 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-in-the-Loop Interactive Report Generation for Chronic Disease Adherence
Jan 10, 2026Chronic disease management requires regular adherence feedback to prevent avoidable hospitalizations, yet clinicians lack time to produce personalized patient communications. Manual authoring preserves clinical accuracy but does not scale; AI generation scales but can undermine trust in patient-facing contexts. We present a clinician-in-the-loop interface that constrains AI to data organization and preserves physician oversight through recognition-based review. A single-page editor pairs AI-generated section drafts with time-aligned visualizations, enabling inline editing with visual evidence for each claim. This division of labor (AI organizes, clinician decides) targets both efficiency and accountability. In a pilot with three physicians reviewing 24 cases, AI successfully generated clinically personalized drafts matching physicians' manual authoring practice (overall mean 4.86/10 vs. 5.0/10 baseline), requiring minimal physician editing (mean 8.3\% content modification) with zero safety-critical issues, demonstrating effective automation of content generation. However, review time remained comparable to manual practice, revealing an accountability paradox: in high-stakes clinical contexts, professional responsibility requires complete verification regardless of AI accuracy. We contribute three interaction patterns for clinical AI collaboration: bounded generation with recognition-based review via chart-text pairing, automated urgency flagging that analyzes vital trends and adherence patterns with fail-safe escalation for missed critical monitoring tasks, and progressive disclosure controls that reduce cognitive load while maintaining oversight. These patterns indicate that clinical AI efficiency requires not only accurate models, but also mechanisms for selective verification that preserve accountability.
Broadening View Synthesis of Dynamic Scenes from Constrained Monocular Videos
Dec 16, 2025In dynamic Neural Radiance Fields (NeRF) systems, state-of-the-art novel view synthesis methods often fail under significant viewpoint deviations, producing unstable and unrealistic renderings. To address this, we introduce Expanded Dynamic NeRF (ExpanDyNeRF), a monocular NeRF framework that leverages Gaussian splatting priors and a pseudo-ground-truth generation strategy to enable realistic synthesis under large-angle rotations. ExpanDyNeRF optimizes density and color features to improve scene reconstruction from challenging perspectives. We also present the Synthetic Dynamic Multiview (SynDM) dataset, the first synthetic multiview dataset for dynamic scenes with explicit side-view supervision-created using a custom GTA V-based rendering pipeline. Quantitative and qualitative results on SynDM and real-world datasets demonstrate that ExpanDyNeRF significantly outperforms existing dynamic NeRF methods in rendering fidelity under extreme viewpoint shifts. Further details are provided in the supplementary materials.
Discrete Prior-based Temporal-coherent Content Prediction for Blind Face Video Restoration
Jan 17, 2025



Blind face video restoration aims to restore high-fidelity details from videos subjected to complex and unknown degradations. This task poses a significant challenge of managing temporal heterogeneity while at the same time maintaining stable face attributes. In this paper, we introduce a Discrete Prior-based Temporal-Coherent content prediction transformer to address the challenge, and our model is referred to as DP-TempCoh. Specifically, we incorporate a spatial-temporal-aware content prediction module to synthesize high-quality content from discrete visual priors, conditioned on degraded video tokens. To further enhance the temporal coherence of the predicted content, a motion statistics modulation module is designed to adjust the content, based on discrete motion priors in terms of cross-frame mean and variance. As a result, the statistics of the predicted content can match with that of real videos over time. By performing extensive experiments, we verify the effectiveness of the design elements and demonstrate the superior performance of our DP-TempCoh in both synthetically and naturally degraded video restoration.
UFPS: A unified framework for partially-annotated federated segmentation in heterogeneous data distribution
Nov 16, 2023Partially supervised segmentation is a label-saving method based on datasets with fractional classes labeled and intersectant. However, it is still far from landing on real-world medical applications due to privacy concerns and data heterogeneity. As a remedy without privacy leakage, federated partially supervised segmentation (FPSS) is formulated in this work. The main challenges for FPSS are class heterogeneity and client drift. We propose a Unified Federated Partially-labeled Segmentation (UFPS) framework to segment pixels within all classes for partially-annotated datasets by training a totipotential global model without class collision. Our framework includes Unified Label Learning and sparsed Unified Sharpness Aware Minimization for unification of class and feature space, respectively. We find that vanilla combinations for traditional methods in partially supervised segmentation and federated learning are mainly hampered by class collision through empirical study. Our comprehensive experiments on real medical datasets demonstrate better deconflicting and generalization ability of UFPS compared with modified methods.
Temporal-controlled Frame Swap for Generating High-Fidelity Stereo Driving Data for Autonomy Analysis
Jun 12, 2023This paper presents a novel approach, TeFS (Temporal-controlled Frame Swap), to generate synthetic stereo driving data for visual simultaneous localization and mapping (vSLAM) tasks. TeFS is designed to overcome the lack of native stereo vision support in commercial driving simulators, and we demonstrate its effectiveness using Grand Theft Auto V (GTA V), a high-budget open-world video game engine. We introduce GTAV-TeFS, the first large-scale GTA V stereo-driving dataset, containing over 88,000 high-resolution stereo RGB image pairs, along with temporal information, GPS coordinates, camera poses, and full-resolution dense depth maps. GTAV-TeFS offers several advantages over other synthetic stereo datasets and enables the evaluation and enhancement of state-of-the-art stereo vSLAM models under GTA V's environment. We validate the quality of the stereo data collected using TeFS by conducting a comparative analysis with the conventional dual-viewport data using an open-source simulator. We also benchmark various vSLAM models using the challenging-case comparison groups included in GTAV-TeFS, revealing the distinct advantages and limitations inherent to each model. The goal of our work is to bring more high-fidelity stereo data from commercial-grade game simulators into the research domain and push the boundary of vSLAM models.
Bridging the Domain Gap between Synthetic and Real-World Data for Autonomous Driving
Jun 05, 2023



Modern autonomous systems require extensive testing to ensure reliability and build trust in ground vehicles. However, testing these systems in the real-world is challenging due to the lack of large and diverse datasets, especially in edge cases. Therefore, simulations are necessary for their development and evaluation. However, existing open-source simulators often exhibit a significant gap between synthetic and real-world domains, leading to deteriorated mobility performance and reduced platform reliability when using simulation data. To address this issue, our Scoping Autonomous Vehicle Simulation (SAVeS) platform benchmarks the performance of simulated environments for autonomous ground vehicle testing between synthetic and real-world domains. Our platform aims to quantify the domain gap and enable researchers to develop and test autonomous systems in a controlled environment. Additionally, we propose using domain adaptation technologies to address the domain gap between synthetic and real-world data with our SAVeS$^+$ extension. Our results demonstrate that SAVeS$^+$ is effective in helping to close the gap between synthetic and real-world domains and yields comparable performance for models trained with processed synthetic datasets to those trained on real-world datasets of same scale. This paper highlights our efforts to quantify and address the domain gap between synthetic and real-world data for autonomy simulation. By enabling researchers to develop and test autonomous systems in a controlled environment, we hope to bring autonomy simulation one step closer to realization.
SPAC-Net: Synthetic Pose-aware Animal ControlNet for Enhanced Pose Estimation
May 31, 2023Animal pose estimation has become a crucial area of research, but the scarcity of annotated data is a significant challenge in developing accurate models. Synthetic data has emerged as a promising alternative, but it frequently exhibits domain discrepancies with real data. Style transfer algorithms have been proposed to address this issue, but they suffer from insufficient spatial correspondence, leading to the loss of label information. In this work, we present a new approach called Synthetic Pose-aware Animal ControlNet (SPAC-Net), which incorporates ControlNet into the previously proposed Prior-Aware Synthetic animal data generation (PASyn) pipeline. We leverage the plausible pose data generated by the Variational Auto-Encoder (VAE)-based data generation pipeline as input for the ControlNet Holistically-nested Edge Detection (HED) boundary task model to generate synthetic data with pose labels that are closer to real data, making it possible to train a high-precision pose estimation network without the need for real data. In addition, we propose the Bi-ControlNet structure to separately detect the HED boundary of animals and backgrounds, improving the precision and stability of the generated data. Using the SPAC-Net pipeline, we generate synthetic zebra and rhino images and test them on the AP10K real dataset, demonstrating superior performance compared to using only real images or synthetic data generated by other methods. Our work demonstrates the potential for synthetic data to overcome the challenge of limited annotated data in animal pose estimation.
TAP: Accelerating Large-Scale DNN Training Through Tensor Automatic Parallelisation
Feb 01, 2023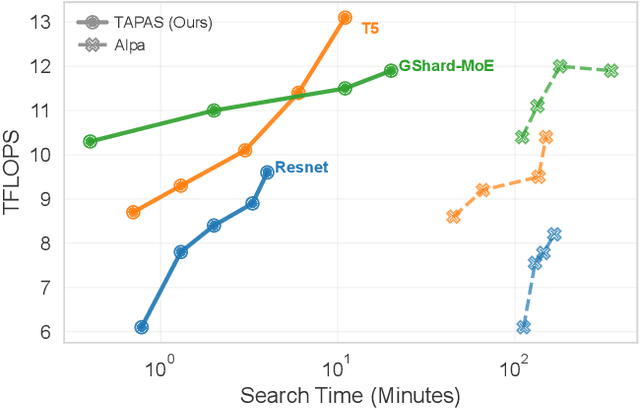

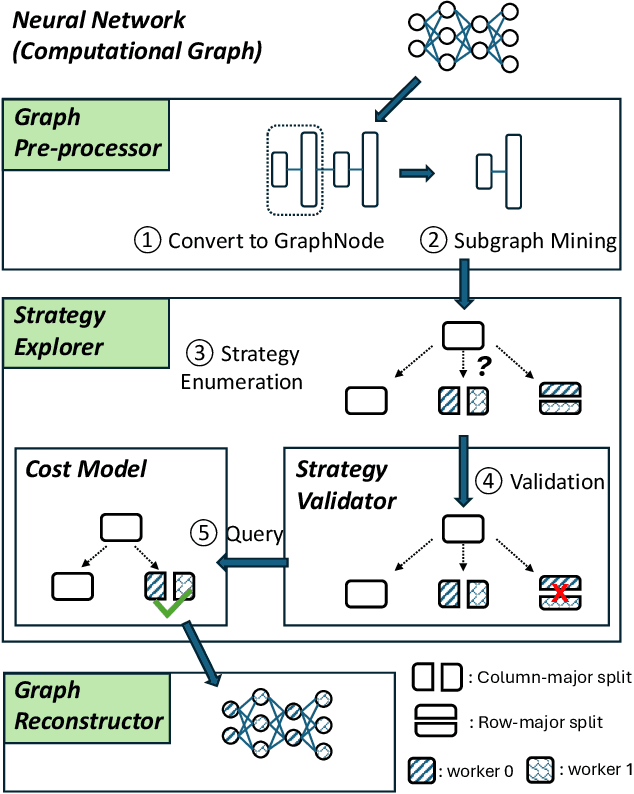
Model parallelism has become necessary to train large neural networks. However, finding a suitable model parallel schedule for an arbitrary neural network is a non-trivial task due to the exploding search space. In this work, we present a model parallelism framework TAP that automatically searches for the best data and tensor parallel schedules. Leveraging the key insight that a neural network can be represented as a directed acyclic graph, within which may only exist a limited set of frequent subgraphs, we design a graph pruning algorithm to fold the search space efficiently. TAP runs at sub-linear complexity concerning the neural network size. Experiments show that TAP is $20\times- 160\times$ faster than the state-of-the-art automatic parallelism framework, and the performance of its discovered schedules is competitive with the expert-engineered ones.
Prior-Aware Synthetic Data to the Rescue: Animal Pose Estimation with Very Limited Real Data
Aug 30, 2022
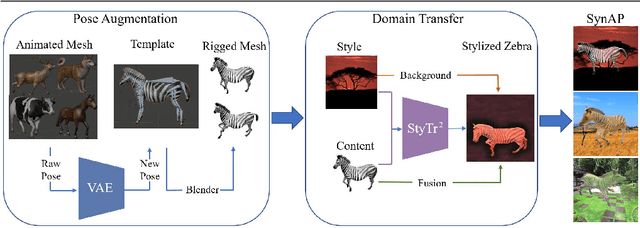
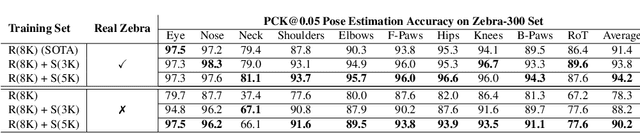
Accurately annotated image datasets are essential components for studying animal behaviors from their poses. Compared to the number of species we know and may exist, the existing labeled pose datasets cover only a small portion of them, while building comprehensive large-scale datasets is prohibitively expensive. Here, we present a very data efficient strategy targeted for pose estimation in quadrupeds that requires only a small amount of real images from the target animal. It is confirmed that fine-tuning a backbone network with pretrained weights on generic image datasets such as ImageNet can mitigate the high demand for target animal pose data and shorten the training time by learning the the prior knowledge of object segmentation and keypoint estimation in advance. However, when faced with serious data scarcity (i.e., $<10^2$ real images), the model performance stays unsatisfactory, particularly for limbs with considerable flexibility and several comparable parts. We therefore introduce a prior-aware synthetic animal data generation pipeline called PASyn to augment the animal pose data essential for robust pose estimation. PASyn generates a probabilistically-valid synthetic pose dataset, SynAP, through training a variational generative model on several animated 3D animal models. In addition, a style transfer strategy is utilized to blend the synthetic animal image into the real backgrounds. We evaluate the improvement made by our approach with three popular backbone networks and test their pose estimation accuracy on publicly available animal pose images as well as collected from real animals in a zoo.
M6-10T: A Sharing-Delinking Paradigm for Efficient Multi-Trillion Parameter Pretraining
Oct 25, 2021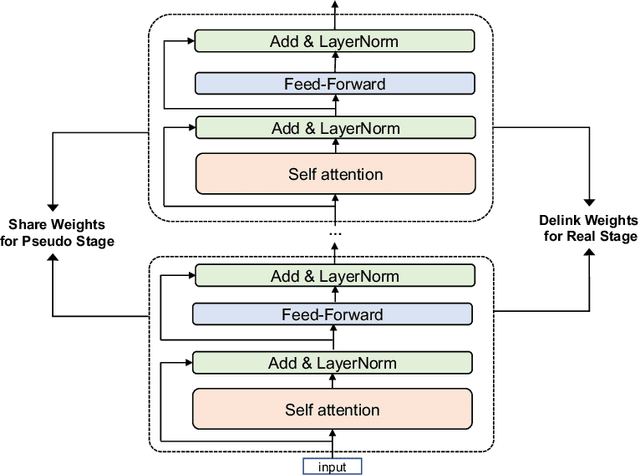

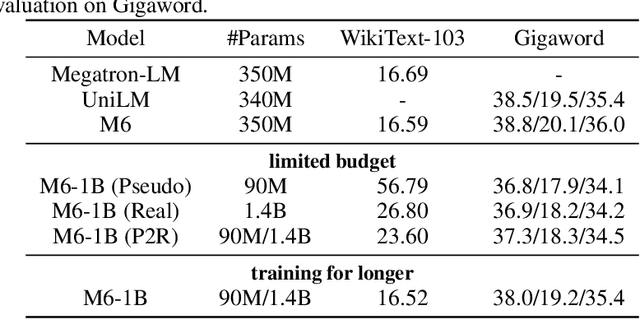
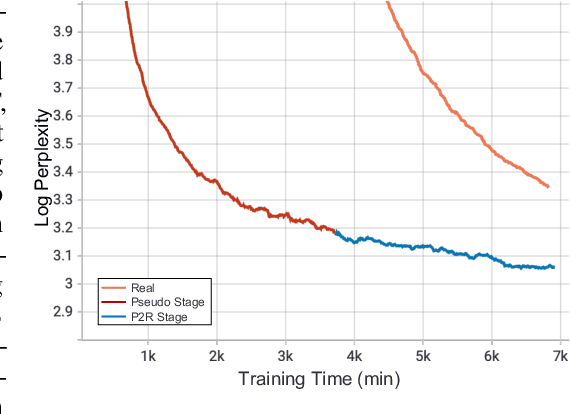
Recent expeditious developments in deep learning algorithms, distributed training, and even hardware design for large models have enabled training extreme-scale models, say GPT-3 and Switch Transformer possessing hundreds of billions or even trillions of parameters. However, under limited resources, extreme-scale model training that requires enormous amounts of computes and memory footprint suffers from frustratingly low efficiency in model convergence. In this paper, we propose a simple training strategy called "Pseudo-to-Real" for high-memory-footprint-required large models. Pseudo-to-Real is compatible with large models with architecture of sequential layers. We demonstrate a practice of pretraining unprecedented 10-trillion-parameter model, an order of magnitude larger than the state-of-the-art, on solely 512 GPUs within 10 days. Besides demonstrating the application of Pseudo-to-Real, we also provide a technique, Granular CPU offloading, to manage CPU memory for training large model and maintain high GPU utilities. Fast training of extreme-scale models on a decent amount of resources can bring much smaller carbon footprint and contribute to greener AI.