 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTGFormer: Spatio-Temporal GraphFormer for 3D Human Pose Estimation in Video
Paper and Code
Jul 14, 2024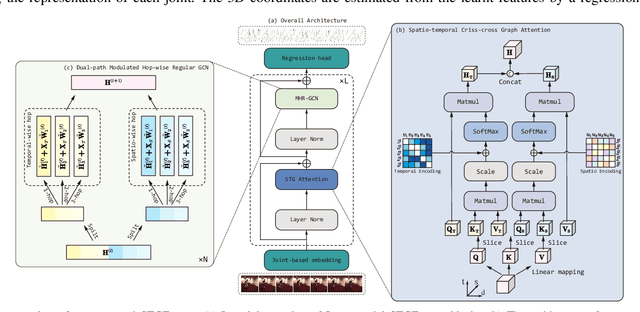


The current methods of video-based 3D human pose estimation have achieved significant progress; however, they continue to confront the significant challenge of depth ambiguity. To address this limitation, this paper presents the spatio-temporal GraphFormer framework for 3D human pose estimation in video, which integrates body structure graph-based representations with spatio-temporal information. Specifically, we develop a spatio-temporal criss-cross graph (STG) attention mechanism. This approach is designed to learn the long-range dependencies in data across both time and space, integrating graph information directly into the respective attention layers. Furthermore, we introduce the dual-path modulated hop-wise regular GCN (MHR-GCN) module, which utilizes modulation to optimize parameter usage and employs spatio-temporal hop-wise skip connections to acquire higher-order information. Additionally, this module processes temporal and spatial dimensions independently to learn their respective features while avoiding mutual influence. Finally, we demonstrate that our method achieves state-of-the-art performance in 3D human pose estimation on the Human3.6M and MPI-INF-3DHP datasets.