 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Iterative Labeling Method for Annotating Fisheries Imagery
Paper and Code
Apr 27, 2022


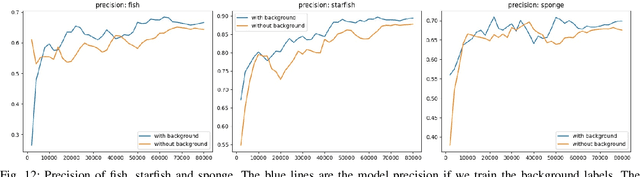
In this paper, we present a methodology for fisheries-related data that allows us to converge on a labeled image dataset by iterating over the dataset with multiple training and production loops that can exploit crowdsourcing interfaces. We present our algorithm and its results on two separate sets of image data collected using the Seabed autonomous underwater vehicle. The first dataset comprises of 2,026 completely unlabeled images, while the second consists of 21,968 images that were point annotated by experts. Our results indicate that training with a small subset and iterating on that to build a larger set of labeled data allows us to converge to a fully annotated dataset with a small number of iterations. Even in the case of a dataset labeled by experts, a single iteration of the methodology improves the labels by discovering additional complicated examples of labels associated with fish that overlap, are very small, or obscured by the contrast limitations associated with underwater imagery.