 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoving Dynamic Objects for Static Scene Reconstruction using Light Fields
Paper and Code
Mar 24, 2020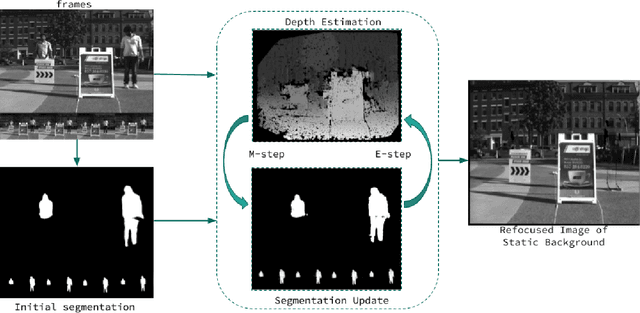
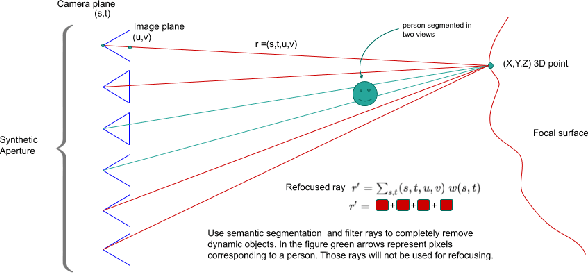
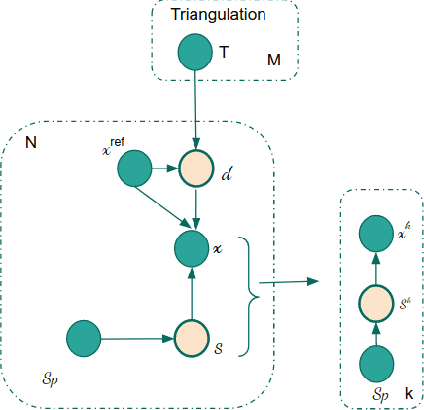
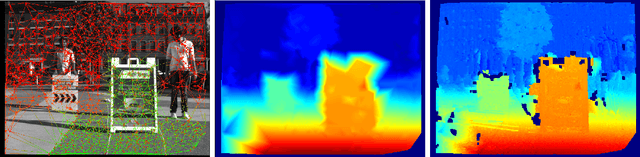
There is a general expectation that robots should operate in environments that consist of static and dynamic entities including people, furniture and automobiles. These dynamic environments pose challenges to visual simultaneous localization and mapping (SLAM) algorithms by introducing errors into the front-end. Light fields provide one possible method for addressing such problems by capturing a more complete visual information of a scene. In contrast to a single ray from a perspective camera, Light Fields capture a bundle of light rays emerging from a single point in space, allowing us to see through dynamic objects by refocusing past them. In this paper we present a method to synthesize a refocused image of the static background in the presence of dynamic objects that uses a light-field acquired with a linear camera array. We simultaneously estimate both the depth and the refocused image of the static scene using semantic segmentation for detecting dynamic objects in a single time step. This eliminates the need for initializing a static map . The algorithm is parallelizable and is implemented on GPU allowing us execute it at close to real time speeds. We demonstrate the effectiveness of our method on real-world data acquired using a small robot with a five camera array.