 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoDrive: Pareto Evolution for Safety-Critical Autonomous Driving via Self-Improving LLM Agents
Jun 02, 2026Generating safety-critical scenarios is essential for validating and improving autonomous driving systems, yet it inherently requires maximizing adversariality to expose failures while preserving realism. Existing methods usually manage this trade-off with handcrafted heuristics, confining generation to known priors and overlooking underexplored patterns. While recent open-ended agentic evolution can push this limit, unconstrained general agents lack strict simulator grounding and tend to collapse the multi-objective tension into single-scalar maximization. Here we present EvoDrive, the first automated, LLM-based agentic evolution framework for multi-objective scenario generation. EvoDrive employs a simulator-grounded actor-critic architecture where a memory-driven actor iteratively proposes improvements to the generators and critics filter out implausible candidates, and a self-evolving world evaluator routes promising proposals to optimize simulation budgets. EvoDrive further maintains a Pareto archive of evaluated candidates to preserve diverse attack-realism trade-offs and guide future evolution via simulation feedback. Benchmark results on MetaDrive and CARLA show that EvoDrive not only significantly expands the Pareto frontier across various generators, but also produces valuable scenarios for policy training.
ADV-0: Closed-Loop Min-Max Adversarial Training for Long-Tail Robustness in Autonomous Driving
Mar 16, 2026Deploying autonomous driving systems requires robustness against long-tail scenarios that are rare but safety-critical. While adversarial training offers a promising solution, existing methods typically decouple scenario generation from policy optimization and rely on heuristic surrogates. This leads to objective misalignment and fails to capture the shifting failure modes of evolving policies. This paper presents ADV-0, a closed-loop min-max optimization framework that treats the interaction between driving policy (defender) and adversarial agent (attacker) as a zero-sum Markov game. By aligning the attacker's utility directly with the defender's objective, we reveal the optimal adversary distribution. To make this tractable, we cast dynamic adversary evolution as iterative preference learning, efficiently approximating this optimum and offering an algorithm-agnostic solution to the game. Theoretically, ADV-0 converges to a Nash Equilibrium and maximizes a certified lower bound on real-world performance. Experiments indicate that it effectively exposes diverse safety-critical failures and greatly enhances the generalizability of both learned policies and motion planners against unseen long-tail risks.
Seeking to Collide: Online Safety-Critical Scenario Generation for Autonomous Driving with Retrieval Augmented Large Language Models
May 02, 2025Simulation-based testing is crucial for validating autonomous vehicles (AVs), yet existing scenario generation methods either overfit to common driving patterns or operate in an offline, non-interactive manner that fails to expose rare, safety-critical corner cases. In this paper, we introduce an online, retrieval-augmented large language model (LLM) framework for generating safety-critical driving scenarios. Our method first employs an LLM-based behavior analyzer to infer the most dangerous intent of the background vehicle from the observed state, then queries additional LLM agents to synthesize feasible adversarial trajectories. To mitigate catastrophic forgetting and accelerate adaptation, we augment the framework with a dynamic memorization and retrieval bank of intent-planner pairs, automatically expanding its behavioral library when novel intents arise. Evaluations using the Waymo Open Motion Dataset demonstrate that our model reduces the mean minimum time-to-collision from 1.62 to 1.08 s and incurs a 75% collision rate, substantially outperforming baselines.
LLM-attacker: Enhancing Closed-loop Adversarial Scenario Generation for Autonomous Driving with Large Language Models
Jan 27, 2025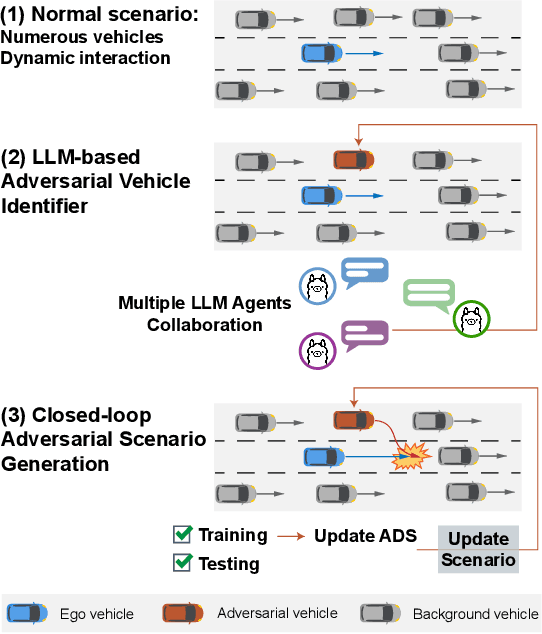
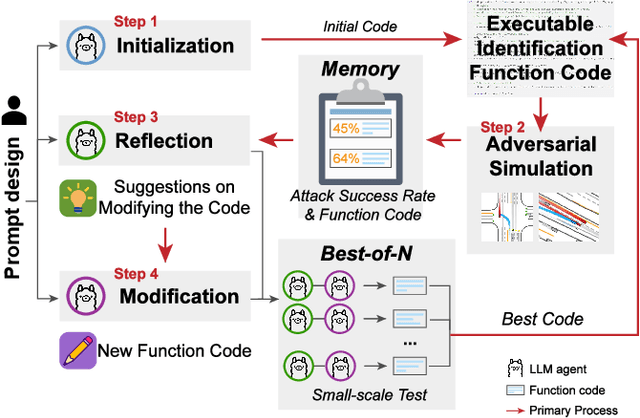

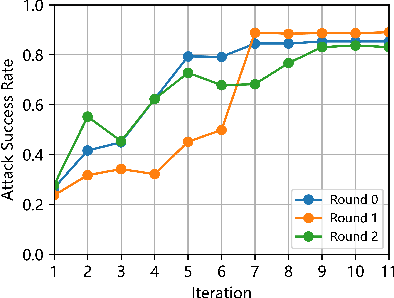
Ensuring and improving the safety of autonomous driving systems (ADS) is crucial for the deployment of highly automated vehicles, especially in safety-critical events. To address the rarity issue, adversarial scenario generation methods are developed, in which behaviors of traffic participants are manipulated to induce safety-critical events. However, existing methods still face two limitations. First, identification of the adversarial participant directly impacts the effectiveness of the generation. However, the complexity of real-world scenarios, with numerous participants and diverse behaviors, makes identification challenging. Second, the potential of generated safety-critical scenarios to continuously improve ADS performance remains underexplored. To address these issues, we propose LLM-attacker: a closed-loop adversarial scenario generation framework leveraging large language models (LLMs). Specifically, multiple LLM agents are designed and coordinated to identify optimal attackers. Then, the trajectories of the attackers are optimized to generate adversarial scenarios. These scenarios are iteratively refined based on the performance of ADS, forming a feedback loop to improve ADS. Experimental results show that LLM-attacker can create more dangerous scenarios than other methods, and the ADS trained with it achieves a collision rate half that of training with normal scenarios. This indicates the ability of LLM-attacker to test and enhance the safety and robustness of ADS. Video demonstrations are provided at: https://drive.google.com/file/d/1Zv4V3iG7825oyiKbUwS2Y-rR0DQIE1ZA/view.
Joint Estimation and Prediction of City-wide Delivery Demand: A Large Language Model Empowered Graph-based Learning Approach
Aug 30, 2024



The proliferation of e-commerce and urbanization has significantly intensified delivery operations in urban areas, boosting the volume and complexity of delivery demand. Data-driven predictive methods, especially those utilizing machine learning techniques, have emerged to handle these complexities in urban delivery demand management problems. One particularly pressing problem that has not yet been sufficiently studied is the joint estimation and prediction of city-wide delivery demand. To this end, we formulate this problem as a graph-based spatiotemporal learning task. First, a message-passing neural network model is formalized to capture the interaction between demand patterns of associated regions. Second, by exploiting recent advances in large language models, we extract general geospatial knowledge encodings from the unstructured locational data and integrate them into the demand predictor. Last, to encourage the cross-city transferability of the model, an inductive training scheme is developed in an end-to-end routine. Extensive empirical results on two real-world delivery datasets, including eight cities in China and the US, demonstrate that our model significantly outperforms state-of-the-art baselines in these challenging tasks.
High-Dimensional Fault Tolerance Testing of Highly Automated Vehicles Based on Low-Rank Models
Jul 28, 2024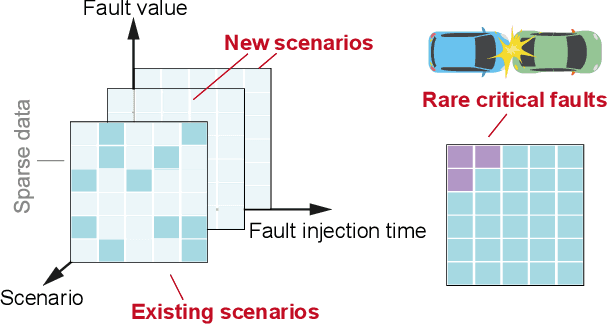
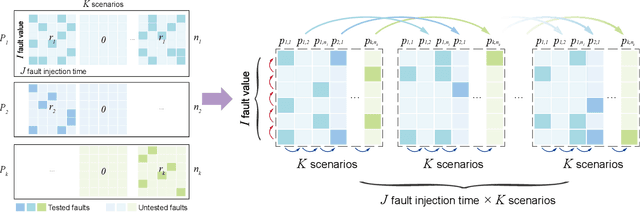
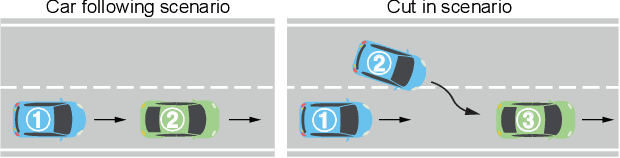
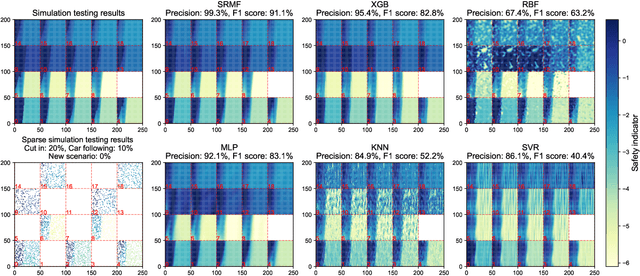
Ensuring fault tolerance of Highly Automated Vehicles (HAVs) is crucial for their safety due to the presence of potentially severe faults. Hence, Fault Injection (FI) testing is conducted by practitioners to evaluate the safety level of HAVs. To fully cover test cases, various driving scenarios and fault settings should be considered. However, due to numerous combinations of test scenarios and fault settings, the testing space can be complex and high-dimensional. In addition, evaluating performance in all newly added scenarios is resource-consuming. The rarity of critical faults that can cause security problems further strengthens the challenge. To address these challenges, we propose to accelerate FI testing under the low-rank Smoothness Regularized Matrix Factorization (SRMF) framework. We first organize the sparse evaluated data into a structured matrix based on its safety values. Then the untested values are estimated by the correlation captured by the matrix structure. To address high dimensionality, a low-rank constraint is imposed on the testing space. To exploit the relationships between existing scenarios and new scenarios and capture the local regularity of critical faults, three types of smoothness regularization are further designed as a complement. We conduct experiments on car following and cut in scenarios. The results indicate that SRMF has the lowest prediction error in various scenarios and is capable of predicting rare critical faults compared to other machine learning models. In addition, SRMF can achieve 1171 acceleration rate, 99.3% precision and 91.1% F1 score in identifying critical faults. To the best of our knowledge, this is the first work to introduce low-rank models to FI testing of HAVs.
Channel-Aware Low-Rank Adaptation in Time Series Forecasting
Jul 24, 2024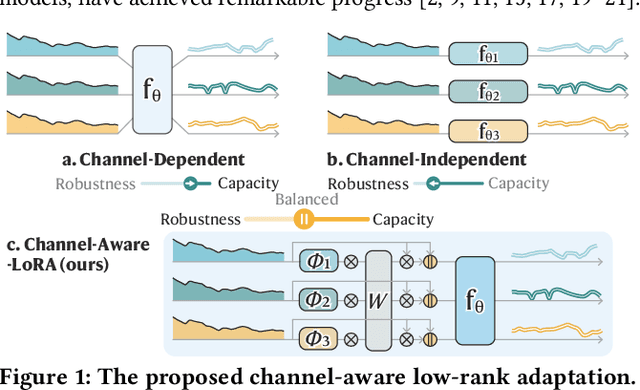

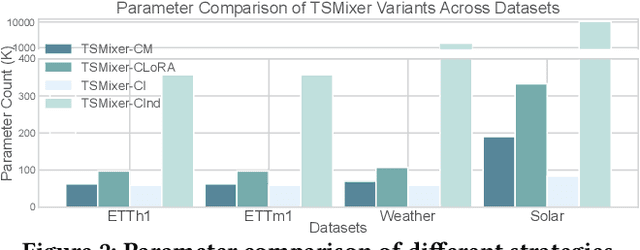
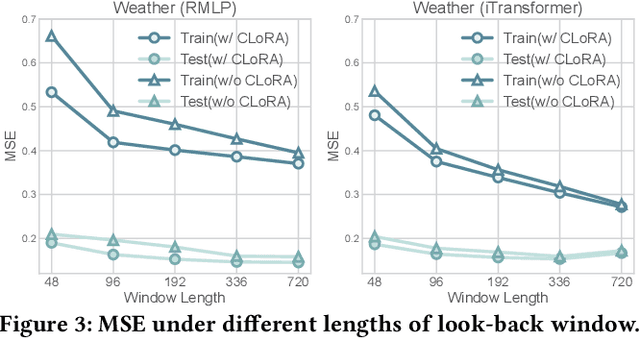
The balance between model capacity and generalization has been a key focus of recent discussions in long-term time series forecasting. Two representative channel strategies are closely associated with model expressivity and robustness, including channel independence (CI) and channel dependence (CD). The former adopts individual channel treatment and has been shown to be more robust to distribution shifts, but lacks sufficient capacity to model meaningful channel interactions. The latter is more expressive for representing complex cross-channel dependencies, but is prone to overfitting. To balance the two strategies, we present a channel-aware low-rank adaptation method to condition CD models on identity-aware individual components. As a plug-in solution, it is adaptable for a wide range of backbone architectures. Extensive experiments show that it can consistently and significantly improve the performance of both CI and CD models with demonstrated efficiency and flexibility. The code is available at https://github.com/tongnie/C-LoRA.
ImputeFormer: Graph Transformers for Generalizable Spatiotemporal Imputation
Dec 04, 2023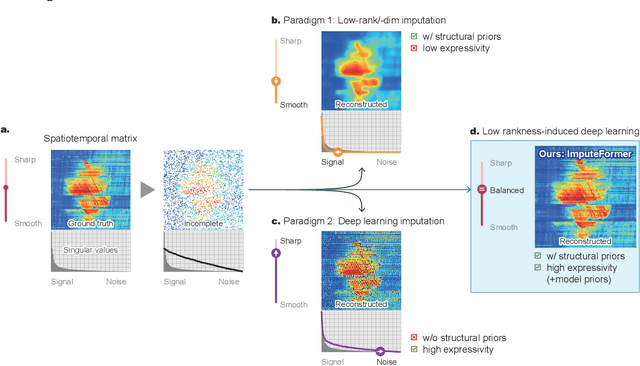
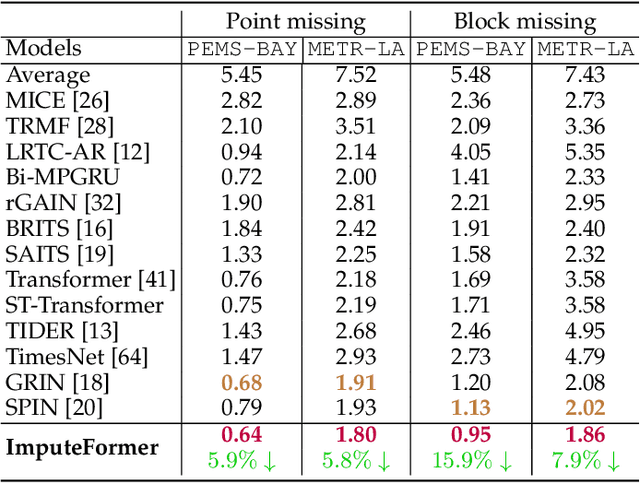
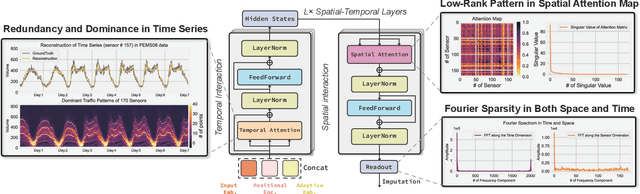
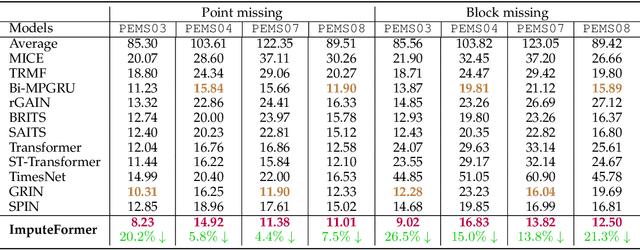
This paper focuses on the multivariate time series imputation problem using deep neural architectures. The ubiquitous issue of missing data in both scientific and engineering tasks necessitates the development of an effective and general imputation model. Leveraging the wisdom and expertise garnered from low-rank imputation methods, we power the canonical Transformers with three key knowledge-driven enhancements, including projected temporal attention, global adaptive graph convolution, and Fourier imputation loss. These task-agnostic inductive biases exploit the inherent structures of incomplete time series, and thus make our model versatile for a variety of imputation problems. We demonstrate its superiority in terms of accuracy, efficiency, and flexibility on heterogeneous datasets, including traffic speed, traffic volume, solar energy, smart metering, and air quality. Comprehensive case studies are performed to further strengthen the interpretability. Promising empirical results provide strong conviction that incorporating time series primitives, such as low-rank properties, can substantially facilitate the development of a generalizable model to approach a wide range of spatiotemporal imputation problems.