 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Attacks to Curricula: Learnability-Guided Adversarial Training for Safe Autonomous Driving
Jun 12, 2026Closed-loop adversarial training improves autonomous driving safety by exposing policies to rare safety-critical scenarios. Standard pipelines first generate adversarial scenarios and then sample them for policy optimization. However, most existing frameworks remain attack-oriented: collision-driven generators often synthesize unsolvable extreme situations, which can degrade learning, while heuristic samplers ignore the evolving capability of the driving policy, causing sample inefficiency and delayed convergence. We propose AlignADV, a learnability-guided closed-loop adversarial training framework that converts adversarial scenarios into resolvable and capability-aligned curricula. First, we reformulate adversarial scenario generation as a preference alignment problem and employ direct preference optimization to guide the generator toward critical yet resolvable scenarios. Second, we introduce behavioral fingerprints to capture the intrinsic characteristics of the evolving policy and construct a multi-modal capability prediction model that estimates policy performance without expensive closed-loop simulations. By combining resolvability-aligned scenarios with capability predictions, AlignADV develops a dynamic curriculum sampling mechanism that prioritizes scenarios targeting the current policy's vulnerabilities. Experiments on the Waymo Open Motion Dataset demonstrate that AlignADV improves convergence efficiency and final performance, reducing training steps by up to 40.6 percent compared with baseline methods while lowering collision rate and improving route completion under both normal and adversarial traffic conditions. These results highlight a shift from attack-oriented scenario generation to learnability-guided policy improvement, offering a principled direction for safer and more efficient autonomous driving training. Project page: https://meiyuewen.github.io/AlignADV/.
EvoDrive: Pareto Evolution for Safety-Critical Autonomous Driving via Self-Improving LLM Agents
Jun 02, 2026Generating safety-critical scenarios is essential for validating and improving autonomous driving systems, yet it inherently requires maximizing adversariality to expose failures while preserving realism. Existing methods usually manage this trade-off with handcrafted heuristics, confining generation to known priors and overlooking underexplored patterns. While recent open-ended agentic evolution can push this limit, unconstrained general agents lack strict simulator grounding and tend to collapse the multi-objective tension into single-scalar maximization. Here we present EvoDrive, the first automated, LLM-based agentic evolution framework for multi-objective scenario generation. EvoDrive employs a simulator-grounded actor-critic architecture where a memory-driven actor iteratively proposes improvements to the generators and critics filter out implausible candidates, and a self-evolving world evaluator routes promising proposals to optimize simulation budgets. EvoDrive further maintains a Pareto archive of evaluated candidates to preserve diverse attack-realism trade-offs and guide future evolution via simulation feedback. Benchmark results on MetaDrive and CARLA show that EvoDrive not only significantly expands the Pareto frontier across various generators, but also produces valuable scenarios for policy training.
MobEvolve: An Agentic Self-Evolving Heuristic System for Interpretable Human Mobility Generation
Jun 01, 2026Human mobility generation aims to synthesize realistic trip chains for target populations based on individual features. Existing paradigms, including deep generative models, LLM-based methods, and traditional heuristics, struggle to satisfy the complex demands of this task while simultaneously maintaining interpretability, behavioral plausibility, population-level distributional alignment, and inference efficiency. To bridge this gap, we introduce MobEvolve, the first agentic self-evolving heuristic framework for human mobility generation. MobEvolve initializes a behavior-inspired heuristic system and employs an LLM agent to iteratively evolve its internal logic. By diagnosing empirical misalignments and failure cases on a validation set, the agent proposes targeted updates and accumulates evolution memory for cumulative self-improvement. Extensive evaluations on the Singapore and Montreal benchmarks demonstrate that MobEvolve significantly outperforms state-of-the-art deep generative and LLM-based methods in individual trajectory fidelity, population-level distribution alignment, and behavioral plausibility, while preserving interpretability and high inference efficiency.
Reasoning-preserved Efficient Distillation of Large Language Models via Activation-aware Initialization
May 28, 2026Efficient Distillation (EDistill) compresses large language models (LLMs) by structured pruning parameters and tuning lightweight modules with high training efficiency. Although these EDistilled LLMs achieve state-of-the-art (SOTA) performance on general ability benchmarks relative to similarly sized LLMs, we identify a severe degradation in their multi-step reasoning ability, which we term reasoning collapse. We systematically analyze the geometric origins of reasoning collapse and show that the SOTA EDistill method based on width-reducing projection matrices suffers from eRank collapse, in which the effective rank (eRank) of hidden representations drops. We theoretically explain how singular values of randomly initialized projection matrices become unevenly distributed, leading to eRank collapse and thus token indistinguishability. To address this issue, we propose RED (Reasoning-preserved Efficient Distillation) for LLMs, which introduces activation-aware initialization to initialize projection matrices as channel-selection matrices, thus theoretically mitigating eRank collapse. Experiments on Llama and Qwen series demonstrate that RED substantially recovers reasoning while maintaining high training efficiency and SOTA general ability.
Bridge: Retrieval-Augmented Spatiotemporal Modeling for Urban Delivery Demand
May 18, 2026Forecasting urban delivery demand becomes substantially more challenging when newly added service regions lack historical records. Existing spatiotemporal forecasters effectively model spatial dependence once sufficient node histories are available. Still, they remain parametric and therefore struggle to recover short-term operational dynamics in cold-start regions. Geospatial embeddings help identify where a region is and what function it serves, yet they do not directly reveal how a similar region behaves under a comparable temporal context. We propose Bridge, a retrieval-augmented spatiotemporal graph framework that combines an inductive contextual graph backbone with a time-aware memory of region-time windows. For each target region, Bridge retrieves future demand patterns from the memory using both regional context and recent dynamics, and refines the backbone forecast through a gated fusion mechanism. To align retrieval with forecasting utility, we further train the retriever with a future-aware objective that favors entries whose future trajectories best match the target. Experiments on four real-world delivery datasets show that Bridge consistently improves over competitive spatiotemporal baselines in both within-city cold-start and cross-city transfer with partial observations. The results show that retrieval augmentation provides a useful operational memory for cold-start urban demand forecasting when parametric graph generalization alone is insufficient.
ADV-0: Closed-Loop Min-Max Adversarial Training for Long-Tail Robustness in Autonomous Driving
Mar 16, 2026Deploying autonomous driving systems requires robustness against long-tail scenarios that are rare but safety-critical. While adversarial training offers a promising solution, existing methods typically decouple scenario generation from policy optimization and rely on heuristic surrogates. This leads to objective misalignment and fails to capture the shifting failure modes of evolving policies. This paper presents ADV-0, a closed-loop min-max optimization framework that treats the interaction between driving policy (defender) and adversarial agent (attacker) as a zero-sum Markov game. By aligning the attacker's utility directly with the defender's objective, we reveal the optimal adversary distribution. To make this tractable, we cast dynamic adversary evolution as iterative preference learning, efficiently approximating this optimum and offering an algorithm-agnostic solution to the game. Theoretically, ADV-0 converges to a Nash Equilibrium and maximizes a certified lower bound on real-world performance. Experiments indicate that it effectively exposes diverse safety-critical failures and greatly enhances the generalizability of both learned policies and motion planners against unseen long-tail risks.
Seeking to Collide: Online Safety-Critical Scenario Generation for Autonomous Driving with Retrieval Augmented Large Language Models
May 02, 2025Simulation-based testing is crucial for validating autonomous vehicles (AVs), yet existing scenario generation methods either overfit to common driving patterns or operate in an offline, non-interactive manner that fails to expose rare, safety-critical corner cases. In this paper, we introduce an online, retrieval-augmented large language model (LLM) framework for generating safety-critical driving scenarios. Our method first employs an LLM-based behavior analyzer to infer the most dangerous intent of the background vehicle from the observed state, then queries additional LLM agents to synthesize feasible adversarial trajectories. To mitigate catastrophic forgetting and accelerate adaptation, we augment the framework with a dynamic memorization and retrieval bank of intent-planner pairs, automatically expanding its behavioral library when novel intents arise. Evaluations using the Waymo Open Motion Dataset demonstrate that our model reduces the mean minimum time-to-collision from 1.62 to 1.08 s and incurs a 75% collision rate, substantially outperforming baselines.
Exploring the Roles of Large Language Models in Reshaping Transportation Systems: A Survey, Framework, and Roadmap
Mar 27, 2025Modern transportation systems face pressing challenges due to increasing demand, dynamic environments, and heterogeneous information integration. The rapid evolution of Large Language Models (LLMs) offers transformative potential to address these challenges. Extensive knowledge and high-level capabilities derived from pretraining evolve the default role of LLMs as text generators to become versatile, knowledge-driven task solvers for intelligent transportation systems. This survey first presents LLM4TR, a novel conceptual framework that systematically categorizes the roles of LLMs in transportation into four synergetic dimensions: information processors, knowledge encoders, component generators, and decision facilitators. Through a unified taxonomy, we systematically elucidate how LLMs bridge fragmented data pipelines, enhance predictive analytics, simulate human-like reasoning, and enable closed-loop interactions across sensing, learning, modeling, and managing tasks in transportation systems. For each role, our review spans diverse applications, from traffic prediction and autonomous driving to safety analytics and urban mobility optimization, highlighting how emergent capabilities of LLMs such as in-context learning and step-by-step reasoning can enhance the operation and management of transportation systems. We further curate practical guidance, including available resources and computational guidelines, to support real-world deployment. By identifying challenges in existing LLM-based solutions, this survey charts a roadmap for advancing LLM-driven transportation research, positioning LLMs as central actors in the next generation of cyber-physical-social mobility ecosystems. Online resources can be found in the project page: https://github.com/tongnie/awesome-llm4tr.
LLM-attacker: Enhancing Closed-loop Adversarial Scenario Generation for Autonomous Driving with Large Language Models
Jan 27, 2025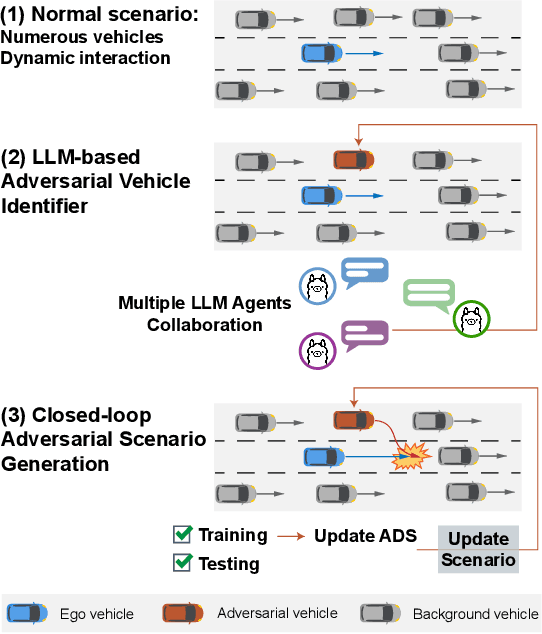
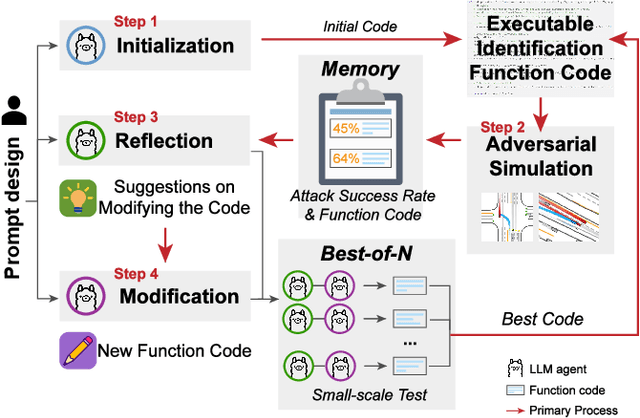

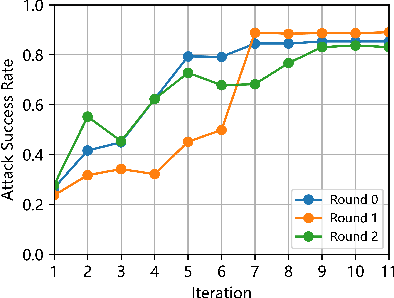
Ensuring and improving the safety of autonomous driving systems (ADS) is crucial for the deployment of highly automated vehicles, especially in safety-critical events. To address the rarity issue, adversarial scenario generation methods are developed, in which behaviors of traffic participants are manipulated to induce safety-critical events. However, existing methods still face two limitations. First, identification of the adversarial participant directly impacts the effectiveness of the generation. However, the complexity of real-world scenarios, with numerous participants and diverse behaviors, makes identification challenging. Second, the potential of generated safety-critical scenarios to continuously improve ADS performance remains underexplored. To address these issues, we propose LLM-attacker: a closed-loop adversarial scenario generation framework leveraging large language models (LLMs). Specifically, multiple LLM agents are designed and coordinated to identify optimal attackers. Then, the trajectories of the attackers are optimized to generate adversarial scenarios. These scenarios are iteratively refined based on the performance of ADS, forming a feedback loop to improve ADS. Experimental results show that LLM-attacker can create more dangerous scenarios than other methods, and the ADS trained with it achieves a collision rate half that of training with normal scenarios. This indicates the ability of LLM-attacker to test and enhance the safety and robustness of ADS. Video demonstrations are provided at: https://drive.google.com/file/d/1Zv4V3iG7825oyiKbUwS2Y-rR0DQIE1ZA/view.
Collaborative Imputation of Urban Time Series through Cross-city Meta-learning
Jan 20, 2025



Urban time series, such as mobility flows, energy consumption, and pollution records, encapsulate complex urban dynamics and structures. However, data collection in each city is impeded by technical challenges such as budget limitations and sensor failures, necessitating effective data imputation techniques that can enhance data quality and reliability. Existing imputation models, categorized into learning-based and analytics-based paradigms, grapple with the trade-off between capacity and generalizability. Collaborative learning to reconstruct data across multiple cities holds the promise of breaking this trade-off. Nevertheless, urban data's inherent irregularity and heterogeneity issues exacerbate challenges of knowledge sharing and collaboration across cities. To address these limitations, we propose a novel collaborative imputation paradigm leveraging meta-learned implicit neural representations (INRs). INRs offer a continuous mapping from domain coordinates to target values, integrating the strengths of both paradigms. By imposing embedding theory, we first employ continuous parameterization to handle irregularity and reconstruct the dynamical system. We then introduce a cross-city collaborative learning scheme through model-agnostic meta learning, incorporating hierarchical modulation and normalization techniques to accommodate multiscale representations and reduce variance in response to heterogeneity. Extensive experiments on a diverse urban dataset from 20 global cities demonstrate our model's superior imputation performance and generalizability, underscoring the effectiveness of collaborative imputation in resource-constrained settings.