse of weight matrices, hidden features, and representations. Our empirical investigations demonstrate that OR significantly enhances the performance of SSL methods across diverse benchmarks, yielding consistent gains with both CNNs and Transformer-based architectures.
Preventing Model Collapse in Deep Canonical Correlation Analysis by Noise Regularization
Nov 01, 2024



Multi-View Representation Learning (MVRL) aims to learn a unified representation of an object from multi-view data. Deep Canonical Correlation Analysis (DCCA) and its variants share simple formulations and demonstrate state-of-the-art performance. However, with extensive experiments, we observe the issue of model collapse, {\em i.e.}, the performance of DCCA-based methods will drop drastically when training proceeds. The model collapse issue could significantly hinder the wide adoption of DCCA-based methods because it is challenging to decide when to early stop. To this end, we develop NR-DCCA, which is equipped with a novel noise regularization approach to prevent model collapse. Theoretical analysis shows that the Correlation Invariant Property is the key to preventing model collapse, and our noise regularization forces the neural network to possess such a property. A framework to construct synthetic data with different common and complementary information is also developed to compare MVRL methods comprehensively. The developed NR-DCCA outperforms baselines stably and consistently in both synthetic and real-world datasets, and the proposed noise regularization approach can also be generalized to other DCCA-based methods such as DGCCA.
Joint Estimation and Prediction of City-wide Delivery Demand: A Large Language Model Empowered Graph-based Learning Approach
Aug 30, 2024



The proliferation of e-commerce and urbanization has significantly intensified delivery operations in urban areas, boosting the volume and complexity of delivery demand. Data-driven predictive methods, especially those utilizing machine learning techniques, have emerged to handle these complexities in urban delivery demand management problems. One particularly pressing problem that has not yet been sufficiently studied is the joint estimation and prediction of city-wide delivery demand. To this end, we formulate this problem as a graph-based spatiotemporal learning task. First, a message-passing neural network model is formalized to capture the interaction between demand patterns of associated regions. Second, by exploiting recent advances in large language models, we extract general geospatial knowledge encodings from the unstructured locational data and integrate them into the demand predictor. Last, to encourage the cross-city transferability of the model, an inductive training scheme is developed in an end-to-end routine. Extensive empirical results on two real-world delivery datasets, including eight cities in China and the US, demonstrate that our model significantly outperforms state-of-the-art baselines in these challenging tasks.
Geolocation Representation from Large Language Models are Generic Enhancers for Spatio-Temporal Learning
Aug 22, 2024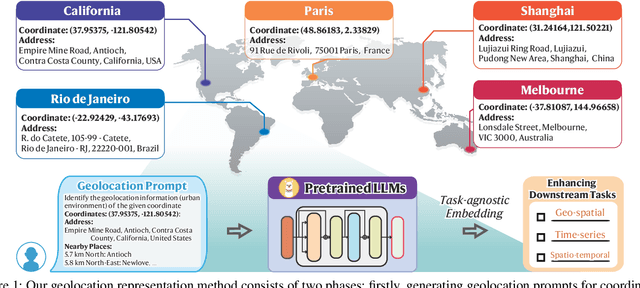



In the geospatial domain, universal representation models are significantly less prevalent than their extensive use in natural language processing and computer vision. This discrepancy arises primarily from the high costs associated with the input of existing representation models, which often require street views and mobility data. To address this, we develop a novel, training-free method that leverages large language models (LLMs) and auxiliary map data from OpenStreetMap to derive geolocation representations (LLMGeovec). LLMGeovec can represent the geographic semantics of city, country, and global scales, which acts as a generic enhancer for spatio-temporal learning. Specifically, by direct feature concatenation, we introduce a simple yet effective paradigm for enhancing multiple spatio-temporal tasks including geographic prediction (GP), long-term time series forecasting (LTSF), and graph-based spatio-temporal forecasting (GSTF). LLMGeovec can seamlessly integrate into a wide spectrum of spatio-temporal learning models, providing immediate enhancements. Experimental results demonstrate that LLMGeovec achieves global coverage and significantly boosts the performance of leading GP, LTSF, and GSTF models.