 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Efficacy of Signal Decomposition in AI-based Time Series Prediction
May 11, 2024Time series prediction is a fundamental problem in scientific exploration and artificial intelligence (AI) technologies have substantially bolstered its efficiency and accuracy. A well-established paradigm in AI-driven time series prediction is injecting physical knowledge into neural networks through signal decomposition methods, and sustaining progress in numerous scenarios has been reported. However, we uncover non-negligible evidence that challenges the effectiveness of signal decomposition in AI-based time series prediction. We confirm that improper dataset processing with subtle future label leakage is unfortunately widely adopted, possibly yielding abnormally superior but misleading results. By processing data in a strictly causal way without any future information, the effectiveness of additional decomposed signals diminishes. Our work probably identifies an ingrained and universal error in time series modeling, and the de facto progress in relevant areas is expected to be revisited and calibrated to prevent future scientific detours and minimize practical losses.
KETM:A Knowledge-Enhanced Text Matching method
Aug 11, 2023Text matching is the task of matching two texts and determining the relationship between them, which has extensive applications in natural language processing tasks such as reading comprehension, and Question-Answering systems. The mainstream approach is to compute text representations or to interact with the text through attention mechanism, which is effective in text matching tasks. However, the performance of these models is insufficient for texts that require commonsense knowledge-based reasoning. To this end, in this paper, We introduce a new model for text matching called the Knowledge Enhanced Text Matching model (KETM), to enrich contextual representations with real-world common-sense knowledge from external knowledge sources to enhance our model understanding and reasoning. First, we use Wiktionary to retrieve the text word definitions as our external knowledge. Secondly, we feed text and knowledge to the text matching module to extract their feature vectors. The text matching module is used as an interaction module by integrating the encoder layer, the co-attention layer, and the aggregation layer. Specifically, the interaction process is iterated several times to obtain in-depth interaction information and extract the feature vectors of text and knowledge by multi-angle pooling. Then, we fuse text and knowledge using a gating mechanism to learn the ratio of text and knowledge fusion by a neural network that prevents noise generated by knowledge. After that, experimental validation on four datasets are carried out, and the experimental results show that our proposed model performs well on all four datasets, and the performance of our method is improved compared to the base model without adding external knowledge, which validates the effectiveness of our proposed method. The code is available at https://github.com/1094701018/KETM
Automatic segmentation of meniscus based on MAE self-supervision and point-line weak supervision paradigm
May 07, 2022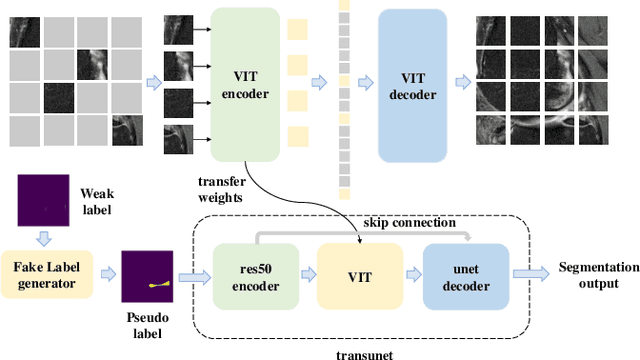

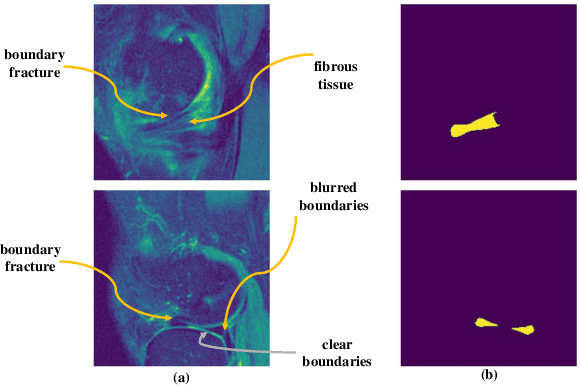
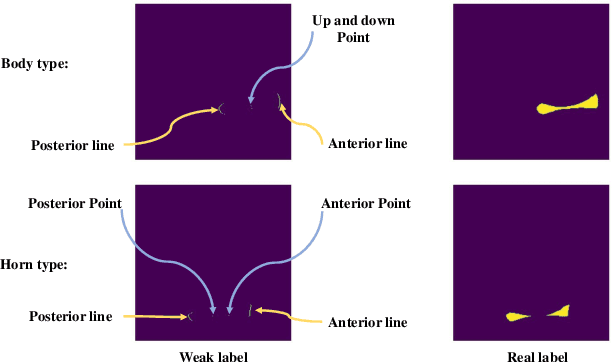
Medical image segmentation based on deep learning is often faced with the problems of insufficient datasets and long time-consuming labeling. In this paper, we introduce the self-supervised method MAE(Masked Autoencoders) into knee joint images to provide a good initial weight for the segmentation model and improve the adaptability of the model to small datasets. Secondly, we propose a weakly supervised paradigm for meniscus segmentation based on the combination of point and line to reduce the time of labeling. Based on the weak label ,we design a region growing algorithm to generate pseudo-label. Finally we train the segmentation network based on pseudo-labels with weight transfer from self-supervision. Sufficient experimental results show that our proposed method combining self-supervision and weak supervision can almost approach the performance of purely fully supervised models while greatly reducing the required labeling time and dataset size.
DEIM: An effective deep encoding and interaction model for sentence matching
Mar 20, 2022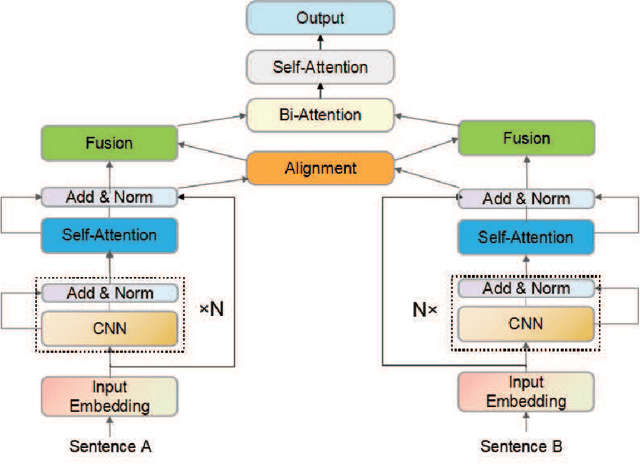
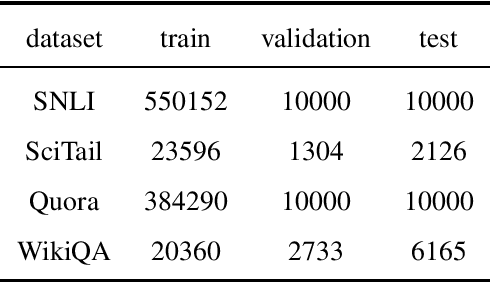


Natural language sentence matching is the task of comparing two sentences and identifying the relationship between them.It has a wide range of applications in natural language processing tasks such as reading comprehension, question and answer systems. The main approach is to compute the interaction between text representations and sentence pairs through an attention mechanism, which can extract the semantic information between sentence pairs well. However,this kind of method can not gain satisfactory results when dealing with complex semantic features. To solve this problem, we propose a sentence matching method based on deep encoding and interaction to extract deep semantic information. In the encoder layer,we refer to the information of another sentence in the process of encoding a single sentence, and later use a heuristic algorithm to fuse the information. In the interaction layer, we use a bidirectional attention mechanism and a self-attention mechanism to obtain deep semantic information.Finally, we perform a pooling operation and input it to the MLP for classification. we evaluate our model on three tasks: recognizing textual entailment, paraphrase recognition, and answer selection. We conducted experiments on the SNLI and SciTail datasets for the recognizing textual entailment task, the Quora dataset for the paraphrase recognition task, and the WikiQA dataset for the answer selection task. The experimental results show that the proposed algorithm can effectively extract deep semantic features that verify the effectiveness of the algorithm on sentence matching tasks.