 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFakeTransformer: Exposing Face Forgery From Spatial-Temporal Representation Modeled By Facial Pixel Variations
Paper and Code
Nov 15, 2021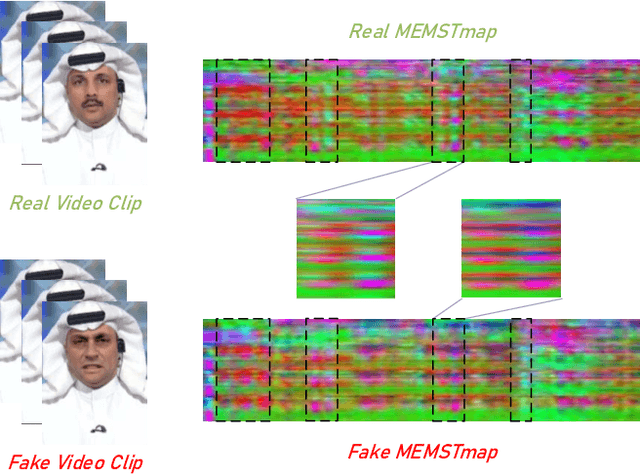
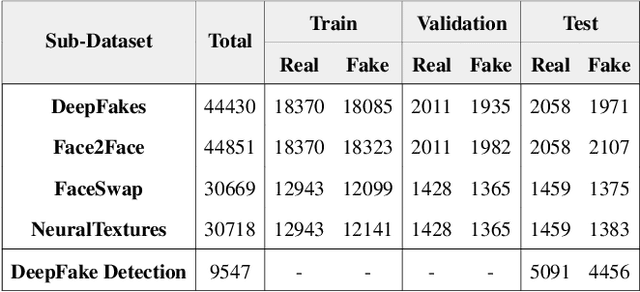
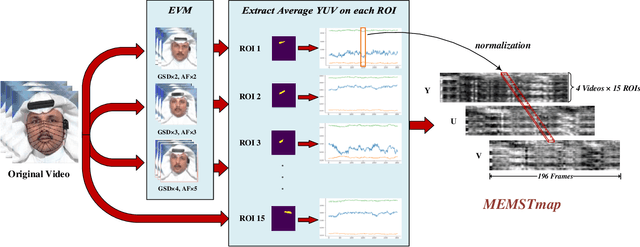
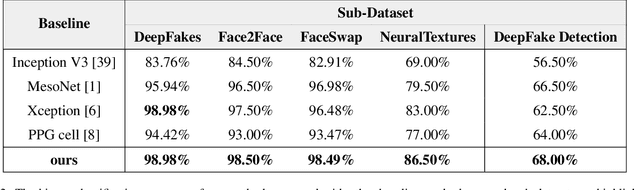
With the rapid development of generation model, AI-based face manipulation technology, which called DeepFakes, has become more and more realistic. This means of face forgery can attack any target, which poses a new threat to personal privacy and property security. Moreover, the misuse of synthetic video shows potential dangers in many areas, such as identity harassment, pornography and news rumors. Inspired by the fact that the spatial coherence and temporal consistency of physiological signal are destroyed in the generated content, we attempt to find inconsistent patterns that can distinguish between real videos and synthetic videos from the variations of facial pixels, which are highly related to physiological information. Our approach first applies Eulerian Video Magnification (EVM) at multiple Gaussian scales to the original video to enlarge the physiological variations caused by the change of facial blood volume, and then transform the original video and magnified videos into a Multi-Scale Eulerian Magnified Spatial-Temporal map (MEMSTmap), which can represent time-varying physiological enhancement sequences on different octaves. Then, these maps are reshaped into frame patches in column units and sent to the vision Transformer to learn the spatio-time descriptors of frame levels. Finally, we sort out the feature embedding and output the probability of judging whether the video is real or fake. We validate our method on the FaceForensics++ and DeepFake Detection datasets. The results show that our model achieves excellent performance in forgery detection, and also show outstanding generalization capability in cross-data domain.