 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Situational Awareness in Underwater Robotics with Multi-modal Spatial Perception
Jun 06, 2025



Autonomous Underwater Vehicles (AUVs) and Remotely Operated Vehicles (ROVs) demand robust spatial perception capabilities, including Simultaneous Localization and Mapping (SLAM), to support both remote and autonomous tasks. Vision-based systems have been integral to these advancements, capturing rich color and texture at low cost while enabling semantic scene understanding. However, underwater conditions -- such as light attenuation, backscatter, and low contrast -- often degrade image quality to the point where traditional vision-based SLAM pipelines fail. Moreover, these pipelines typically rely on monocular or stereo inputs, limiting their scalability to the multi-camera configurations common on many vehicles. To address these issues, we propose to leverage multi-modal sensing that fuses data from multiple sensors-including cameras, inertial measurement units (IMUs), and acoustic devices-to enhance situational awareness and enable robust, real-time SLAM. We explore both geometric and learning-based techniques along with semantic analysis, and conduct experiments on the data collected from a work-class ROV during several field deployments in the Trondheim Fjord. Through our experimental results, we demonstrate the feasibility of real-time reliable state estimation and high-quality 3D reconstructions in visually challenging underwater conditions. We also discuss system constraints and identify open research questions, such as sensor calibration, limitations with learning-based methods, that merit further exploration to advance large-scale underwater operations.
Towards Long Term SLAM on Thermal Imagery
Mar 28, 2024



Visual SLAM with thermal imagery, and other low contrast visually degraded environments such as underwater, or in areas dominated by snow and ice, remain a difficult problem for many state of the art (SOTA) algorithms. In addition to challenging front-end data association, thermal imagery presents an additional difficulty for long term relocalization and map reuse. The relative temperatures of objects in thermal imagery change dramatically from day to night. Feature descriptors typically used for relocalization in SLAM are unable to maintain consistency over these diurnal changes. We show that learned feature descriptors can be used within existing Bag of Word based localization schemes to dramatically improve place recognition across large temporal gaps in thermal imagery. In order to demonstrate the effectiveness of our trained vocabulary, we have developed a baseline SLAM system, integrating learned features and matching into a classical SLAM algorithm. Our system demonstrates good local tracking on challenging thermal imagery, and relocalization that overcomes dramatic day to night thermal appearance changes. Our code and datasets are available here: https://github.com/neufieldrobotics/IRSLAM_Baseline
OASIS: Optimal Arrangements for Sensing in SLAM
Sep 19, 2023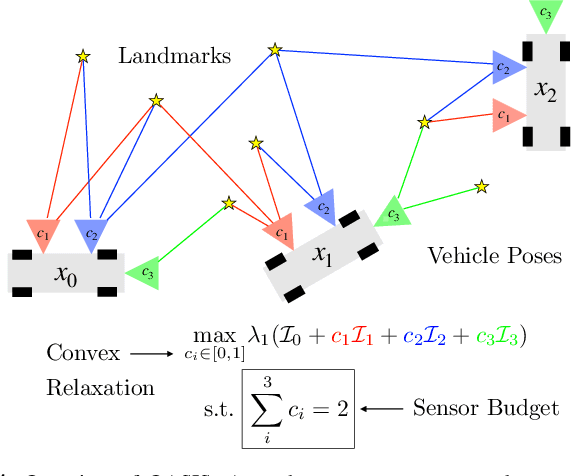

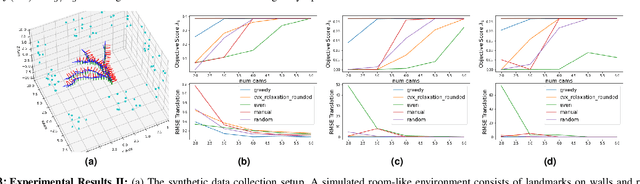

The number and arrangement of sensors on an autonomous mobile robot dramatically influence its perception capabilities. Ensuring that sensors are mounted in a manner that enables accurate detection, localization, and mapping is essential for the success of downstream control tasks. However, when designing a new robotic platform, researchers and practitioners alike usually mimic standard configurations or maximize simple heuristics like field-of-view (FOV) coverage to decide where to place exteroceptive sensors. In this work, we conduct an information-theoretic investigation of this overlooked element of mobile robotic perception in the context of simultaneous localization and mapping (SLAM). We show how to formalize the sensor arrangement problem as a form of subset selection under the E-optimality performance criterion. While this formulation is NP-hard in general, we further show that a combination of greedy sensor selection and fast convex relaxation-based post-hoc verification enables the efficient recovery of certifiably optimal sensor designs in practice. Results from synthetic experiments reveal that sensors placed with OASIS outperform benchmarks in terms of mean squared error of visual SLAM estimates.
Challenges of Indoor SLAM: A multi-modal multi-floor dataset for SLAM evaluation
Jun 14, 2023



Robustness in Simultaneous Localization and Mapping (SLAM) remains one of the key challenges for the real-world deployment of autonomous systems. SLAM research has seen significant progress in the last two and a half decades, yet many state-of-the-art (SOTA) algorithms still struggle to perform reliably in real-world environments. There is a general consensus in the research community that we need challenging real-world scenarios which bring out different failure modes in sensing modalities. In this paper, we present a novel multi-modal indoor SLAM dataset covering challenging common scenarios that a robot will encounter and should be robust to. Our data was collected with a mobile robotics platform across multiple floors at Northeastern University's ISEC building. Such a multi-floor sequence is typical of commercial office spaces characterized by symmetry across floors and, thus, is prone to perceptual aliasing due to similar floor layouts. The sensor suite comprises seven global shutter cameras, a high-grade MEMS inertial measurement unit (IMU), a ZED stereo camera, and a 128-channel high-resolution lidar. Along with the dataset, we benchmark several SLAM algorithms and highlight the problems faced during the runs, such as perceptual aliasing, visual degradation, and trajectory drift. The benchmarking results indicate that parts of the dataset work well with some algorithms, while other data sections are challenging for even the best SOTA algorithms. The dataset is available at https://github.com/neufieldrobotics/NUFR-M3F.
Bridging the Domain Gap between Synthetic and Real-World Data for Autonomous Driving
Jun 05, 2023



Modern autonomous systems require extensive testing to ensure reliability and build trust in ground vehicles. However, testing these systems in the real-world is challenging due to the lack of large and diverse datasets, especially in edge cases. Therefore, simulations are necessary for their development and evaluation. However, existing open-source simulators often exhibit a significant gap between synthetic and real-world domains, leading to deteriorated mobility performance and reduced platform reliability when using simulation data. To address this issue, our Scoping Autonomous Vehicle Simulation (SAVeS) platform benchmarks the performance of simulated environments for autonomous ground vehicle testing between synthetic and real-world domains. Our platform aims to quantify the domain gap and enable researchers to develop and test autonomous systems in a controlled environment. Additionally, we propose using domain adaptation technologies to address the domain gap between synthetic and real-world data with our SAVeS$^+$ extension. Our results demonstrate that SAVeS$^+$ is effective in helping to close the gap between synthetic and real-world domains and yields comparable performance for models trained with processed synthetic datasets to those trained on real-world datasets of same scale. This paper highlights our efforts to quantify and address the domain gap between synthetic and real-world data for autonomy simulation. By enabling researchers to develop and test autonomous systems in a controlled environment, we hope to bring autonomy simulation one step closer to realization.
Design and Evaluation of a Generic Visual SLAM Framework for Multi-Camera Systems
Oct 13, 2022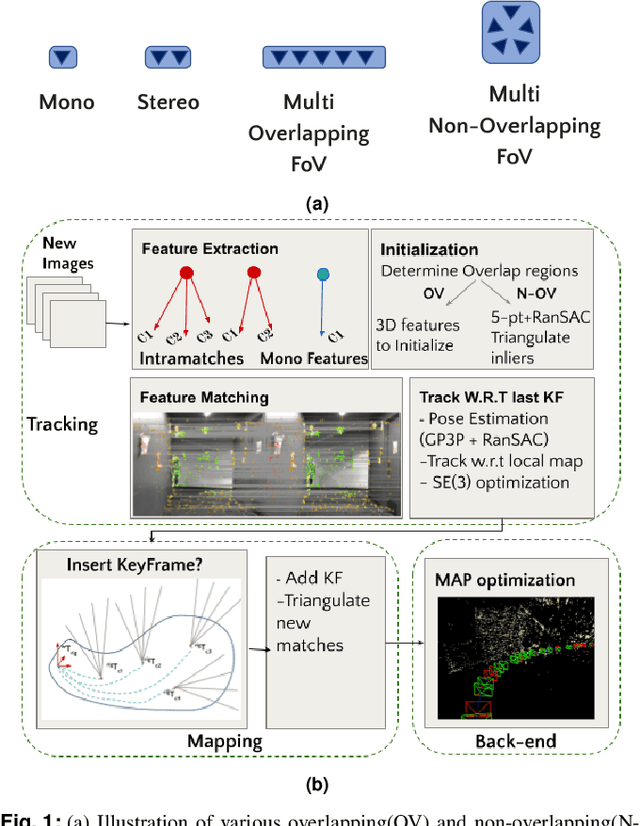

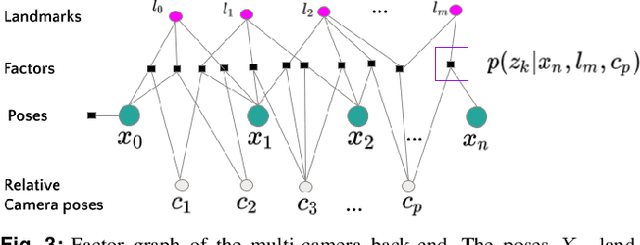

Multi-camera systems have been shown to improve the accuracy and robustness of SLAM estimates, yet state-of-the-art SLAM systems predominantly support monocular or stereo setups. This paper presents a generic sparse visual SLAM framework capable of running on any number of cameras and in any arrangement. Our SLAM system uses the generalized camera model, which allows us to represent an arbitrary multi-camera system as a single imaging device. Additionally, it takes advantage of the overlapping fields of view (FoV) by extracting cross-matched features across cameras in the rig. This limits the linear rise in the number of features with the number of cameras and keeps the computational load in check while enabling an accurate representation of the scene. We evaluate our method in terms of accuracy, robustness, and run time on indoor and outdoor datasets that include challenging real-world scenarios such as narrow corridors, featureless spaces, and dynamic objects. We show that our system can adapt to different camera configurations and allows real-time execution for typical robotic applications. Finally, we benchmark the impact of the critical design parameters - the number of cameras and the overlap between their FoV that define the camera configuration for SLAM. All our software and datasets are freely available for further research.
An Iterative Labeling Method for Annotating Fisheries Imagery
Apr 27, 2022


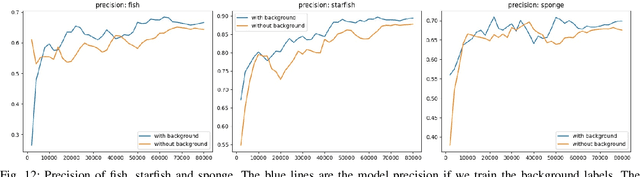
In this paper, we present a methodology for fisheries-related data that allows us to converge on a labeled image dataset by iterating over the dataset with multiple training and production loops that can exploit crowdsourcing interfaces. We present our algorithm and its results on two separate sets of image data collected using the Seabed autonomous underwater vehicle. The first dataset comprises of 2,026 completely unlabeled images, while the second consists of 21,968 images that were point annotated by experts. Our results indicate that training with a small subset and iterating on that to build a larger set of labeled data allows us to converge to a fully annotated dataset with a small number of iterations. Even in the case of a dataset labeled by experts, a single iteration of the methodology improves the labels by discovering additional complicated examples of labels associated with fish that overlap, are very small, or obscured by the contrast limitations associated with underwater imagery.
A Light Field Front-end for Robust SLAM in Dynamic Environments
Dec 19, 2020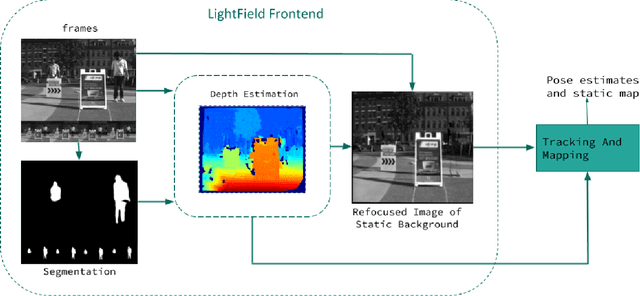
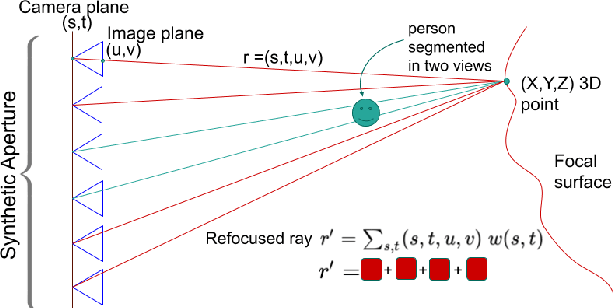
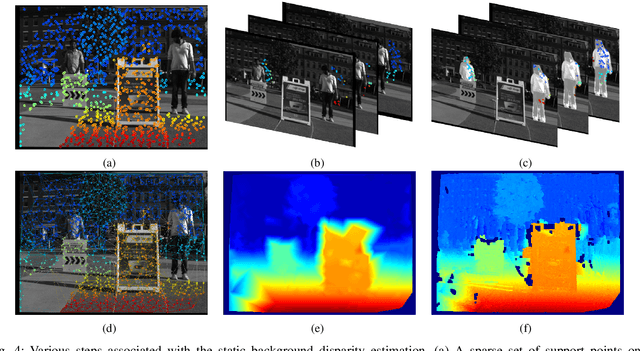
There is a general expectation that robots should operate in urban environments often consisting of potentially dynamic entities including people, furniture and automobiles. Dynamic objects pose challenges to visual SLAM algorithms by introducing errors into the front-end. This paper presents a Light Field SLAM front-end which is robust to dynamic environments. A Light Field captures a bundle of light rays emerging from a single point in space, allowing us to see through dynamic objects occluding the static background via Synthetic Aperture Imaging(SAI). We detect apriori dynamic objects using semantic segmentation and perform semantic guided SAI on the Light Field acquired from a linear camera array. We simultaneously estimate both the depth map and the refocused image of the static background in a single step eliminating the need for static scene initialization. The GPU implementation of the algorithm facilitates running at close to real time speeds of 4 fps. We demonstrate that our method results in improved robustness and accuracy of pose estimation in dynamic environments by comparing it with state of the art SLAM algorithms.
Removing Dynamic Objects for Static Scene Reconstruction using Light Fields
Mar 24, 2020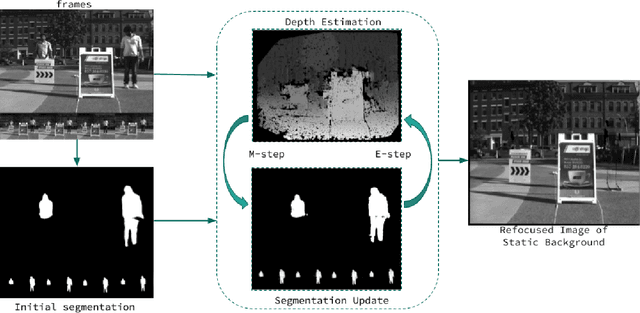
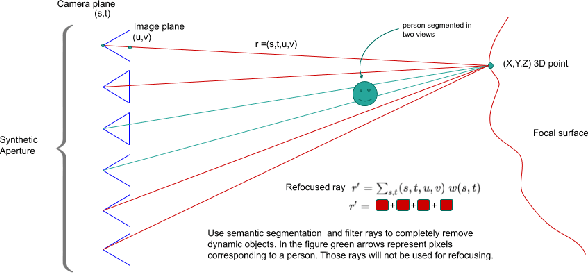
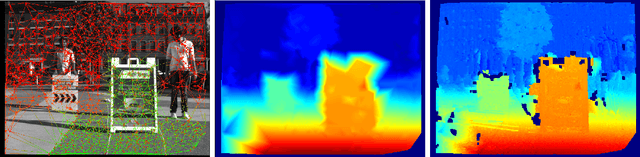
There is a general expectation that robots should operate in environments that consist of static and dynamic entities including people, furniture and automobiles. These dynamic environments pose challenges to visual simultaneous localization and mapping (SLAM) algorithms by introducing errors into the front-end. Light fields provide one possible method for addressing such problems by capturing a more complete visual information of a scene. In contrast to a single ray from a perspective camera, Light Fields capture a bundle of light rays emerging from a single point in space, allowing us to see through dynamic objects by refocusing past them. In this paper we present a method to synthesize a refocused image of the static background in the presence of dynamic objects that uses a light-field acquired with a linear camera array. We simultaneously estimate both the depth and the refocused image of the static scene using semantic segmentation for detecting dynamic objects in a single time step. This eliminates the need for initializing a static map . The algorithm is parallelizable and is implemented on GPU allowing us execute it at close to real time speeds. We demonstrate the effectiveness of our method on real-world data acquired using a small robot with a five camera array.
ROS Rescue : Fault Tolerance System for Robot Operating System
Oct 02, 2019
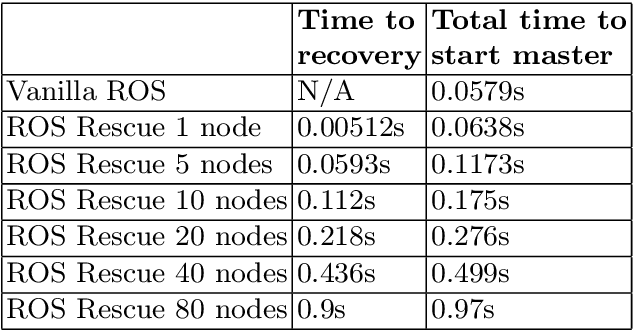
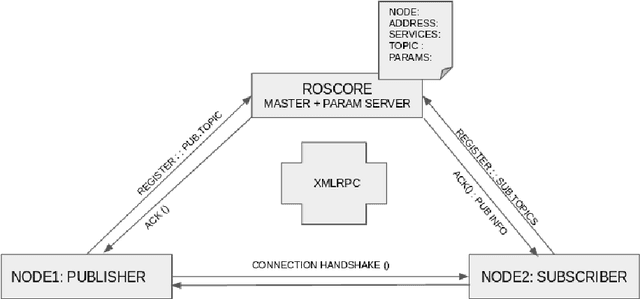
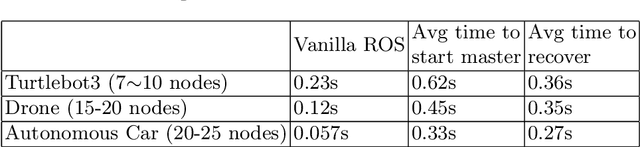
In this chapter we discuss the problem of master failure in ROS1.0 and its impact on robotic deployments in the real world. We address this issue in this tutorial chapter where we outline, design and demonstrate a fault tolerant mechanism associated with ROS master failure. Unlike previous solutions which use primary backup replication and external checkpointing libraries which are process heavy, our mechanism adds a lightweight functionality to the ROS master to enable it to recover from failure. We present a modified version of ROS master which is equipped with a logging mechanism to record the meta information and network state of ROS nodes as well as a recovery mechanism to go back to the previous state without having to abort or restart all the nodes. We also implement an additional master monitor node responsible for failure detection on the master by polling it for its availability. Our code is implemented in python and preliminary tests were conducted successfully on a variety of land, aerial and underwater robots and a tele-operating computer running ROS Kinetic on Ubuntu 16.04. The code is publicly available under a creative commons license on github at https://github.com/PushyamiKaveti/fault-tolerant-ros-master