 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniDrive-R1: Reinforcement-driven Interleaved Multi-modal Chain-of-Thought for Trustworthy Vision-Language Autonomous Driving
Dec 16, 2025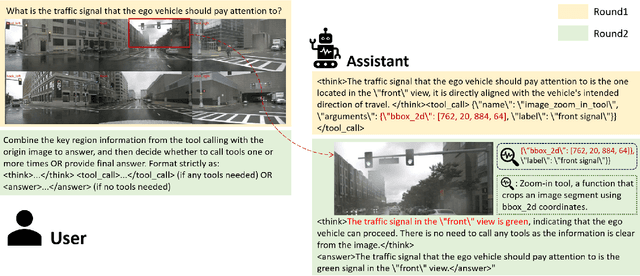

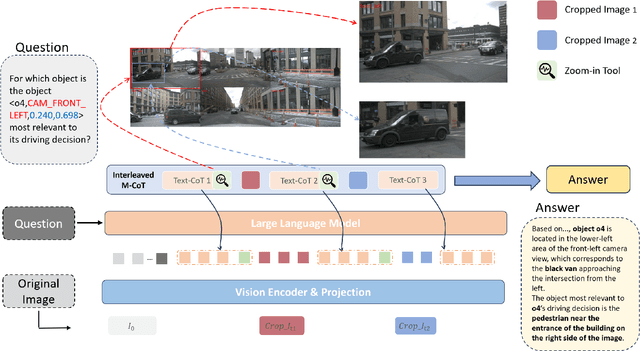

The deployment of Vision-Language Models (VLMs) in safety-critical domains like autonomous driving (AD) is critically hindered by reliability failures, most notably object hallucination. This failure stems from their reliance on ungrounded, text-based Chain-of-Thought (CoT) reasoning.While existing multi-modal CoT approaches attempt mitigation, they suffer from two fundamental flaws: (1) decoupled perception and reasoning stages that prevent end-to-end joint optimization, and (2) reliance on expensive, dense localization labels.Thus we introduce OmniDrive-R1, an end-to-end VLM framework designed for autonomous driving, which unifies perception and reasoning through an interleaved Multi-modal Chain-of-Thought (iMCoT) mechanism. Our core innovation is an Reinforcement-driven visual grounding capability, enabling the model to autonomously direct its attention and "zoom in" on critical regions for fine-grained analysis. This capability is enabled by our pure two-stage reinforcement learning training pipeline and Clip-GRPO algorithm. Crucially, Clip-GRPO introduces an annotation-free, process-based grounding reward. This reward not only eliminates the need for dense labels but also circumvents the instability of external tool calls by enforcing real-time cross-modal consistency between the visual focus and the textual reasoning. Extensive experiments on DriveLMM-o1 demonstrate our model's significant improvements. Compared to the baseline Qwen2.5VL-7B, OmniDrive-R1 improves the overall reasoning score from 51.77% to 80.35%, and the final answer accuracy from 37.81% to 73.62%.
Deep Learning Enabled Semantic Communication Systems for Video Transmission
Dec 08, 2023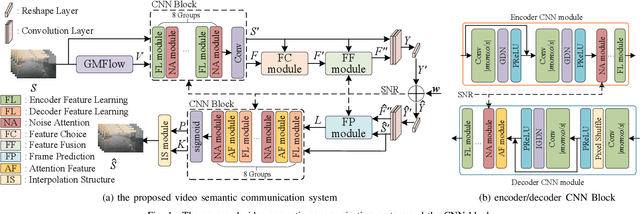

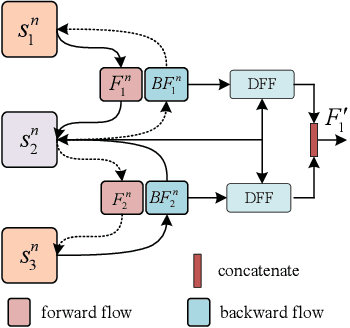
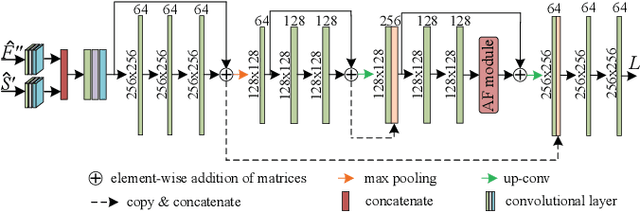
Semantic communication has emerged as a promising approach for improving efficient transmission in the next generation of wireless networks. Inspired by the success of semantic communication in different areas, we aim to provide a new semantic communication scheme from the semantic level. In this paper, we propose a novel DL-based semantic communication system for video transmission, which compacts semantic-related information to improve transmission efficiency. In particular, we utilize the Bi-optical flow to estimate residual information of inter-frame details. We also propose a feature choice module and a feature fusion module to drop semantically redundant features while paying more attention to the important semantic-related content. We employ a frame prediction module to reconstruct semantic features of the prediction frame from the received signal at the receiver. To enhance the system's robustness, we propose a noise attention module that assigns different importance weights to the extracted features. Simulation results indicate that our proposed method outperforms existing approaches in terms of transmission efficiency, achieving about 33.3\% reduction in the number of transmitted symbols while improving the peak signal-to-noise ratio (PSNR) performance by an average of 0.56dB.
KETM:A Knowledge-Enhanced Text Matching method
Aug 11, 2023Text matching is the task of matching two texts and determining the relationship between them, which has extensive applications in natural language processing tasks such as reading comprehension, and Question-Answering systems. The mainstream approach is to compute text representations or to interact with the text through attention mechanism, which is effective in text matching tasks. However, the performance of these models is insufficient for texts that require commonsense knowledge-based reasoning. To this end, in this paper, We introduce a new model for text matching called the Knowledge Enhanced Text Matching model (KETM), to enrich contextual representations with real-world common-sense knowledge from external knowledge sources to enhance our model understanding and reasoning. First, we use Wiktionary to retrieve the text word definitions as our external knowledge. Secondly, we feed text and knowledge to the text matching module to extract their feature vectors. The text matching module is used as an interaction module by integrating the encoder layer, the co-attention layer, and the aggregation layer. Specifically, the interaction process is iterated several times to obtain in-depth interaction information and extract the feature vectors of text and knowledge by multi-angle pooling. Then, we fuse text and knowledge using a gating mechanism to learn the ratio of text and knowledge fusion by a neural network that prevents noise generated by knowledge. After that, experimental validation on four datasets are carried out, and the experimental results show that our proposed model performs well on all four datasets, and the performance of our method is improved compared to the base model without adding external knowledge, which validates the effectiveness of our proposed method. The code is available at https://github.com/1094701018/KETM
DEIM: An effective deep encoding and interaction model for sentence matching
Mar 20, 2022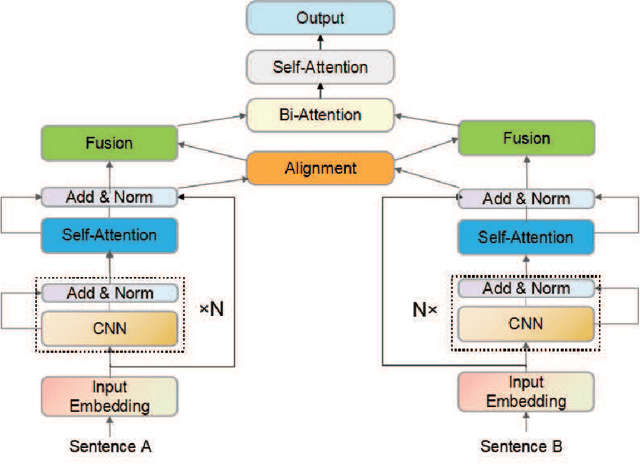
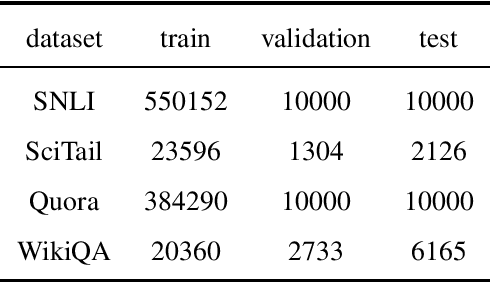


Natural language sentence matching is the task of comparing two sentences and identifying the relationship between them.It has a wide range of applications in natural language processing tasks such as reading comprehension, question and answer systems. The main approach is to compute the interaction between text representations and sentence pairs through an attention mechanism, which can extract the semantic information between sentence pairs well. However,this kind of method can not gain satisfactory results when dealing with complex semantic features. To solve this problem, we propose a sentence matching method based on deep encoding and interaction to extract deep semantic information. In the encoder layer,we refer to the information of another sentence in the process of encoding a single sentence, and later use a heuristic algorithm to fuse the information. In the interaction layer, we use a bidirectional attention mechanism and a self-attention mechanism to obtain deep semantic information.Finally, we perform a pooling operation and input it to the MLP for classification. we evaluate our model on three tasks: recognizing textual entailment, paraphrase recognition, and answer selection. We conducted experiments on the SNLI and SciTail datasets for the recognizing textual entailment task, the Quora dataset for the paraphrase recognition task, and the WikiQA dataset for the answer selection task. The experimental results show that the proposed algorithm can effectively extract deep semantic features that verify the effectiveness of the algorithm on sentence matching tasks.
Wireless Transmission of Images With The Assistance of Multi-level Semantic Information
Feb 08, 2022



Semantic-oriented communication has been considered as a promising to boost the bandwidth efficiency by only transmitting the semantics of the data. In this paper, we propose a multi-level semantic aware communication system for wireless image transmission, named MLSC-image, which is based on the deep learning techniques and trained in an end to end manner. In particular, the proposed model includes a multilevel semantic feature extractor, that extracts both the highlevel semantic information, such as the text semantics and the segmentation semantics, and the low-level semantic information, such as local spatial details of the images. We employ a pretrained image caption to capture the text semantics and a pretrained image segmentation model to obtain the segmentation semantics. These high-level and low-level semantic features are then combined and encoded by a joint semantic and channel encoder into symbols to transmit over the physical channel. The numerical results validate the effectiveness and efficiency of the proposed semantic communication system, especially under the limited bandwidth condition, which indicates the advantages of the high-level semantics in the compression of images.
DTWSSE: Data Augmentation with a Siamese Encoder for Time Series
Aug 23, 2021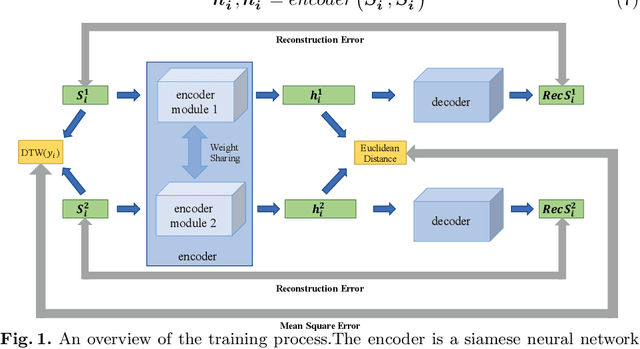
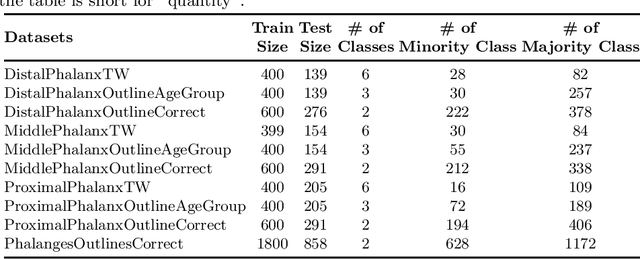
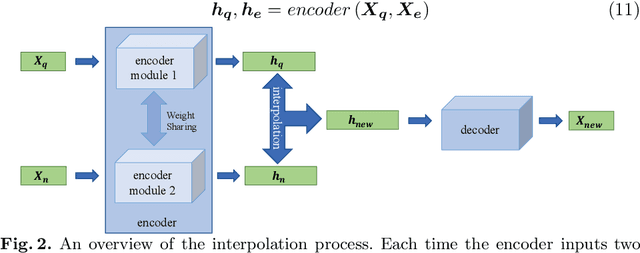

Access to labeled time series data is often limited in the real world, which constrains the performance of deep learning models in the field of time series analysis. Data augmentation is an effective way to solve the problem of small sample size and imbalance in time series datasets. The two key factors of data augmentation are the distance metric and the choice of interpolation method. SMOTE does not perform well on time series data because it uses a Euclidean distance metric and interpolates directly on the object. Therefore, we propose a DTW-based synthetic minority oversampling technique using siamese encoder for interpolation named DTWSSE. In order to reasonably measure the distance of the time series, DTW, which has been verified to be an effective method forts, is employed as the distance metric. To adapt the DTW metric, we use an autoencoder trained in an unsupervised self-training manner for interpolation. The encoder is a Siamese Neural Network for mapping the time series data from the DTW hidden space to the Euclidean deep feature space, and the decoder is used to map the deep feature space back to the DTW hidden space. We validate the proposed methods on a number of different balanced or unbalanced time series datasets. Experimental results show that the proposed method can lead to better performance of the downstream deep learning model.