 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Sequential to Recursive: Enhancing Decision-Focused Learning with Bidirectional Feedback
Nov 11, 2025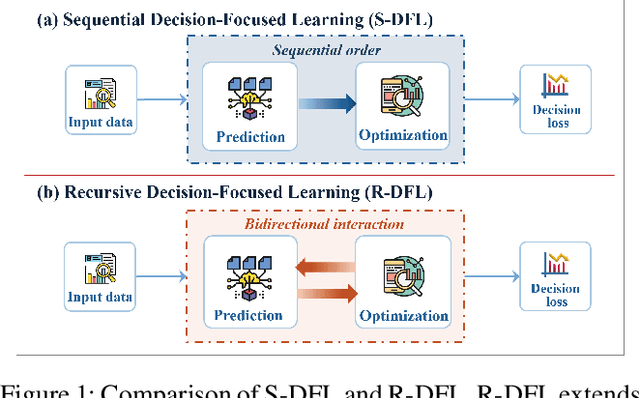
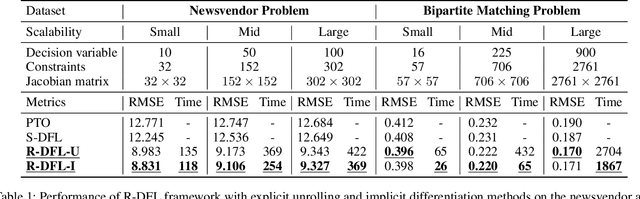
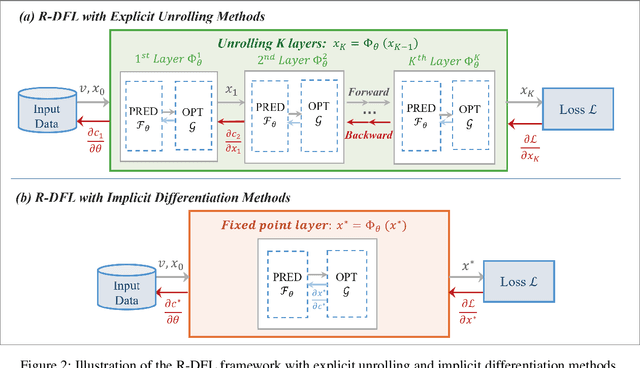
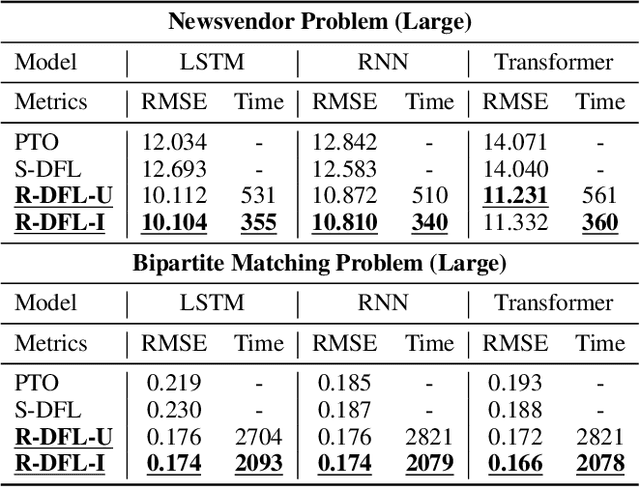
Decision-focused learning (DFL) has emerged as a powerful end-to-end alternative to conventional predict-then-optimize (PTO) pipelines by directly optimizing predictive models through downstream decision losses. Existing DFL frameworks are limited by their strictly sequential structure, referred to as sequential DFL (S-DFL). However, S-DFL fails to capture the bidirectional feedback between prediction and optimization in complex interaction scenarios. In view of this, we first time propose recursive decision-focused learning (R-DFL), a novel framework that introduces bidirectional feedback between downstream optimization and upstream prediction. We further extend two distinct differentiation methods: explicit unrolling via automatic differentiation and implicit differentiation based on fixed-point methods, to facilitate efficient gradient propagation in R-DFL. We rigorously prove that both methods achieve comparable gradient accuracy, with the implicit method offering superior computational efficiency. Extensive experiments on both synthetic and real-world datasets, including the newsvendor problem and the bipartite matching problem, demonstrate that R-DFL not only substantially enhances the final decision quality over sequential baselines but also exhibits robust adaptability across diverse scenarios in closed-loop decision-making problems.
Preventing Dimensional Collapse in Self-Supervised Learning via Orthogonality Regularization
Nov 01, 2024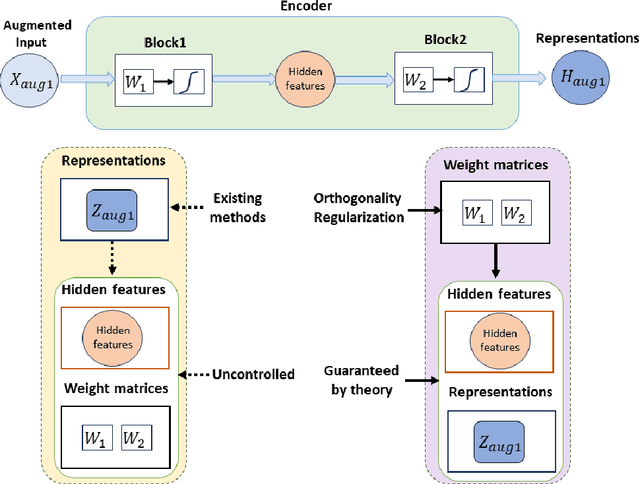

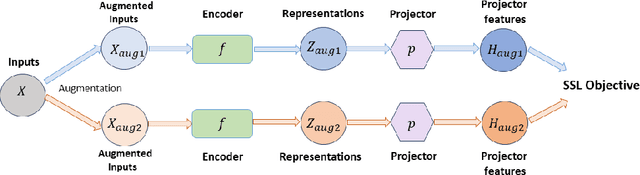
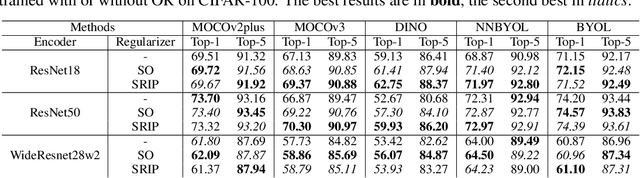
Self-supervised learning (SSL) has rapidly advanced in recent years, approaching the performance of its supervised counterparts through the extraction of representations from unlabeled data. However, dimensional collapse, where a few large eigenvalues dominate the eigenspace, poses a significant obstacle for SSL. When dimensional collapse occurs on features (e.g. hidden features and representations), it prevents features from representing the full information of the data; when dimensional collapse occurs on weight matrices, their filters are self-related and redundant, limiting their expressive power. Existing studies have predominantly concentrated on the dimensional collapse of representations, neglecting whether this can sufficiently prevent the dimensional collapse of the weight matrices and hidden features. To this end, we first time propose a mitigation approach employing orthogonal regularization (OR) across the encoder, targeting both convolutional and linear layers during pretraining. OR promotes orthogonality within weight matrices, thus safeguarding against the dimensional collapse of weight matrices, hidden features, and representations. Our empirical investigations demonstrate that OR significantly enhances the performance of SSL methods across diverse benchmarks, yielding consistent gains with both CNNs and Transformer-based architectures.
Preventing Model Collapse in Deep Canonical Correlation Analysis by Noise Regularization
Nov 01, 2024



Multi-View Representation Learning (MVRL) aims to learn a unified representation of an object from multi-view data. Deep Canonical Correlation Analysis (DCCA) and its variants share simple formulations and demonstrate state-of-the-art performance. However, with extensive experiments, we observe the issue of model collapse, {\em i.e.}, the performance of DCCA-based methods will drop drastically when training proceeds. The model collapse issue could significantly hinder the wide adoption of DCCA-based methods because it is challenging to decide when to early stop. To this end, we develop NR-DCCA, which is equipped with a novel noise regularization approach to prevent model collapse. Theoretical analysis shows that the Correlation Invariant Property is the key to preventing model collapse, and our noise regularization forces the neural network to possess such a property. A framework to construct synthetic data with different common and complementary information is also developed to compare MVRL methods comprehensively. The developed NR-DCCA outperforms baselines stably and consistently in both synthetic and real-world datasets, and the proposed noise regularization approach can also be generalized to other DCCA-based methods such as DGCCA.