 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Calibration to Refinement: Seeking Certainty via Probabilistic Evidence Propagation for Noisy-Label Person Re-Identification
Feb 26, 2026With the increasing demand for robust person Re-ID in unconstrained environments, learning from datasets with noisy labels and sparse per-identity samples remains a critical challenge. Existing noise-robust person Re-ID methods primarily rely on loss-correction or sample-selection strategies using softmax outputs. However, these methods suffer from two key limitations: 1) Softmax exhibits translation invariance, leading to over-confident and unreliable predictions on corrupted labels. 2) Conventional sample selection based on small-loss criteria often discards valuable hard positives that are crucial for learning discriminative features. To overcome these issues, we propose the CAlibration-to-REfinement (CARE) method, a two-stage framework that seeks certainty through probabilistic evidence propagation from calibration to refinement. In the calibration stage, we propose the probabilistic evidence calibration (PEC) that dismantles softmax translation invariance by injecting adaptive learnable parameters into the similarity function, and employs an evidential calibration loss to mitigate overconfidence on mislabeled samples. In the refinement stage, we design the evidence propagation refinement (EPR) that can more accurately distinguish between clean and noisy samples. Specifically, the EPR contains two steps: Firstly, the composite angular margin (CAM) metric is proposed to precisely distinguish clean but hard-to-learn positive samples from mislabeled ones in a hyperspherical space; Secondly, the certainty-oriented sphere weighting (COSW) is developed to dynamically allocate the importance of samples according to CAM, ensuring clean instances drive model updates. Extensive experimental results on Market1501, DukeMTMC-ReID, and CUHK03 datasets under both random and patterned noises show that CARE achieves competitive performance.
AMF-MedIT: An Efficient Align-Modulation-Fusion Framework for Medical Image-Tabular Data
Jun 24, 2025



Multimodal medical analysis combining image and tabular data has gained increasing attention. However, effective fusion remains challenging due to cross-modal discrepancies in feature dimensions and modality contributions, as well as the noise from high-dimensional tabular inputs. To address these problems, we present AMF-MedIT, an efficient Align-Modulation-Fusion framework for medical image and tabular data integration, particularly under data-scarce conditions. To harmonize dimension discrepancies and dynamically adjust modality contributions, we propose the Adaptive Modulation and Fusion (AMF) module, a novel modulation-based fusion paradigm with a streamlined architecture. We first derive the modulation objectives and introduce a modality confidence ratio, enabling the incorporation of prior knowledge into the fusion process. Then, the feature masks, density and leakage losses are proposed to achieve the modulation objectives. Additionally, we introduce FT-Mamba, a powerful tabular encoder leveraging a selective mechanism to handle noisy medical tabular data efficiently. Furthermore, interpretability studies are conducted to explore how different tabular encoders supervise the imaging modality during contrastive pretraining for the first time. Extensive experiments demonstrate that AMF-MedIT achieves a superior balance between multimodal performance and data efficiency while showing strong adaptability to incomplete tabular data. Interpretability analysis also highlights FT-Mamba's capabilities in extracting distinct tabular features and guiding the image encoder toward more accurate and flexible attention patterns.
NeuFlow v2: High-Efficiency Optical Flow Estimation on Edge Devices
Aug 21, 2024Real-time high-accuracy optical flow estimation is crucial for various real-world applications. While recent learning-based optical flow methods have achieved high accuracy, they often come with significant computational costs. In this paper, we propose a highly efficient optical flow method that balances high accuracy with reduced computational demands. Building upon NeuFlow v1, we introduce new components including a much more light-weight backbone and a fast refinement module. Both these modules help in keeping the computational demands light while providing close to state of the art accuracy. Compares to other state of the art methods, our model achieves a 10x-70x speedup while maintaining comparable performance on both synthetic and real-world data. It is capable of running at over 20 FPS on 512x384 resolution images on a Jetson Orin Nano. The full training and evaluation code is available at https://github.com/neufieldrobotics/NeuFlow_v2.
STGFormer: Spatio-Temporal GraphFormer for 3D Human Pose Estimation in Video
Jul 14, 2024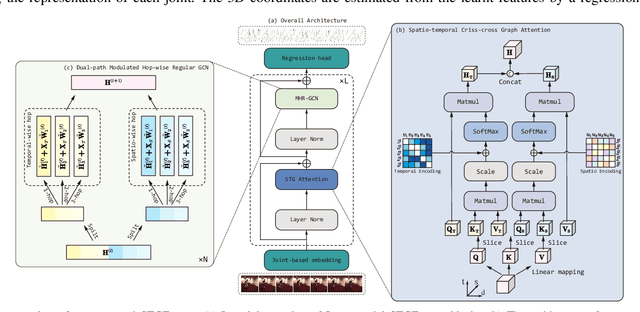

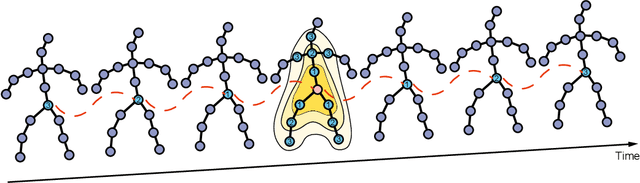

The current methods of video-based 3D human pose estimation have achieved significant progress; however, they continue to confront the significant challenge of depth ambiguity. To address this limitation, this paper presents the spatio-temporal GraphFormer framework for 3D human pose estimation in video, which integrates body structure graph-based representations with spatio-temporal information. Specifically, we develop a spatio-temporal criss-cross graph (STG) attention mechanism. This approach is designed to learn the long-range dependencies in data across both time and space, integrating graph information directly into the respective attention layers. Furthermore, we introduce the dual-path modulated hop-wise regular GCN (MHR-GCN) module, which utilizes modulation to optimize parameter usage and employs spatio-temporal hop-wise skip connections to acquire higher-order information. Additionally, this module processes temporal and spatial dimensions independently to learn their respective features while avoiding mutual influence. Finally, we demonstrate that our method achieves state-of-the-art performance in 3D human pose estimation on the Human3.6M and MPI-INF-3DHP datasets.
NeuFlow: Real-time, High-accuracy Optical Flow Estimation on Robots Using Edge Devices
Mar 15, 2024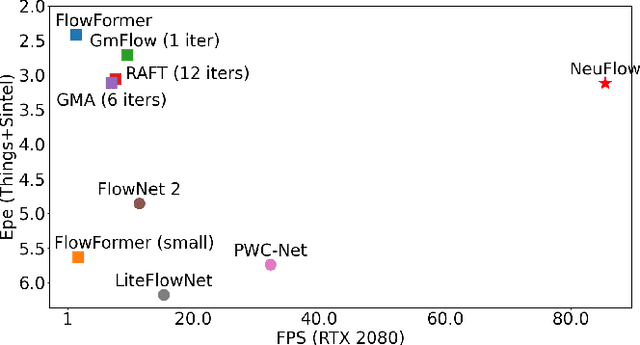


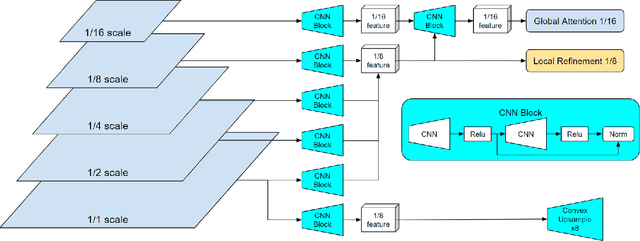
Real-time high-accuracy optical flow estimation is a crucial component in various applications, including localization and mapping in robotics, object tracking, and activity recognition in computer vision. While recent learning-based optical flow methods have achieved high accuracy, they often come with heavy computation costs. In this paper, we propose a highly efficient optical flow architecture, called NeuFlow, that addresses both high accuracy and computational cost concerns. The architecture follows a global-to-local scheme. Given the features of the input images extracted at different spatial resolutions, global matching is employed to estimate an initial optical flow on the 1/16 resolution, capturing large displacement, which is then refined on the 1/8 resolution with lightweight CNN layers for better accuracy. We evaluate our approach on Jetson Orin Nano and RTX 2080 to demonstrate efficiency improvements across different computing platforms. We achieve a notable 10x-80x speedup compared to several state-of-the-art methods, while maintaining comparable accuracy. Our approach achieves around 30 FPS on edge computing platforms, which represents a significant breakthrough in deploying complex computer vision tasks such as SLAM on small robots like drones. The full training and evaluation code is available at https://github.com/neufieldrobotics/NeuFlow.
Deep Learning for 3D Human Pose Estimation and Mesh Recovery: A Survey
Feb 29, 2024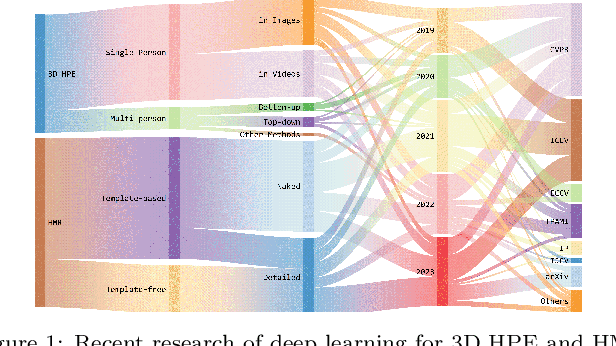
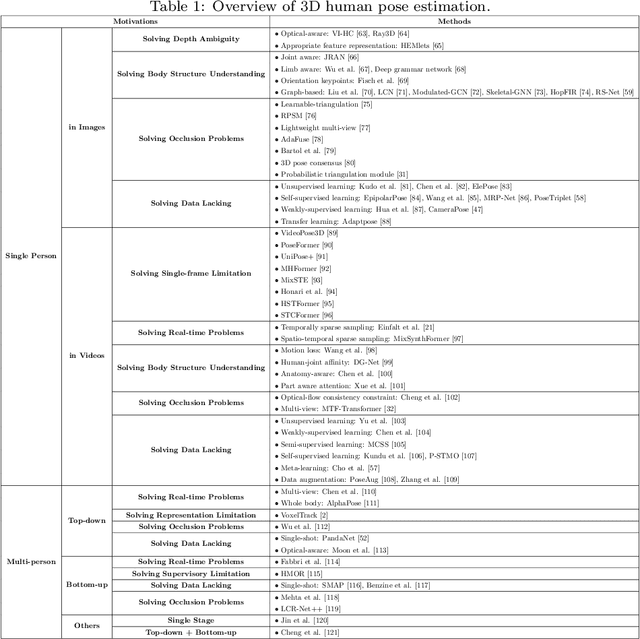
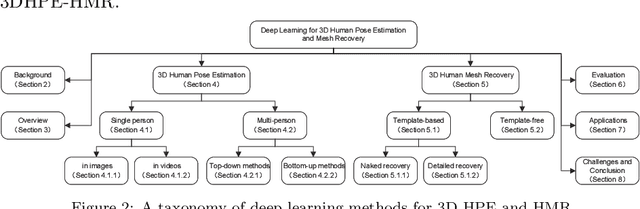
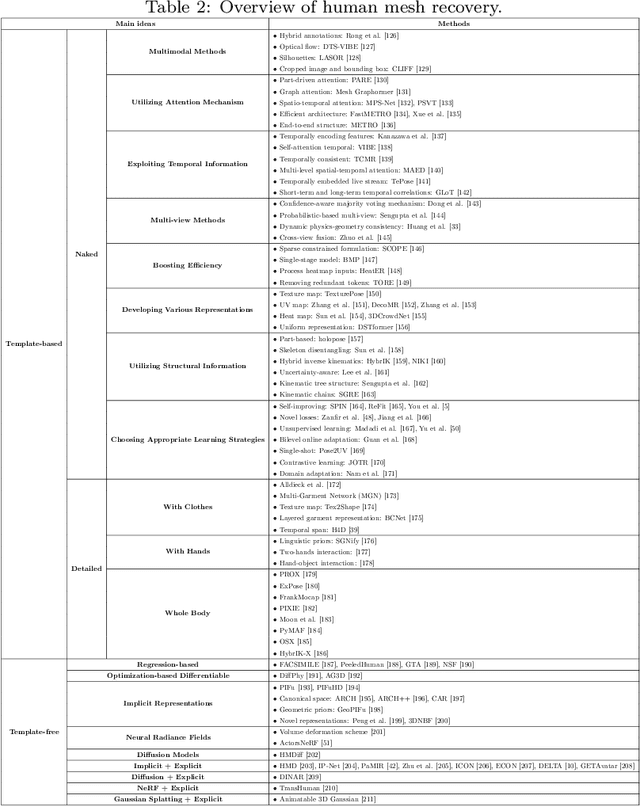
3D human pose estimation and mesh recovery have attracted widespread research interest in many areas, such as computer vision, autonomous driving, and robotics. Deep learning on 3D human pose estimation and mesh recovery has recently thrived, with numerous methods proposed to address different problems in this area. In this paper, to stimulate future research, we present a comprehensive review of recent progress over the past five years in deep learning methods for this area by delving into over 200 references. To the best of our knowledge, this survey is arguably the first to comprehensively cover deep learning methods for 3D human pose estimation, including both single-person and multi-person approaches, as well as human mesh recovery, encompassing methods based on explicit models and implicit representations. We also present comparative results on several publicly available datasets, together with insightful observations and inspiring future research directions. A regularly updated project page can be found at https://github.com/liuyangme/SOTA-3DHPE-HMR.
Challenges of Indoor SLAM: A multi-modal multi-floor dataset for SLAM evaluation
Jun 14, 2023



Robustness in Simultaneous Localization and Mapping (SLAM) remains one of the key challenges for the real-world deployment of autonomous systems. SLAM research has seen significant progress in the last two and a half decades, yet many state-of-the-art (SOTA) algorithms still struggle to perform reliably in real-world environments. There is a general consensus in the research community that we need challenging real-world scenarios which bring out different failure modes in sensing modalities. In this paper, we present a novel multi-modal indoor SLAM dataset covering challenging common scenarios that a robot will encounter and should be robust to. Our data was collected with a mobile robotics platform across multiple floors at Northeastern University's ISEC building. Such a multi-floor sequence is typical of commercial office spaces characterized by symmetry across floors and, thus, is prone to perceptual aliasing due to similar floor layouts. The sensor suite comprises seven global shutter cameras, a high-grade MEMS inertial measurement unit (IMU), a ZED stereo camera, and a 128-channel high-resolution lidar. Along with the dataset, we benchmark several SLAM algorithms and highlight the problems faced during the runs, such as perceptual aliasing, visual degradation, and trajectory drift. The benchmarking results indicate that parts of the dataset work well with some algorithms, while other data sections are challenging for even the best SOTA algorithms. The dataset is available at https://github.com/neufieldrobotics/NUFR-M3F.
An atrium segmentation network with location guidance and siamese adjustment
Jan 11, 2023



The segmentation of atrial scan images is of great significance for the three-dimensional reconstruction of the atrium and the surgical positioning. Most of the existing segmentation networks adopt a 2D structure and only take original images as input, ignoring the context information of 3D images and the role of prior information. In this paper, we propose an atrium segmentation network LGSANet with location guidance and siamese adjustment, which takes adjacent three slices of images as input and adopts an end-to-end approach to achieve coarse-to-fine atrial segmentation. The location guidance(LG) block uses the prior information of the localization map to guide the encoding features of the fine segmentation stage, and the siamese adjustment(SA) block uses the context information to adjust the segmentation edges. On the atrium datasets of ACDC and ASC, sufficient experiments prove that our method can adapt to many classic 2D segmentation networks, so that it can obtain significant performance improvements.
Spatiotemporal implicit neural representation for unsupervised dynamic MRI reconstruction
Dec 31, 2022


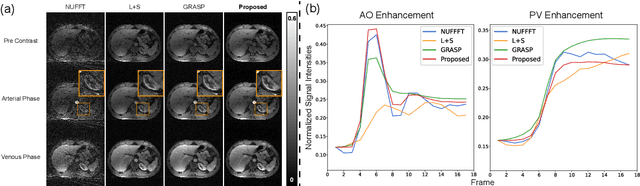
Supervised Deep-Learning (DL)-based reconstruction algorithms have shown state-of-the-art results for highly-undersampled dynamic Magnetic Resonance Imaging (MRI) reconstruction. However, the requirement of excessive high-quality ground-truth data hinders their applications due to the generalization problem. Recently, Implicit Neural Representation (INR) has appeared as a powerful DL-based tool for solving the inverse problem by characterizing the attributes of a signal as a continuous function of corresponding coordinates in an unsupervised manner. In this work, we proposed an INR-based method to improve dynamic MRI reconstruction from highly undersampled k-space data, which only takes spatiotemporal coordinates as inputs. Specifically, the proposed INR represents the dynamic MRI images as an implicit function and encodes them into neural networks. The weights of the network are learned from sparsely-acquired (k, t)-space data itself only, without external training datasets or prior images. Benefiting from the strong implicit continuity regularization of INR together with explicit regularization for low-rankness and sparsity, our proposed method outperforms the compared scan-specific methods at various acceleration factors. E.g., experiments on retrospective cardiac cine datasets show an improvement of 5.5 ~ 7.1 dB in PSNR for extremely high accelerations (up to 41.6-fold). The high-quality and inner continuity of the images provided by INR has great potential to further improve the spatiotemporal resolution of dynamic MRI, without the need of any training data.
Linguistic-Enhanced Transformer with CTC Embedding for Speech Recognition
Oct 25, 2022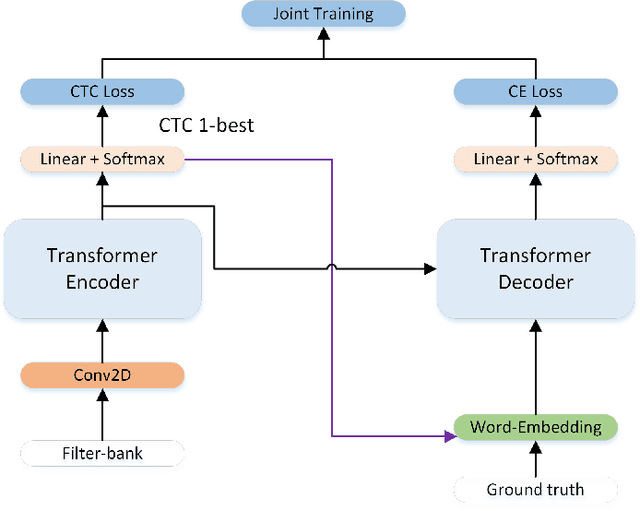
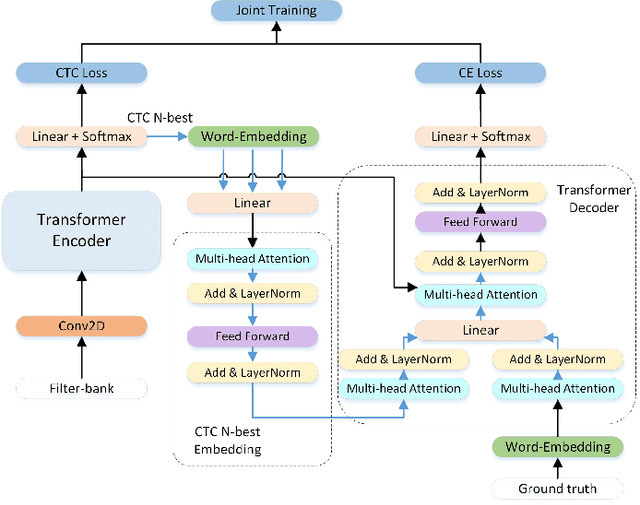
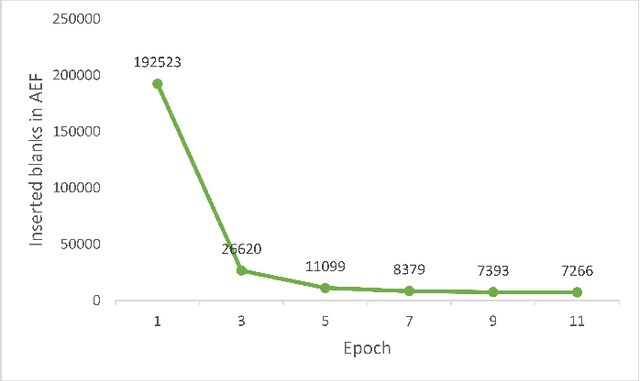
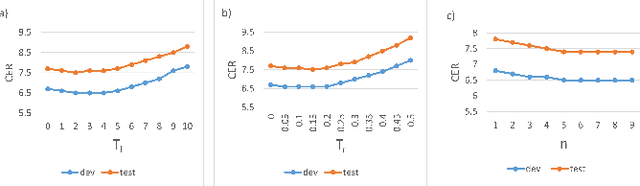
The recent emergence of joint CTC-Attention model shows significant improvement in automatic speech recognition (ASR). The improvement largely lies in the modeling of linguistic information by decoder. The decoder joint-optimized with an acoustic encoder renders the language model from ground-truth sequences in an auto-regressive manner during training. However, the training corpus of the decoder is limited to the speech transcriptions, which is far less than the corpus needed to train an acceptable language model. This leads to poor robustness of decoder. To alleviate this problem, we propose linguistic-enhanced transformer, which introduces refined CTC information to decoder during training process, so that the decoder can be more robust. Our experiments on AISHELL-1 speech corpus show that the character error rate (CER) is relatively reduced by up to 7%. We also find that in joint CTC-Attention ASR model, decoder is more sensitive to linguistic information than acoustic information.