 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for 3D Human Pose Estimation and Mesh Recovery: A Survey
Feb 29, 2024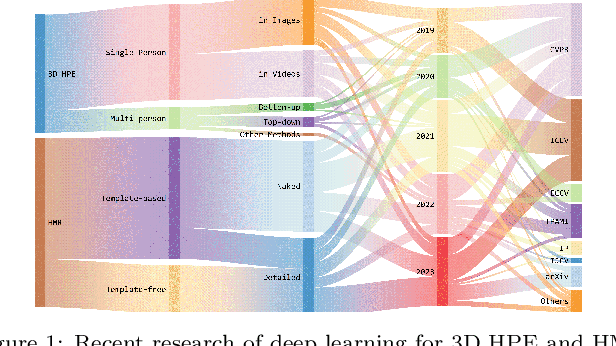
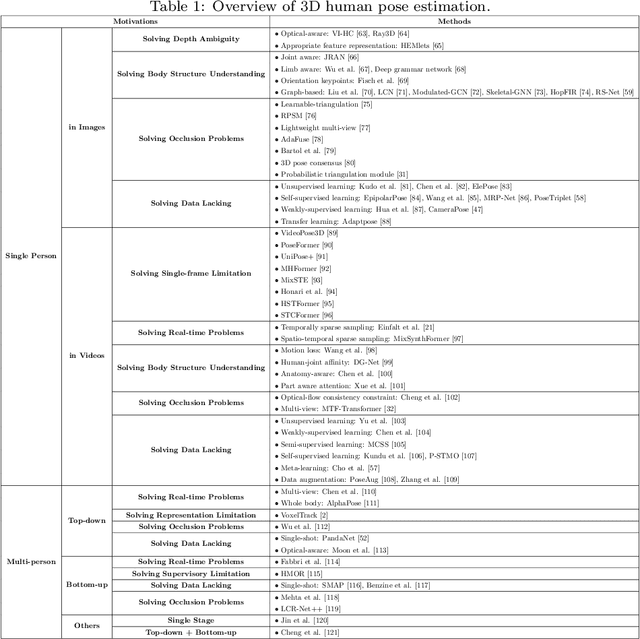
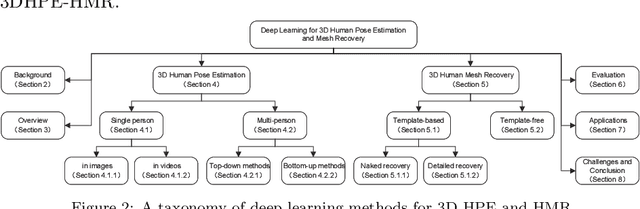
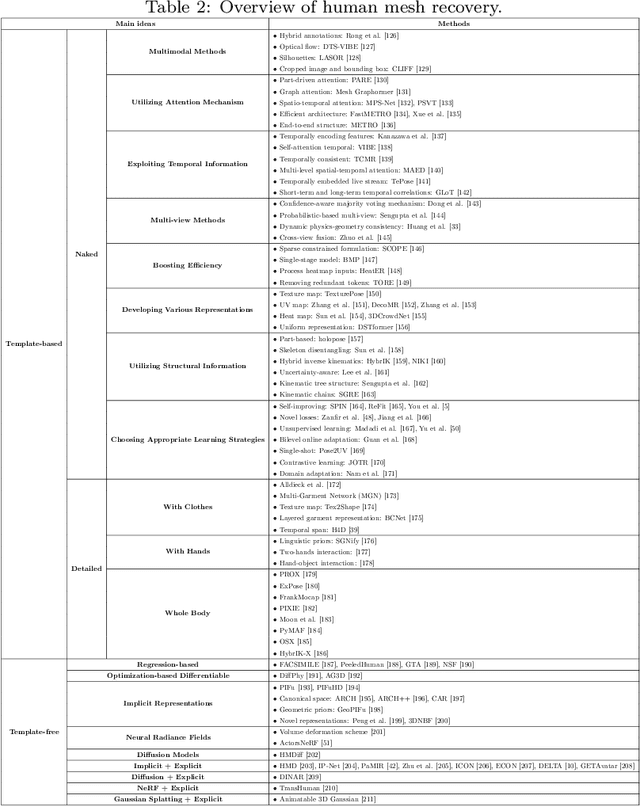
3D human pose estimation and mesh recovery have attracted widespread research interest in many areas, such as computer vision, autonomous driving, and robotics. Deep learning on 3D human pose estimation and mesh recovery has recently thrived, with numerous methods proposed to address different problems in this area. In this paper, to stimulate future research, we present a comprehensive review of recent progress over the past five years in deep learning methods for this area by delving into over 200 references. To the best of our knowledge, this survey is arguably the first to comprehensively cover deep learning methods for 3D human pose estimation, including both single-person and multi-person approaches, as well as human mesh recovery, encompassing methods based on explicit models and implicit representations. We also present comparative results on several publicly available datasets, together with insightful observations and inspiring future research directions. A regularly updated project page can be found at https://github.com/liuyangme/SOTA-3DHPE-HMR.
An atrium segmentation network with location guidance and siamese adjustment
Jan 11, 2023



The segmentation of atrial scan images is of great significance for the three-dimensional reconstruction of the atrium and the surgical positioning. Most of the existing segmentation networks adopt a 2D structure and only take original images as input, ignoring the context information of 3D images and the role of prior information. In this paper, we propose an atrium segmentation network LGSANet with location guidance and siamese adjustment, which takes adjacent three slices of images as input and adopts an end-to-end approach to achieve coarse-to-fine atrial segmentation. The location guidance(LG) block uses the prior information of the localization map to guide the encoding features of the fine segmentation stage, and the siamese adjustment(SA) block uses the context information to adjust the segmentation edges. On the atrium datasets of ACDC and ASC, sufficient experiments prove that our method can adapt to many classic 2D segmentation networks, so that it can obtain significant performance improvements.
Automatic segmentation of meniscus based on MAE self-supervision and point-line weak supervision paradigm
May 07, 2022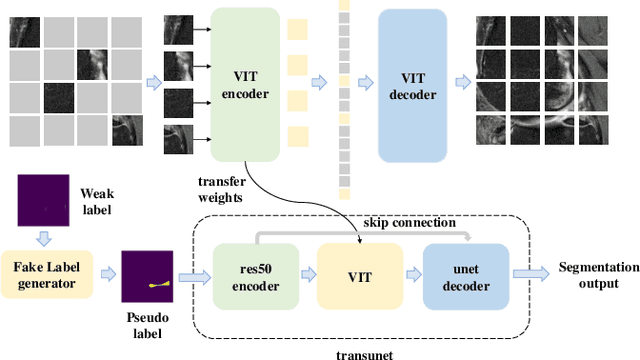

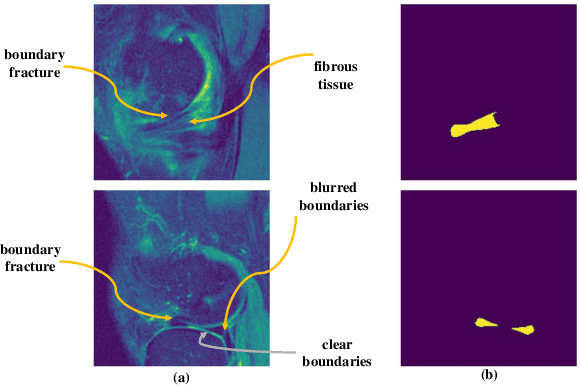
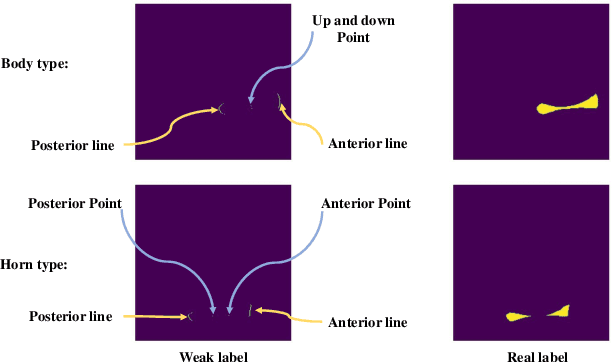
Medical image segmentation based on deep learning is often faced with the problems of insufficient datasets and long time-consuming labeling. In this paper, we introduce the self-supervised method MAE(Masked Autoencoders) into knee joint images to provide a good initial weight for the segmentation model and improve the adaptability of the model to small datasets. Secondly, we propose a weakly supervised paradigm for meniscus segmentation based on the combination of point and line to reduce the time of labeling. Based on the weak label ,we design a region growing algorithm to generate pseudo-label. Finally we train the segmentation network based on pseudo-labels with weight transfer from self-supervision. Sufficient experimental results show that our proposed method combining self-supervision and weak supervision can almost approach the performance of purely fully supervised models while greatly reducing the required labeling time and dataset size.
FakeTransformer: Exposing Face Forgery From Spatial-Temporal Representation Modeled By Facial Pixel Variations
Nov 15, 2021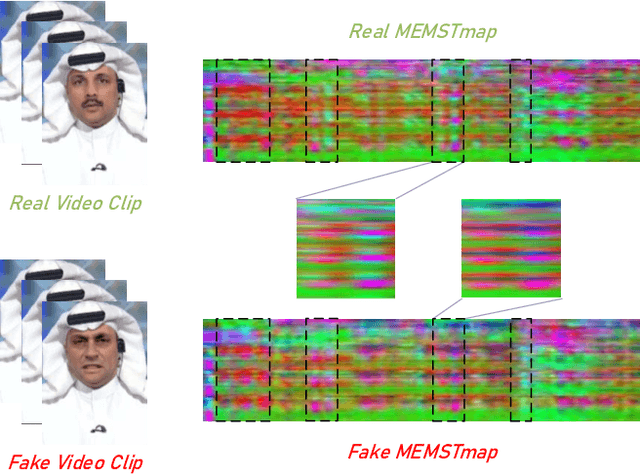
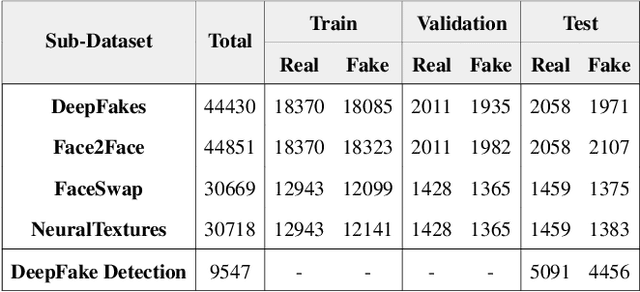
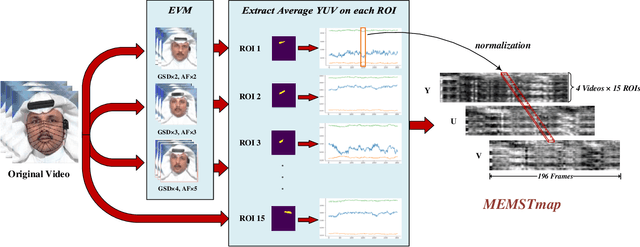
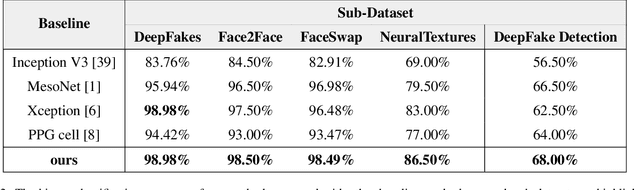
With the rapid development of generation model, AI-based face manipulation technology, which called DeepFakes, has become more and more realistic. This means of face forgery can attack any target, which poses a new threat to personal privacy and property security. Moreover, the misuse of synthetic video shows potential dangers in many areas, such as identity harassment, pornography and news rumors. Inspired by the fact that the spatial coherence and temporal consistency of physiological signal are destroyed in the generated content, we attempt to find inconsistent patterns that can distinguish between real videos and synthetic videos from the variations of facial pixels, which are highly related to physiological information. Our approach first applies Eulerian Video Magnification (EVM) at multiple Gaussian scales to the original video to enlarge the physiological variations caused by the change of facial blood volume, and then transform the original video and magnified videos into a Multi-Scale Eulerian Magnified Spatial-Temporal map (MEMSTmap), which can represent time-varying physiological enhancement sequences on different octaves. Then, these maps are reshaped into frame patches in column units and sent to the vision Transformer to learn the spatio-time descriptors of frame levels. Finally, we sort out the feature embedding and output the probability of judging whether the video is real or fake. We validate our method on the FaceForensics++ and DeepFake Detection datasets. The results show that our model achieves excellent performance in forgery detection, and also show outstanding generalization capability in cross-data domain.