 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALFRED: Ask a Large-language model For Reliable ECG Diagnosis
Apr 30, 2025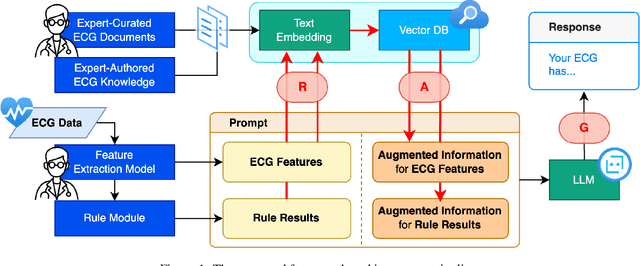

Leveraging Large Language Models (LLMs) with Retrieval-Augmented Generation (RAG) for analyzing medical data, particularly Electrocardiogram (ECG), offers high accuracy and convenience. However, generating reliable, evidence-based results in specialized fields like healthcare remains a challenge, as RAG alone may not suffice. We propose a Zero-shot ECG diagnosis framework based on RAG for ECG analysis that incorporates expert-curated knowledge to enhance diagnostic accuracy and explainability. Evaluation on the PTB-XL dataset demonstrates the framework's effectiveness, highlighting the value of structured domain expertise in automated ECG interpretation. Our framework is designed to support comprehensive ECG analysis, addressing diverse diagnostic needs with potential applications beyond the tested dataset.
RGB-T Tracking Based on Mixed Attention
Apr 18, 2023



RGB-T tracking involves the use of images from both visible and thermal modalities. The primary objective is to adaptively leverage the relatively dominant modality in varying conditions to achieve more robust tracking compared to single-modality tracking. An RGB-T tracker based on mixed attention mechanism to achieve complementary fusion of modalities (referred to as MACFT) is proposed in this paper. In the feature extraction stage, we utilize different transformer backbone branches to extract specific and shared information from different modalities. By performing mixed attention operations in the backbone to enable information interaction and self-enhancement between the template and search images, it constructs a robust feature representation that better understands the high-level semantic features of the target. Then, in the feature fusion stage, a modality-adaptive fusion is achieved through a mixed attention-based modality fusion network, which suppresses the low-quality modality noise while enhancing the information of the dominant modality. Evaluation on multiple RGB-T public datasets demonstrates that our proposed tracker outperforms other RGB-T trackers on general evaluation metrics while also being able to adapt to longterm tracking scenarios.
Automatic Detection of Reactions to Music via Earable Sensing
Apr 06, 2023We present GrooveMeter, a novel system that automatically detects vocal and motion reactions to music via earable sensing and supports music engagement-aware applications. To this end, we use smart earbuds as sensing devices, which are already widely used for music listening, and devise reaction detection techniques by leveraging an inertial measurement unit (IMU) and a microphone on earbuds. To explore reactions in daily music-listening situations, we collect the first kind of dataset, MusicReactionSet, containing 926-minute-long IMU and audio data with 30 participants. With the dataset, we discover a set of unique challenges in detecting music listening reactions accurately and robustly using audio and motion sensing. We devise sophisticated processing pipelines to make reaction detection accurate and efficient. We present a comprehensive evaluation to examine the performance of reaction detection and system cost. It shows that GrooveMeter achieves the macro F1 scores of 0.89 for vocal reaction and 0.81 for motion reaction with leave-one-subject-out cross-validation. More importantly, GrooveMeter shows higher accuracy and robustness compared to alternative methods. We also show that our filtering approach reduces 50% or more of the energy overhead. Finally, we demonstrate the potential use cases through a case study.
HQANN: Efficient and Robust Similarity Search for Hybrid Queries with Structured and Unstructured Constraints
Jul 16, 2022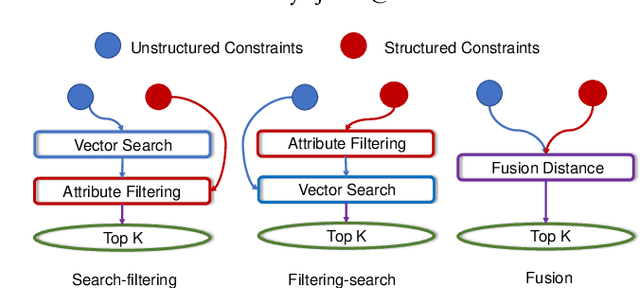
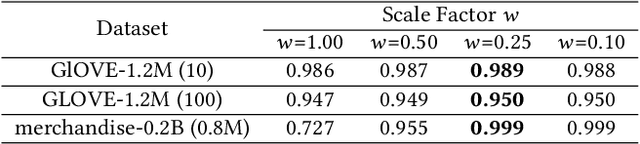
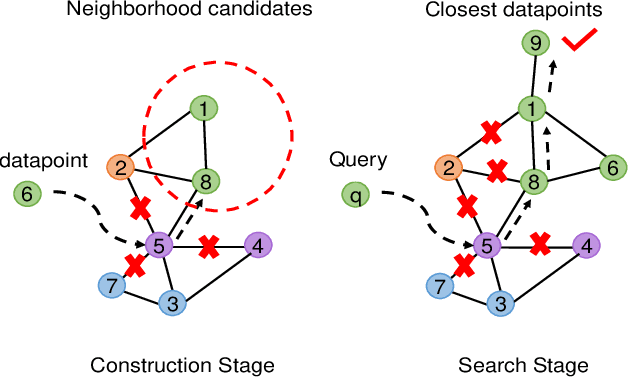

The in-memory approximate nearest neighbor search (ANNS) algorithms have achieved great success for fast high-recall query processing, but are extremely inefficient when handling hybrid queries with unstructured (i.e., feature vectors) and structured (i.e., related attributes) constraints. In this paper, we present HQANN, a simple yet highly efficient hybrid query processing framework which can be easily embedded into existing proximity graph-based ANNS algorithms. We guarantee both low latency and high recall by leveraging navigation sense among attributes and fusing vector similarity search with attribute filtering. Experimental results on both public and in-house datasets demonstrate that HQANN is 10x faster than the state-of-the-art hybrid ANNS solutions to reach the same recall quality and its performance is hardly affected by the complexity of attributes. It can reach 99\% recall@10 in just around 50 microseconds On GLOVE-1.2M with thousands of attribute constraints.
Vocalsound: A Dataset for Improving Human Vocal Sounds Recognition
May 06, 2022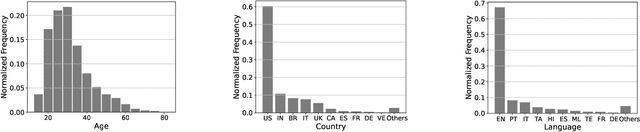
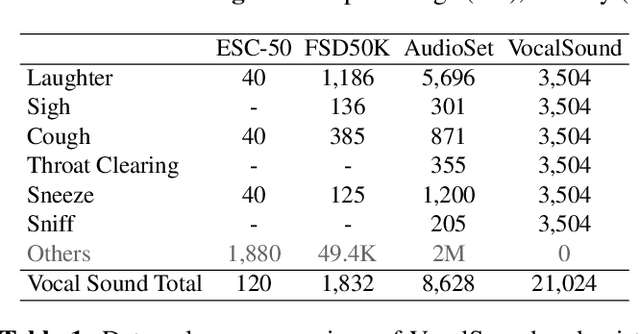
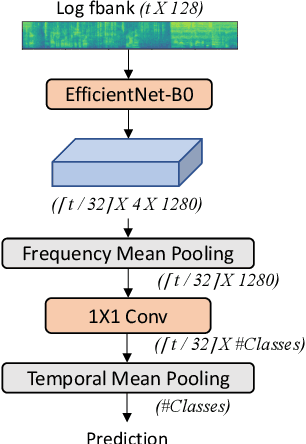
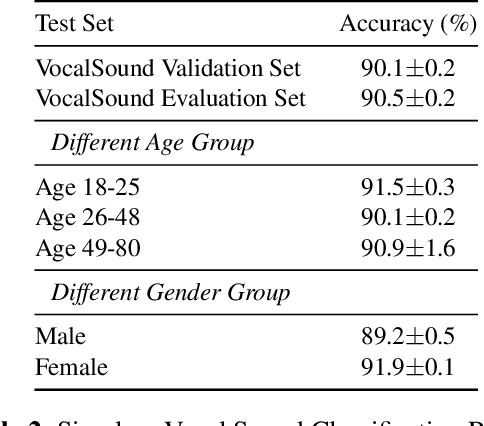
Recognizing human non-speech vocalizations is an important task and has broad applications such as automatic sound transcription and health condition monitoring. However, existing datasets have a relatively small number of vocal sound samples or noisy labels. As a consequence, state-of-the-art audio event classification models may not perform well in detecting human vocal sounds. To support research on building robust and accurate vocal sound recognition, we have created a VocalSound dataset consisting of over 21,000 crowdsourced recordings of laughter, sighs, coughs, throat clearing, sneezes, and sniffs from 3,365 unique subjects. Experiments show that the vocal sound recognition performance of a model can be significantly improved by 41.9% by adding VocalSound dataset to an existing dataset as training material. In addition, different from previous datasets, the VocalSound dataset contains meta information such as speaker age, gender, native language, country, and health condition.
Cross-domain User Preference Learning for Cold-start Recommendation
Dec 07, 2021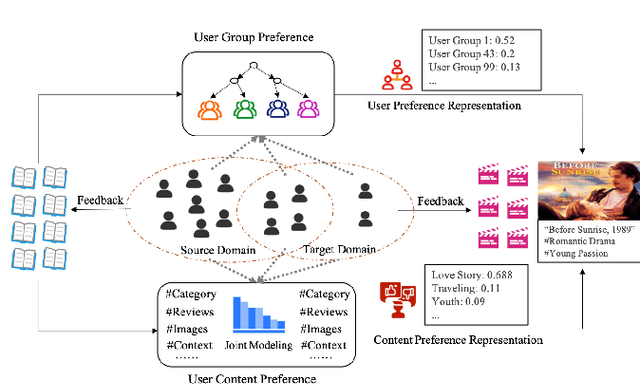
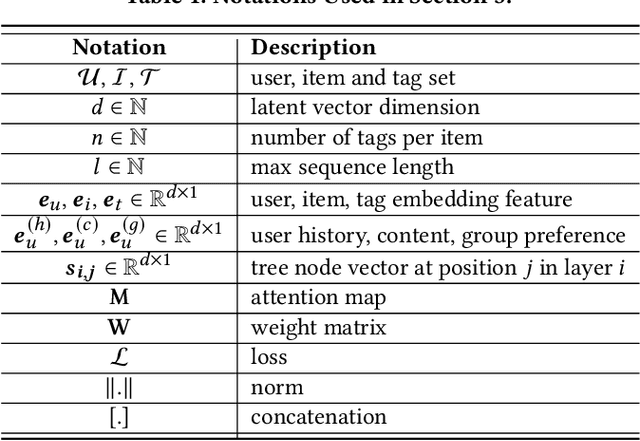
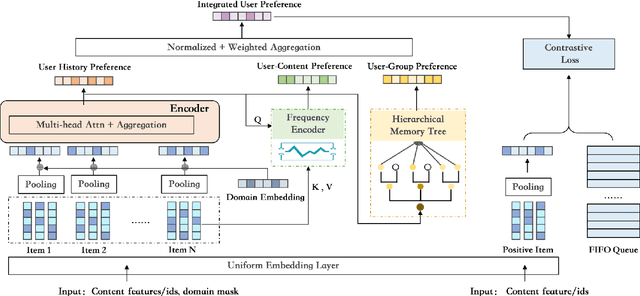
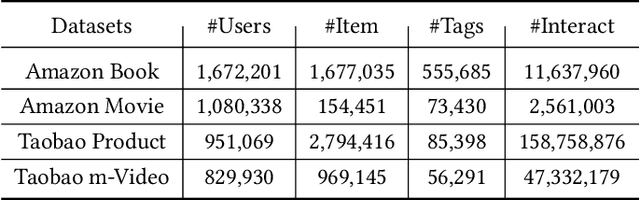
Cross-domain cold-start recommendation is an increasingly emerging issue for recommender systems. Existing works mainly focus on solving either cross-domain user recommendation or cold-start content recommendation. However, when a new domain evolves at its early stage, it has potential users similar to the source domain but with much fewer interactions. It is critical to learn a user's preference from the source domain and transfer it into the target domain, especially on the newly arriving contents with limited user feedback. To bridge this gap, we propose a self-trained Cross-dOmain User Preference LEarning (COUPLE) framework, targeting cold-start recommendation with various semantic tags, such as attributes of items or genres of videos. More specifically, we consider three levels of preferences, including user history, user content and user group to provide reliable recommendation. With user history represented by a domain-aware sequential model, a frequency encoder is applied to the underlying tags for user content preference learning. Then, a hierarchical memory tree with orthogonal node representation is proposed to further generalize user group preference across domains. The whole framework updates in a contrastive way with a First-In-First-Out (FIFO) queue to obtain more distinctive representations. Extensive experiments on two datasets demonstrate the efficiency of COUPLE in both user and content cold-start situations. By deploying an online A/B test for a week, we show that the Click-Through-Rate (CTR) of COUPLE is superior to other baselines used on Taobao APP. Now the method is serving online for the cross-domain cold micro-video recommendation.
Stable Prediction on Graphs with Agnostic Distribution Shift
Oct 08, 2021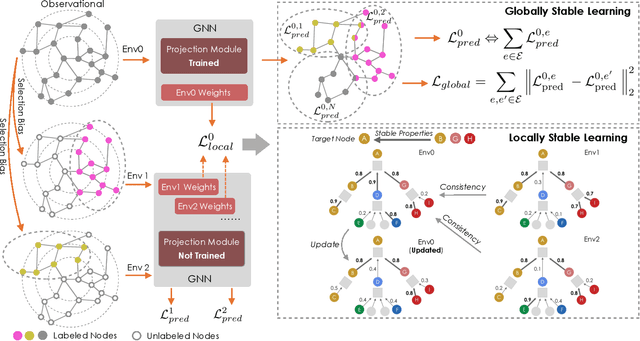
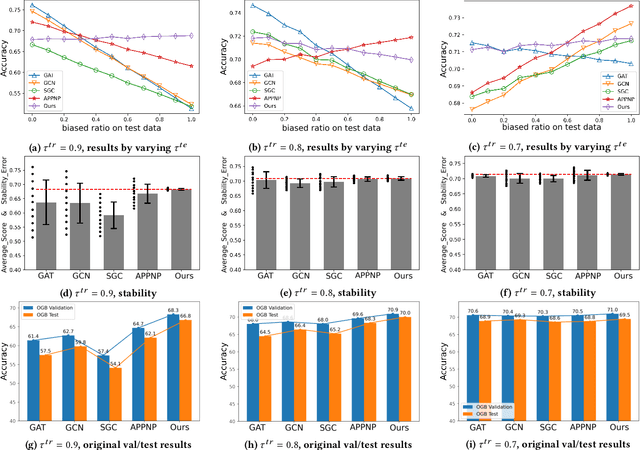
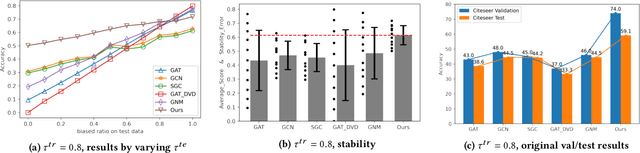
Graph is a flexible and effective tool to represent complex structures in practice and graph neural networks (GNNs) have been shown to be effective on various graph tasks with randomly separated training and testing data. In real applications, however, the distribution of training graph might be different from that of the test one (e.g., users' interactions on the user-item training graph and their actual preference on items, i.e., testing environment, are known to have inconsistencies in recommender systems). Moreover, the distribution of test data is always agnostic when GNNs are trained. Hence, we are facing the agnostic distribution shift between training and testing on graph learning, which would lead to unstable inference of traditional GNNs across different test environments. To address this problem, we propose a novel stable prediction framework for GNNs, which permits both locally and globally stable learning and prediction on graphs. In particular, since each node is partially represented by its neighbors in GNNs, we propose to capture the stable properties for each node (locally stable) by re-weighting the information propagation/aggregation processes. For global stability, we propose a stable regularizer that reduces the training losses on heterogeneous environments and thus warping the GNNs to generalize well. We conduct extensive experiments on several graph benchmarks and a noisy industrial recommendation dataset that is collected from 5 consecutive days during a product promotion festival. The results demonstrate that our method outperforms various SOTA GNNs for stable prediction on graphs with agnostic distribution shift, including shift caused by node labels and attributes.
Deep learning for detecting pulmonary tuberculosis via chest radiography: an international study across 10 countries
May 16, 2021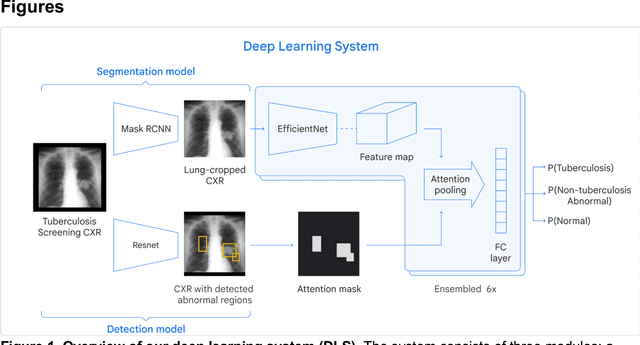
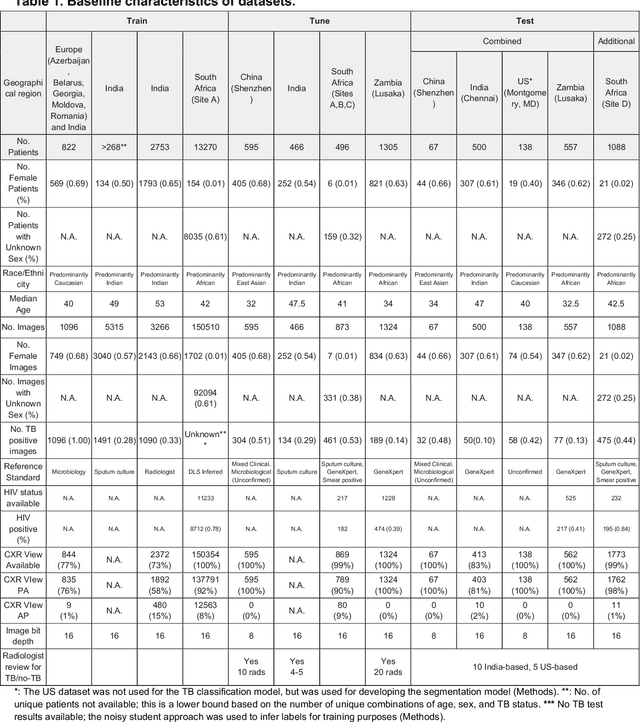
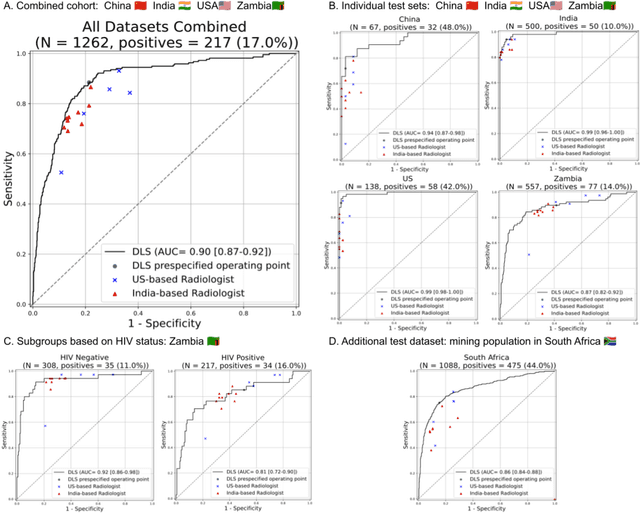
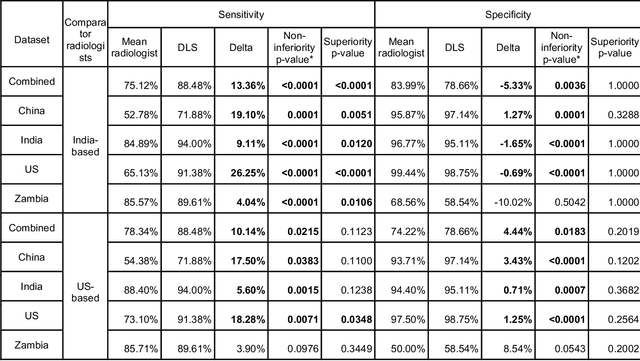
Tuberculosis (TB) is a top-10 cause of death worldwide. Though the WHO recommends chest radiographs (CXRs) for TB screening, the limited availability of CXR interpretation is a barrier. We trained a deep learning system (DLS) to detect active pulmonary TB using CXRs from 9 countries across Africa, Asia, and Europe, and utilized large-scale CXR pretraining, attention pooling, and noisy student semi-supervised learning. Evaluation was on (1) a combined test set spanning China, India, US, and Zambia, and (2) an independent mining population in South Africa. Given WHO targets of 90% sensitivity and 70% specificity, the DLS's operating point was prespecified to favor sensitivity over specificity. On the combined test set, the DLS's ROC curve was above all 9 India-based radiologists, with an AUC of 0.90 (95%CI 0.87-0.92). The DLS's sensitivity (88%) was higher than the India-based radiologists (75% mean sensitivity), p<0.001 for superiority; and its specificity (79%) was non-inferior to the radiologists (84% mean specificity), p=0.004. Similar trends were observed within HIV positive and sputum smear positive sub-groups, and in the South Africa test set. We found that 5 US-based radiologists (where TB isn't endemic) were more sensitive and less specific than the India-based radiologists (where TB is endemic). The DLS also remained non-inferior to the US-based radiologists. In simulations, using the DLS as a prioritization tool for confirmatory testing reduced the cost per positive case detected by 40-80% compared to using confirmatory testing alone. To conclude, our DLS generalized to 5 countries, and merits prospective evaluation to assist cost-effective screening efforts in radiologist-limited settings. Operating point flexibility may permit customization of the DLS to account for site-specific factors such as TB prevalence, demographics, clinical resources, and customary practice patterns.
M6: A Chinese Multimodal Pretrainer
Mar 02, 2021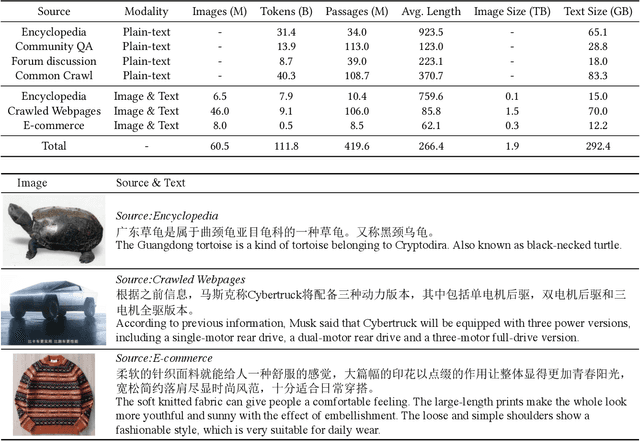
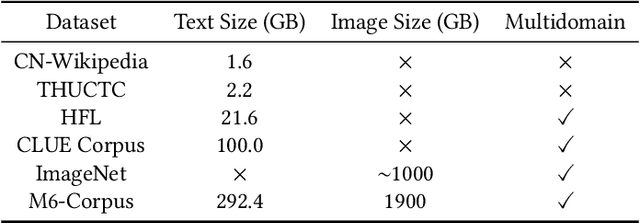

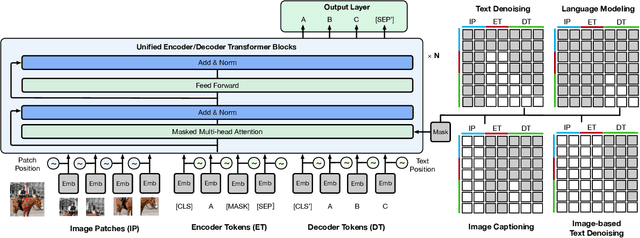
In this work, we construct the largest dataset for multimodal pretraining in Chinese, which consists of over 1.9TB images and 292GB texts that cover a wide range of domains. We propose a cross-modal pretraining method called M6, referring to Multi-Modality to Multi-Modality Multitask Mega-transformer, for unified pretraining on the data of single modality and multiple modalities. We scale the model size up to 10 billion and 100 billion parameters, and build the largest pretrained model in Chinese. We apply the model to a series of downstream applications, and demonstrate its outstanding performance in comparison with strong baselines. Furthermore, we specifically design a downstream task of text-guided image generation, and show that the finetuned M6 can create high-quality images with high resolution and abundant details.
Deep Learning for Distinguishing Normal versus Abnormal Chest Radiographs and Generalization to Unseen Diseases
Oct 22, 2020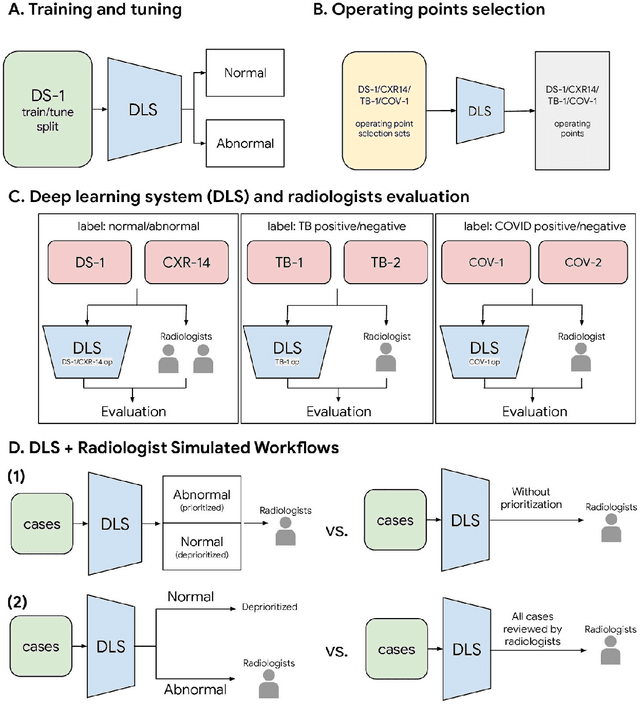
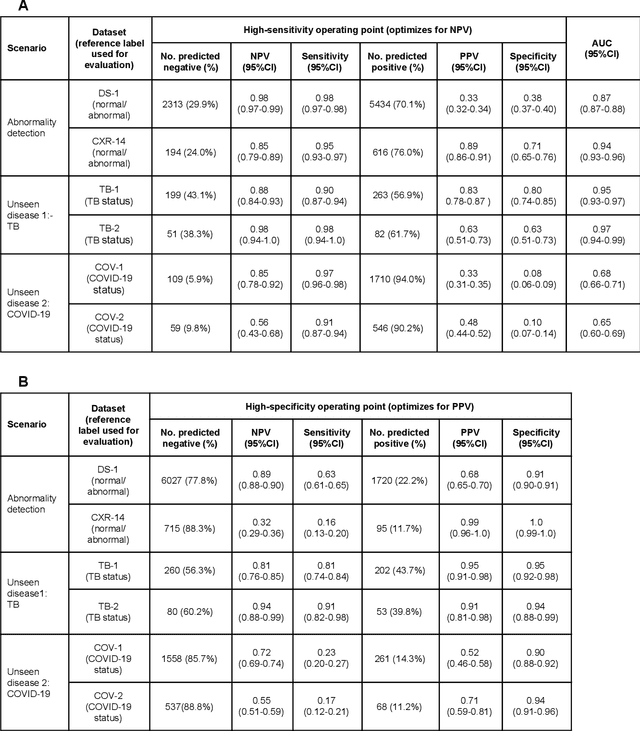
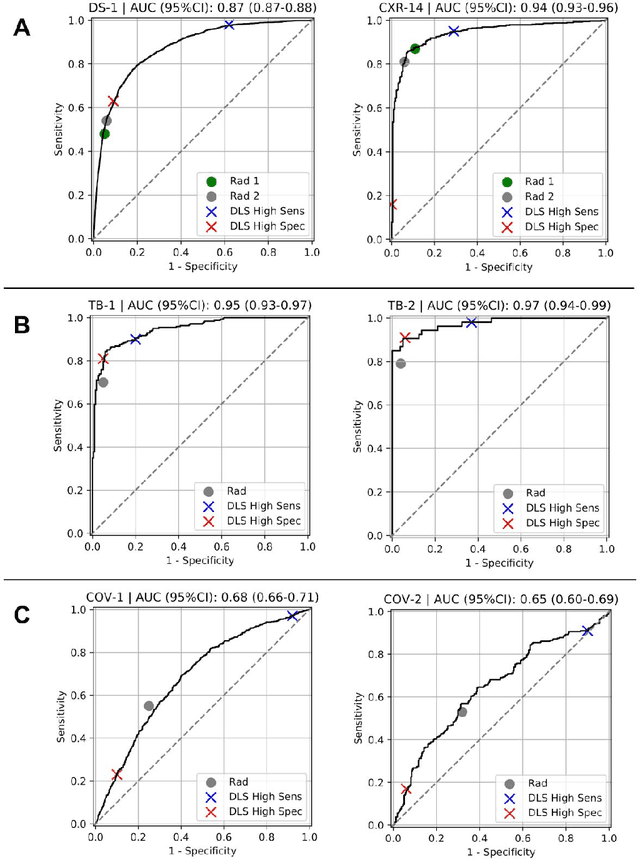
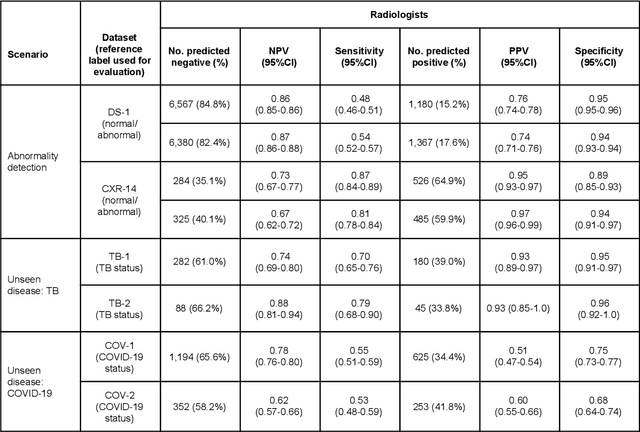
Chest radiography (CXR) is the most widely-used thoracic clinical imaging modality and is crucial for guiding the management of cardiothoracic conditions. The detection of specific CXR findings has been the main focus of several artificial intelligence (AI) systems. However, the wide range of possible CXR abnormalities makes it impractical to build specific systems to detect every possible condition. In this work, we developed and evaluated an AI system to classify CXRs as normal or abnormal. For development, we used a de-identified dataset of 248,445 patients from a multi-city hospital network in India. To assess generalizability, we evaluated our system using 6 international datasets from India, China, and the United States. Of these datasets, 4 focused on diseases that the AI was not trained to detect: 2 datasets with tuberculosis and 2 datasets with coronavirus disease 2019. Our results suggest that the AI system generalizes to new patient populations and abnormalities. In a simulated workflow where the AI system prioritized abnormal cases, the turnaround time for abnormal cases reduced by 7-28%. These results represent an important step towards evaluating whether AI can be safely used to flag cases in a general setting where previously unseen abnormalities exist.