 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Trust Tools? Adaptive Tool Trust Calibration For Tool-Integrated Math Reasoning
Apr 09, 2026Large reasoning models (LRMs) have achieved strong performance enhancement through scaling test time computation, but due to the inherent limitations of the underlying language models, they still have shortcomings in tasks that require precise computation and extensive knowledge reserves. Tool-Integrated Reasoning (TIR) has emerged as a promising paradigm that incorporates tool call and execution within the reasoning trajectory. Although recent works have released some powerful open-source TIR models, our analysis reveals that these models still suffer from critical deficiencies. We find that when the reasoning of the model conflicts with the tool results, the model tends to believe in its own reasoning. And there are cases where the tool results are correct but are ignored by the model, resulting in incorrect answers, which we define as "Tool Ignored''. This indicates that the model does not know when to trust or ignore the tool. To overcome these limitations, We introduce Adaptive Tool Trust Calibration (ATTC), a novel framework that guides the model to adaptively choose to trust or ignore the tool results based on the confidence score of generated code blocks. The experimental results from various open-source TIR models of different sizes and across multiple datasets demonstrate that ATTC effectively reduces the "Tool Ignored" issue, resulting in a performance increase of 4.1% to 7.5%.
When Is Thinking Enough? Early Exit via Sufficiency Assessment for Efficient Reasoning
Apr 08, 2026Large reasoning models (LRMs) have achieved remarkable performance in complex reasoning tasks, driven by their powerful inference-time scaling capability. However, LRMs often suffer from overthinking, which results in substantial computational redundancy and significantly reduces efficiency. Early-exit methods aim to mitigate this issue by terminating reasoning once sufficient evidence has been generated, yet existing approaches mostly rely on handcrafted or empirical indicators that are unreliable and impractical. In this work, we introduce Dynamic Thought Sufficiency in Reasoning (DTSR), a novel framework for efficient reasoning that enables the model to dynamically assess the sufficiency of its chain-of-thought (CoT) and determine the optimal point for early exit. Inspired by human metacognition, DTSR operates in two stages: (1) Reflection Signal Monitoring, which identifies reflection signals as potential cues for early exit, and (2) Thought Sufficiency Check, which evaluates whether the current CoT is sufficient to derive the final answer. Experimental results on the Qwen3 models show that DTSR reduces reasoning length by 28.9%-34.9% with minimal performance loss, effectively mitigating overthinking. We further discuss overconfidence in LRMs and self-evaluation paradigms, providing valuable insights for early-exit reasoning.
Reinforced Diffusion: Learning to Push the Limits of Anisotropic Diffusion for Image Denoising
Dec 30, 2025Image denoising is an important problem in low-level vision and serves as a critical module for many image recovery tasks. Anisotropic diffusion is a wide family of image denoising approaches with promising performance. However, traditional anisotropic diffusion approaches use explicit diffusion operators which are not well adapted to complex image structures. As a result, their performance is limited compared to recent learning-based approaches. In this work, we describe a trainable anisotropic diffusion framework based on reinforcement learning. By modeling the denoising process as a series of naive diffusion actions with order learned by deep Q-learning, we propose an effective diffusion-based image denoiser. The diffusion actions selected by deep Q-learning at different iterations indeed composite a stochastic anisotropic diffusion process with strong adaptivity to different image structures, which enjoys improvement over the traditional ones. The proposed denoiser is applied to removing three types of often-seen noise. The experiments show that it outperforms existing diffusion-based methods and competes with the representative deep CNN-based methods.
Discrete Prior-based Temporal-coherent Content Prediction for Blind Face Video Restoration
Jan 17, 2025



Blind face video restoration aims to restore high-fidelity details from videos subjected to complex and unknown degradations. This task poses a significant challenge of managing temporal heterogeneity while at the same time maintaining stable face attributes. In this paper, we introduce a Discrete Prior-based Temporal-Coherent content prediction transformer to address the challenge, and our model is referred to as DP-TempCoh. Specifically, we incorporate a spatial-temporal-aware content prediction module to synthesize high-quality content from discrete visual priors, conditioned on degraded video tokens. To further enhance the temporal coherence of the predicted content, a motion statistics modulation module is designed to adjust the content, based on discrete motion priors in terms of cross-frame mean and variance. As a result, the statistics of the predicted content can match with that of real videos over time. By performing extensive experiments, we verify the effectiveness of the design elements and demonstrate the superior performance of our DP-TempCoh in both synthetically and naturally degraded video restoration.
Image Cartoon-Texture Decomposition Using Isotropic Patch Recurrence
Nov 10, 2018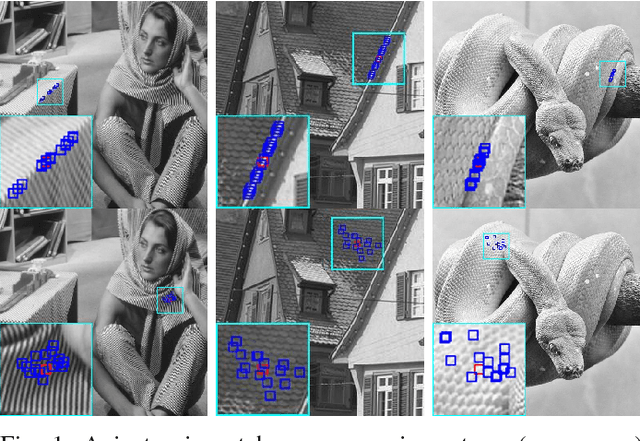
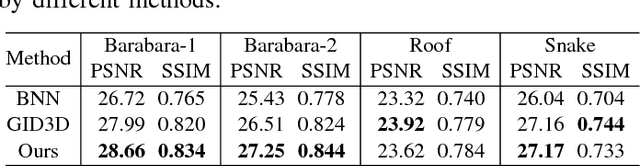
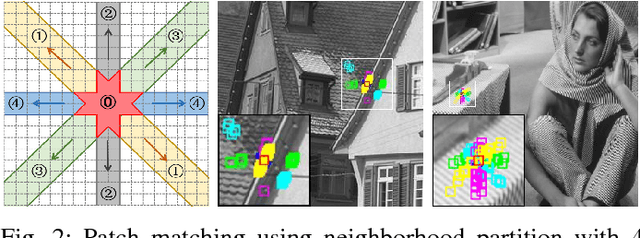

Aiming at separating the cartoon and texture layers from an image, cartoon-texture decomposition approaches resort to image priors to model cartoon and texture respectively. In recent years, patch recurrence has emerged as a powerful prior for image recovery. However, the existing strategies of using patch recurrence are ineffective to cartoon-texture decomposition, as both cartoon contours and texture patterns exhibit strong patch recurrence in images. To address this issue, we introduce the isotropy prior of patch recurrence, that the spatial configuration of similar patches in texture exhibits the isotropic structure which is different from that in cartoon, to model the texture component. Based on the isotropic patch recurrence, we construct a nonlocal sparsification system which can effectively distinguish well-patterned features from contour edges. Incorporating the constructed nonlocal system into morphology component analysis, we develop an effective method to both noiseless and noisy cartoon-texture decomposition. The experimental results have demonstrated the superior performance of the proposed method to the existing ones, as well as the effectiveness of the isotropic patch recurrence prior.